第 5 章 创建自定义的新闻源
帮助 你找到想要阅读的所有文章,同时让你避免在大量不感兴趣的内容上浪费时间,将学会如何构建一个能理解你对新闻喜好的系统,并每天向你发送一个私人定制的新闻通讯。
Pocket应用程序创建监督训练的集合。
训练的数据这些训练数据将被输入到我们的模型中,以教导该模型区分我们感兴趣的和不感兴趣的文章。为了构建 这个语料库,我们需要标注大量与这些兴趣相关的文章。对于每篇文章,我们将其标记为 “y”或“n”。这将指示该文章是否应该出现在发送给我们的每日摘要中。
为了简化这个过程,我们将使用 Pocket 应用程序
监督学习最终结果的好坏
取决于你的训练集,所以你需要标记数百篇文章来获得好的效果。如果在保存某篇文章
时你忘记给它打标签了,
我们将使用Pocket API。你可以在https://getpocket.com/developer/apps/new
注册一个新账户
我注册没反应,-_-||
书上说注册成功可以获取API密钥,所有下面
我不行了。。
embed.ly API
来提取故事主体。
https://app.embed.ly/signup 这个还是打不开。
自然语言处理
将文本转换成数值
自然语言处理(NLP)
•The new kitten played with the other kittens
•She ate lunch
•She loved her kitten
将语料库转换为词袋(BOW)的表示常见的英语停用词的示例是“the”、“is”、“at”、“which”和“on”。我们 将删除这些词并重新计算词条-文档矩阵数据的过滤器,以提升对于每个文档
而言更为特殊的单词。该算法称为词频-逆文档频率或 tf-idf。
包括获取每个单词及其数量,来创建词条-文档的矩阵。在词条-文档的矩阵中,每个唯一的单词对应于一列,而每个文档对应于一行。两者的交点是这个单词在该文档中出现的次数,删除对分析几乎没有价值的特征
•支持向量机。
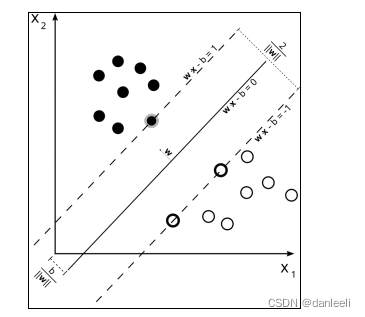
线性支持向量机。支持向量机的算法使用“最
大边缘超平面”,试图对数据点进行线性分离并归类。
假设有两类数据,而我们想用一条线来分隔它们(这里只处理两个特征或维度)
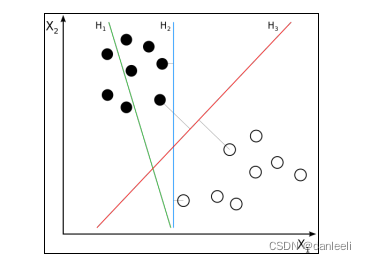
线 H1 不能有效地区分两个类,所以我们可以不考虑这条。线 H2能够清
楚地区分它们,但是 H3 确保了最大的空余边缘。这意味着该线在两个类间最近点的当中,
而这些点被称为支持向量。它们也可以看作是图中的虚线。前面不能清晰分类。
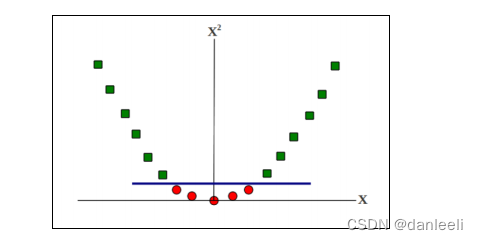
使用softmargin SVM。这个公式仍然使边缘最
大化,但是有一个权衡的策略:如果点错误地落在边缘的某一侧,那么对这样的点进行惩
罚。另一种是使用所谓的 kernel 技巧。这种方法将数据转换到更高维度的空间,让这些数
据可以被线性的分割。
fromsklearn.svm import LinearSVC
clf = LinearSVC()
model = clf.fit(tv, df['wanted'])
这个 tv 参数是我们的矩阵,而 df [‘wanted’]是我们的标签列表。记住标签是’y’或’n’,表
示我们是否对文章感兴趣。一旦运行完成,模型就训练完毕了。
IFTTT 与 RSS 源以及 Google 表单的集成。
要申请IFTTT 账号,
我注册又出问题了,点击没反应
让新闻故事在表单中累积一两天,Google Drive表单。
从信息源中下载了所有的文章,并将它们放入了 DataFrame 对象
建立每日的个性化新闻通讯。