RMQ 算法原理(图示)
概念
RMQ算法是专门用来求区间最值问题的,利用了倍增的思想实现的,也属于动态规划问题
我们先来看看用纯区间dp怎么写这道题
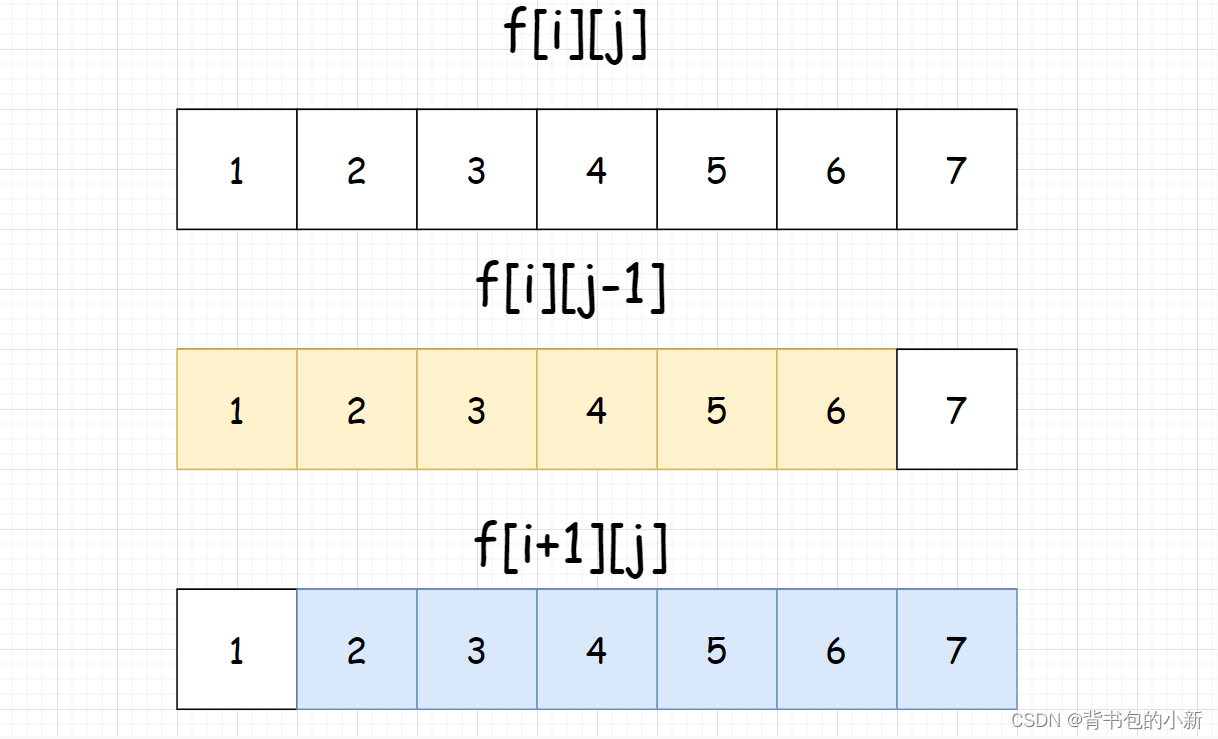
基本思路:枚举所有的左端点和后端点,记录所有区间的最大值,用f[i][j]来表示从i到j区间内的最大值
状态表示:f[i][j]表示从i到j的区间中最大值是多少
状态转移:如何计算f[i][j]?,考虑当前这一状态可以由什么状态转变而来,对于本题中,求得是i到j区间中得最大值,那么最后一个加入区间得值可能是i,也可能是j,所以
- 选
i:f[i][j] = f[i + 1][j] - 选
j:f[i][j] = f[i][j-1]
这两个去一个最大值就是f[i][j]的最大值
状态转移方程: f[i][j] = max(f[i][j - 1], f[i + 1][j])
核心代码
for (int len = 1; len <= n; len++) // 先枚举所有的长度
{
for (int i = 1; i + len - 1 <= n; i++) // 枚举所有的左端点
{
int j = i + len - 1; // 右端点
if (i == j)
f[i][j] = w[i];
else
f[i][j] = max(f[i][j - 1], f[j-1][j]);
}
}
但是这样写复杂度是O(n^2),复杂度太高,而这题数据范围这样写明显会超时,我们想想能够怎么优化使它不超时呢?
答案是利用倍增的思想O(nlogn)
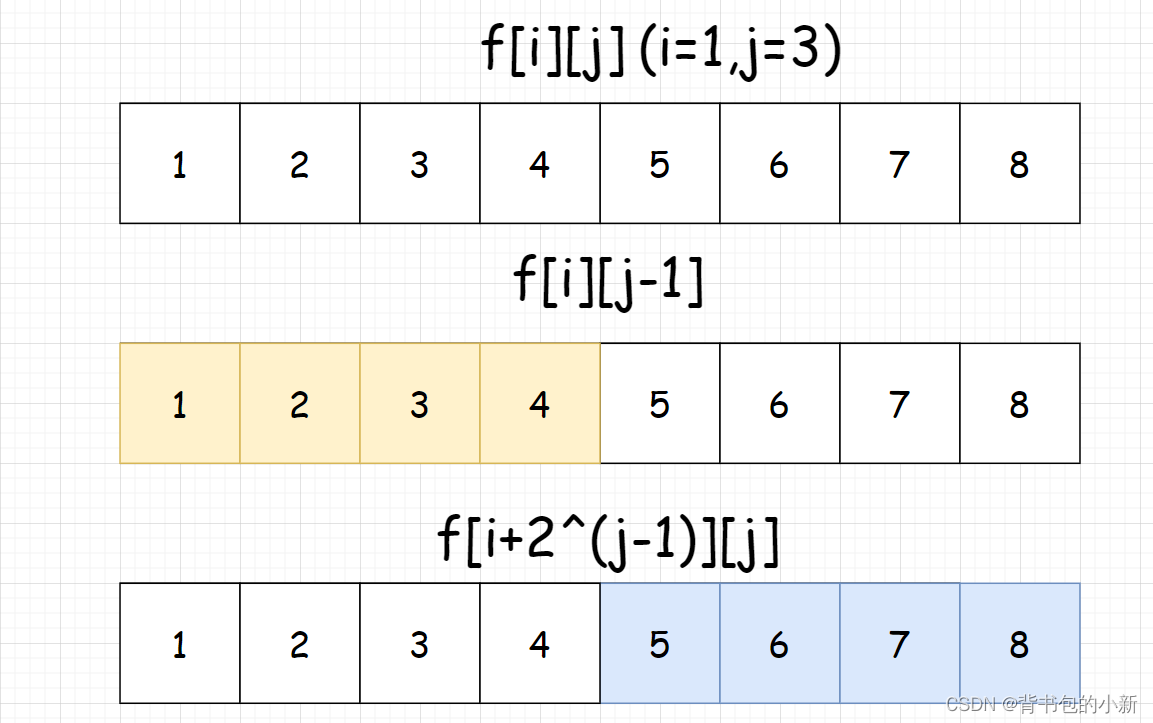
状态表示:f[i][j]表示从i开始,长度使2^j的区间中最大值是多少
状态转移:如何计算f[i][j]? 在这里就不能按照上面的状态转移了,因为这里所有的区间长度都是2的整数次幂,没法按照最后一个点在左端点还是右端点来区分,因为这里所有的整数区间都是2的整数次幂,我们可以将整个区间一分为二,分别计算出坐半区间的最大值和右半区间的最大值取max就是最终答案
- 选左半区间 :
f[i][j] = f[i][j - 1] - 选右半区间:
f[i][j] = f[i + 2^(j - 1)][j - 1]
状态转移方程: f[i][j] = max(f[i][j - 1], f[i + (1 << j - 1)][j - 1])
核心代码
for (int j = 0; j < M; j++) // 枚举所有长度为2的倍数的区间
{
for (int i = 1; i + (1 << j) - 1 <= n; i++) // 枚举所有左端点
{
if (!j)
f[i][j] = w[i];
else
f[i][j] = max(f[i][j - 1], f[i + (1 << (j - 1))][j - 1]);
}
}
现在还有一个问题未解决,当我们要询问任意的一个区间的最大值是多少的时候,我们怎么由f[i][j]来得到呢?
现在要区间查询的长度不再是2的整数次幂了,无法单纯的从f数组里面得到答案了。那么我们怎么办呢?
其实和上面的状态转移方程思路一样,我们可以将这个区间分为两个长度相同并且都是2的整数次幂的区间就行了,那么怎么分呢?
假设区间的长度为len,左区间的长度为2^k,那么为了使一个区间能够分成两个区间长度为2的整数次幂的区间,必须使 len / 2 <= 2^k <= len,那么可以选k的最大值 k = (int)log2(len)
但在c++里的<cmath>库中只有log10,所以还需要利用换底公式转换一下log2(len) = log10(len) / log10(2),这样我们就得到了两个区间,就能计算最大值了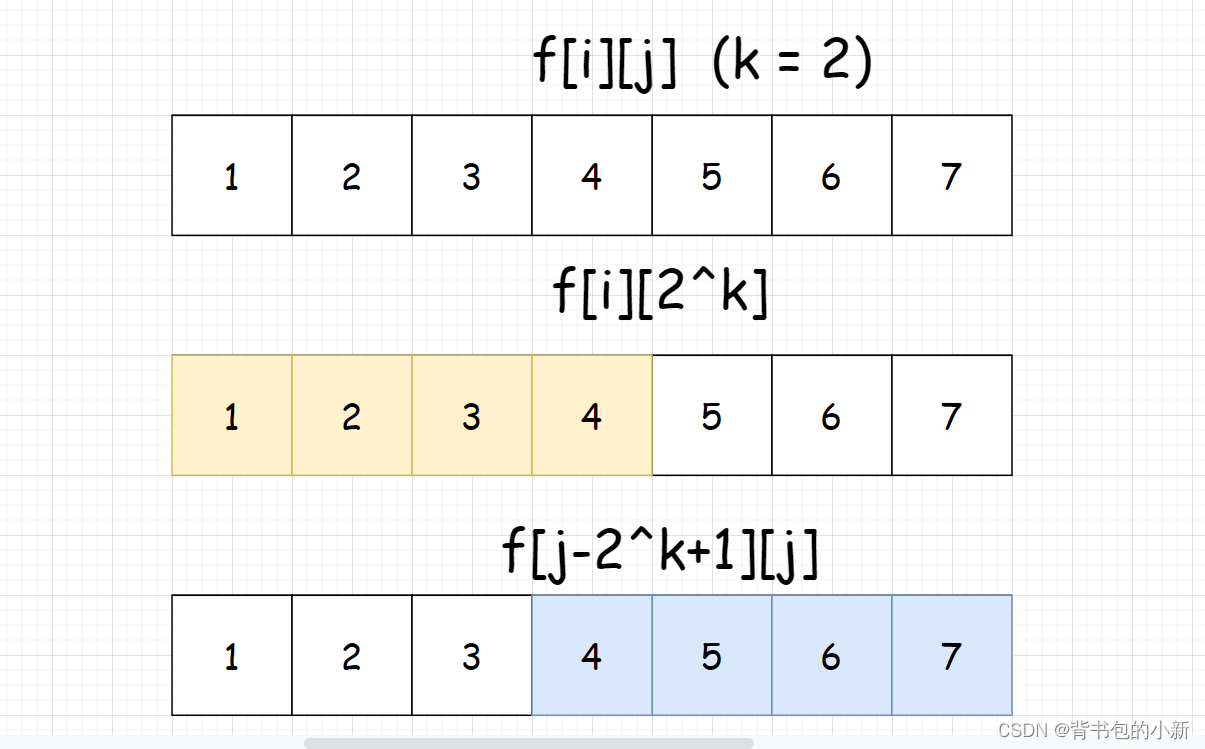
核心代码
int query(int l, int r)
{
int len = r - l + 1;
int k = log(len) / log(2);
return max(f[l][k], f[r - (1 << k) + 1][k]);
}
好了,关于RMQ算法就已经讲完了,我们来写道题吧
天才的记忆,相信你一定能够AC!!!