本篇文章我们梳理一下hive常用的函数,对于hive而言,常用的函数并不是特别多,往往记住关键几个,就可以解决80%的问题,这也是大家喜欢hive的原因,那么,常用的函数有哪些呢?
时间函数


1)时间格式转化
常用的日期格式主要有两个:时间戳和日期格式,时间戳便于计算,日期格式便于阅读,两者各有利弊,所以需要相互转换,转换的对应函数主要有:
from_unixtime(timestamp,dateformat):将时间戳转化为日期格式,格式必须是10位,毫秒级的时间戳需要用cast转化成秒级。unix_timestamp(date,dateformat):日期格式转化为时间戳,如果括号内没有参数则表示返回当前的时间戳。例如:
时间戳转日期格式:
select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as date_time, from_unixtime(1537924406,'yyyy-MM-dd') as date_time1from dual;如果时间戳是毫秒级,则字段修改为:
from_unixtime(cast(unix_timestamp()/1000 as int),'yyyy-MM-dd HH:mm:ss') as date_time日期格式转时间戳:
select unix_timestamp() as time_stamp, --返回当前时间戳; unix_timestamp('2018-09-26 9:13:26','yyyy-MM-ddHH:mm:ss') as time_stamp1from dual;作为一个数据,在不同系统之间游走,有没有经常遇到时间格式不匹配的情况,所以需要做格式的转化:
date_format(string/date,dateformate):把字符串或者日期转成指定格式的日期。日期格式调整:
select date_format('2018-09-12','yyyy-MM-dd HH:mm:ss') as date_time, date_format('2018-09-12','yyyyMMdd') as date_time1from dual;--2018-09-12 00:00:00有没有发现一个问题,date_format只能从yyyy-MM-dd格式转化成其他格式,对于其他类型,例如:yyyyMMdd,则不能处理,所以需要灵活一点,将各个格式的时间转化成时间戳,再通过时间戳转化成其他格式:
select from_unixtime(unix_timestamp(substr('20191007000000',1,8),'yyyyMMdd'),'yyyy-MM-dd');如此一来,各种格式都可以转化。
2)日期的加减差运算:
日期的加减是对日期格式数据的基本运算,常用的是时间差计算、加一天、减一天等。
时间差计算:
datediff(date,date1);日期差,即两个日期差几天。months_between(date,date1);两个日期差几个月,用法一致。select datediff('2015-05-22','2015-05-29') as date_ff; --[-7]在原日期上加n天:
date_add:在现在日期上增加天数,
add_months是增加月份,用法一致。
select date_add('2015-05-22 15:34:23',2); --2015-05-24在原日期上减n天:
date_sub:在现在日期上减少天数。
select date_sub('2015-05-22 15:34:23',2); --2015-05-203)时间截取:
如果我们获取到一个完整的时间,但是只想用其中的一部分,势必牵扯到时间截取的功能,常见的时间截取主要是如下几个函数:
to_date:获取完整时间中的日期部分:
select to_date('2015-06-01 15:34:23'); --2015-06-01year:获取完整时间中的年份:
select year('2015-05-22 15:34:23'); --2015month:获取完整时间中的月份:
select month('2015-05-22 15:34:23'); --5day:获取完整时间中的日期:
select day('2015-05-22 15:34:23'); --224)日期中其他灵活操作:
日期除了计算多少天,截取某一段,还会牵扯一些比较灵活的操作方法,例如:判断当天是周几,判断年周、月周,当月的最后一天和第一天,下n天,上n天等。
获取一年中的第几周:weekofyear:
select weekofyear('2015-05-22 15:34:23'); --21获取当月中的第几周:
select weekofyear('2015-05-22')-weekofyear(trunc('2015-05-22', ‘MM’))+1;这其中有一个有意思的点:每一周是按照周一到周日为一个完整周,与英美的周日到周六的逻辑有些不一样,所以在如下日历中:

11月1日为周日,按照代码中的逻辑与10月31日是一周。
判断当天为周几:
Select 8-datediff(next_day(‘2020-12-20’, ‘MO’), ‘2020-12-20’) as week;获取月末最后一天:
last_day(date):
select last_day('2018-09-30') as date_time, last_day('2018-09-27 21:16:13') as date_time1from dual;--2018-09-30获取月初、年初:
trunc(date,format)
format:MONTH/MON/MM, YEAR/YYYY/YY
select trunc('2018-09-27','YY') as date_time,--返回年初 trunc('2018-09-27 21:16:13','MM') as date_time1 --返回月初from dual;--2018-01-01和2018-09-01当前日期下个星期X的日期:
next_day(date,formate) format:英文星期几的缩写或者全拼。
select next_day('2018-09-27','TH') as date_time, next_day('2018-09-27 21:16:13','TU') as date_time1from dual;--2018-10-04和2018-10-02汇总SQL为(下文SQL为对应的日期写法,可以作为上面简单罗列的补充版):
select day -- 时间 ,date_add(day,1 - dayofweek(day)) as week_first_day -- 本周第一天_周日 ,date_add(day,7 - dayofweek(day)) as week_last_day -- 本周最后一天_周六 ,date_add(day,1 - case when dayofweek(day) = 1 then 7 else dayofweek(day) - 1 end) as week_first_day -- 本周第一天_周一 ,date_add(day,7 - case when dayofweek(day) = 1 then 7 else dayofweek(day) - 1 end) as week_last_day -- 本周最后一天_周日 ,next_day(day,'TU') as next_tuesday -- 当前日期的下个周二 ,trunc(day,'MM') as month_first_day -- 当月第一天 ,last_day(day) as month_last_day -- 当月最后一天 ,to_date(concat(year(day),'-',lpad(ceil(month(day)/3) * 3 -2,2,0),'-01')) as season_first_day -- 当季第一天 ,last_day(to_date(concat(year(day),'-',lpad(ceil(month(day)/3) * 3,2,0),'-01'))) as season_last_day -- 当季最后一天 ,trunc(day,'YY') as year_first_day -- 当年第一天 ,last_day(add_months(trunc(day,'YY'),12)) as year_last_day -- 当年最后一天 ,weekofyear(day) as weekofyear -- 当年第几周 ,second(day) as second -- 秒钟 ,minute(day) as minute -- 分钟 ,hour(day) as hour -- 小时 ,day(day) as day -- 日期 ,month(day) as month -- 月份 ,lpad(ceil(month(day)/3),2,0) as season -- 季度 ,year(day) as year -- 年份from ( select '2018-01-02 01:01:01' as day union all select '2018-02-02 02:03:04' as day union all select '2018-03-02 03:05:07' as day union all select '2018-04-02 04:07:10' as day union all select '2018-05-02 05:09:13' as day union all select '2018-06-02 06:11:16' as day union all select '2018-07-02 07:13:19' as day union all select '2018-08-02 08:15:22' as day union all select '2018-09-02 09:17:25' as day union all select '2018-10-02 10:19:28' as day union all select '2018-11-02 11:21:31' as day union all select '2018-12-02 12:23:34' as day) t1;数据运算总结
Hive中数据一般是可以用常规的运算符号表示的,例如:“加减乘除”用“+-*/”表示,但是对于初次之外的运算需要用到对应的函数:
sum():求和;count():求数据量;avg():求平均值;distinct:求不同值数(去重);min:求最小值;max:求最大值;pmod(int a, int b):返回a除以b的余数的绝对值;round:四舍五入 select round(数值,小数点位数);ceil:向上取整 select ceil(45.6); floor:向下取整 select floor(45.6);在数据运算过程中经常会遇到用字符串形式存储的数值,计算过程中需要将其转化成数值型,然后进行运算,其中运算方法为:
cast(aaa as int):将string转化成int;cast(aaa as decimal(10, 2)):将string转化成float,保留两位小数;当然也可以将数值转化成字符串:
cast(aaa as string):将int转化成string;除了上面这些方法外,hive在数据运算方面还有大于、小于、等于等操作,这些操作都有对应的运算符号表示,在此就不多描述了。
字符串操作总结
字符串可以说是最常用的处理思路,在特征处理、数据清洗过程中高频使用,这些函数用的好会为接下来数据建模、统计运算带来极大便利。下面我们来梳理一下常用的字符串处理方法:
1)空格处理:
trim(String A):去除A两侧的空格;ltrim(String A):去除左边空格;rtrim(String A):去除右边空格select trim('abc') from lxw_dual;2)单个字符串操作:
reverse('abcde')=edcba:字符串反转lower:转成小写
select lower('Hive'); --hiveupper:转成大写
select lower('Hive'); --HIVElength:长度
select length('Hive'); --4 substr:求子串
select substr('hive',2); --iveselect substr('hive',2,1); --ilpad:左填充
对hive填充到10位,补位用#
select lpad('hive',10,'#'); --######hiverpad:右填充
select rpad('hive',10,'#'); --hive######regexp_extract():正则表达式处理
regexp_extract(string subject, string pattern, int index); --函数的应用;将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符:
select clientcode, regexp_extract(filterlist,'(filtertype"\\:")(\\d+)(",)',2) as filtertypefrom tmp_action_click在正则表达式中,经常会用到贪心算法(.*?)和非贪心算法(.*)用法,用来清洗字符串中的内容。
正则表达式替换函数:
regexp_replace('foobar','oo|ar','')=fb #替换oo|ar为空字符有意思的是,hive中并没有直接的replace函数,如果是整个字符串的判断可以用case when的方式操作,如果只替换其中一部分可以用regexp_replace操作。
get_json_object(string json_string,string path)该函数的第一个参数是json对象变量,第二个参数使用$表示json变量标识,然后用.或[]读取对象或数组。
例如:
如果json为:
Json={"store":{"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }对应的SQL为:
SELECT get_json_object(json, '$.owner') FROM src_json;--amySELECT get_json_object(json, '$.store.fruit\[0]') FROM src_json;--{"weight":8,"type":"apple"}SELECT get_json_object(json, '$.non_exist_key') FROM src_json;--NULL第二个常用的函数为:
json_tuple(string json_string,string k1,string k2...)该函数的第一个参数是json对象变量,之后的参数是不定长参数,是一组键k1,k2...,返回值是元组,该方法比get_json_object高效,因为可以在一次调用中输入多个键值。
select src.timestamp, b.*from src_json srclateral view json_tuple(src.json, 'email', 'owner') b as f1, f2;另外,单个字符串如果是url,可以直接使用pares_url函数,个人感觉这个函数比较鸡肋,看起来很有用,但是大部分功能可以用string拼接的方式搞定。
URL解析函数:parse_url
语法:
parse_url(string urlString, string partToExtract [, stringkeyToExtract])返回值: string
说明:返回URL中指定的部分。
partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
举例:
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') from lxw_dual;--facebook.comselect parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k1')from lxw_dual--v1应用过程中还有一个k-v值的函数:
str_to_map(String text,String delimiter1,String delimiter2)使用两个分隔符将文本拆分成键值对。Delimiter1将文本分成k-v对,Delimiter2分割每个k-v对。对于delimiter1的默认值是',',delimiter2的默认值是'='。
select str_to_map('abc:11&bcd:22', '&', ':')--[“abc”:“11”, “bcd”:“22”]3)多字符串操作:
concat():字符串拼接
concat('aa','bb','cc')=aabbccconcat_ws(sep,str1,str2,...):根据固定的分隔符连接后侧字符串;
concat_ws第一个参数是其它参数的分隔符,分隔符的位置放在要连接的两个字符串之间,分隔符可以是一个字符串,也可以是其他参数。
Select concat_ws(',','11','22','33'); --11,22,33split(str,regex):数据切分。
该函数第一个参数是字符串,第二个参数是设定的分隔符,通过第二个参数把第一个参数做拆分,返回一个数组:
select split('123,3455,2568',',')--[“123”,”123”,”123”]字段的数据处理
特征处理过程中也会经常遇到条件处理,例如:是否为空、满足什么条件、排序等,我们简单做一下了解:
1)是否为空的判断:
select nvl(T v1, T default_value);-- 如果v1不为null返回v1,否则default Value。select nvl(null,0);select coalesce(T v1, T v2, T v3, ...);--返回第一个不为null的value值。select COALESCE(null,'aaa',50)from default.dual limit 1;--aaaselect COALESCE(1,'aaa',50)from default.dual limit 1;--12)条件判断:
select if(boolean testCondition, T valueTrue, T valueFalseOrNull);select if(1=1,'bbbb',111);--if条件判断表达式。3)row_number()函数:分组排序的功能。
row_number() over(distribute by col1 sort by clo2 desc)字段的行列变化
Hive中比较有特色的功能是行列变化,可以实现多行变一行,也可以实现一行变多行,但是其中有个缺陷,就是多行变多列无法实现,会用python的同学可以通过pyspark实现对应的变化:
1)多行变一行:
collect_list/collect_set列转行函数。
我们看对应的表结构为:
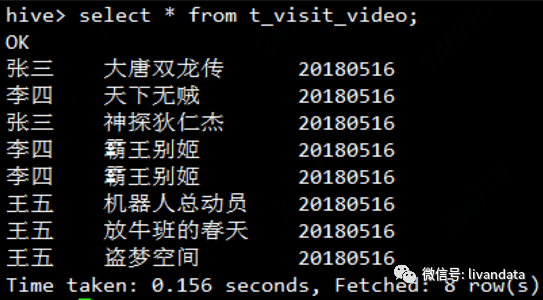
使用collect_list之后为:

仔细看发现“李四”看了两遍“霸王别姬”,需要去重,因此,使用collect_set函数:

这一功能的一个最大好处是突破了group by的限制,分组之后如果另一个字段有多个值且不在分组字段中,则需要用collect_set/collect_list函数。

以上为多行转一行,如何将一行转多行呢?
2)一行转多行:
我们有explode()和lateral view()函数:
explode():
该函数接收一个参数,参数类型需是array或者map类型,该函数的输出是把输入参数的每个元素拆成独立的一行记录。
select explode(split('123,3455,2568',','))这个函数的一个问题在于无法将list/set等格式做转化,如果要做转化则需要将list/set转化成string,然后再用explode/split切分形成多行。
lateral view():
Lateral View 一般与用户自定义表生成函数(如explode())结合使用。UDTF为每个输入行生成零个或多个输出行,Lateral view首先将UDTF应用于基表的每一行,然后将结果输出行连接到输入行,已形成具有提供的表别名的虚拟表。
例如:
select items_page, numfrom data_limitlateral view explode(items_pages) good as items_page其中:
a)explode是将items_pages行变列;
b)good是虚拟表,用来存储explode之后的数据,并定义列名为items_page;
c)lateral view是将items_page与上面的字段num进行笛卡尔积,呈现出多列表示;
跳开hive,我们可以通过pyspark实现多行变多列,如下:
data=spark.createDataFrame([[1,[2,9],3],[4,[5,6],6],[7,[8,0],9]],['a','b','c'])Length = len(data.select(‘b’).take(1)[0][0])data_t=data.select([data.b]+[data.b[i] for i in range(length)]).show()Print(data_t)结果为:

如上即为hive的一些常用函数,笔者做了简单汇总,希望对大家有所助益。
欢迎大家关注公众号: 来都来了,点个关注再走呗~
来都来了,点个关注再走呗~