1,spark 初识
1.1,spark 与 hadoop
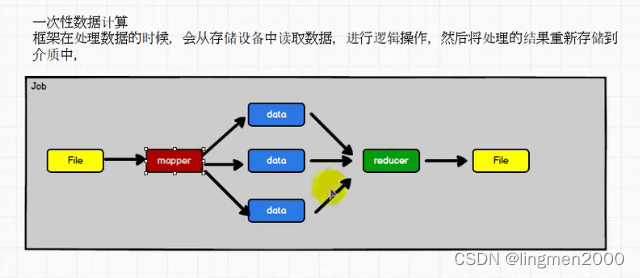
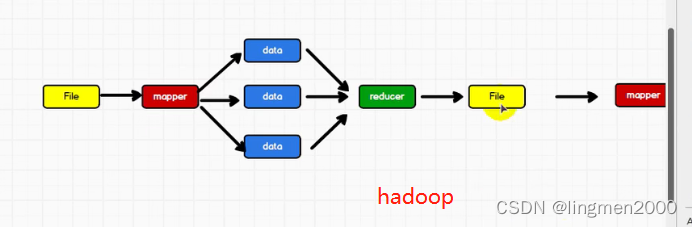
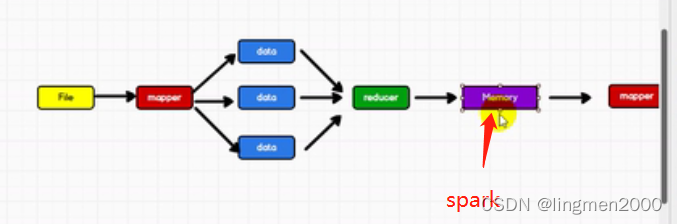
1.2,核心模块
sparkCore,sparkSql,sparkStreaming
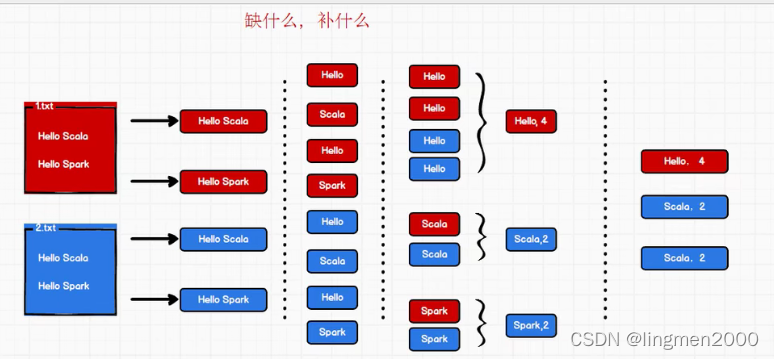
2,wordCount(demo)
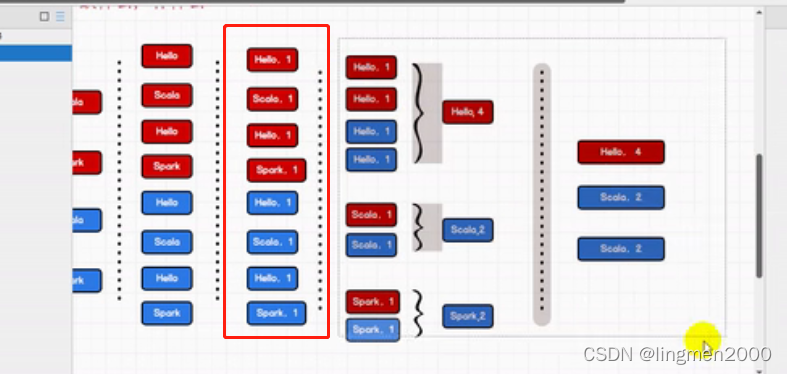
3,spark local 模式
3.1,spark-shell
sc.textFile("../data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect3.2,监控页面(端口:4040)
http://172.16.60.196:4040/jobs/
3.3,提交命令
./spark-submit --master local[2] --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.0.0.jar 104,standalone 模式
4.1,独立部署模式、主从模式
4.2,分发脚本
xsync
https://www.cnblogs.com/smandar/p/13898073.html
xcall
https://blog.csdn.net/eraining/article/details/108470060
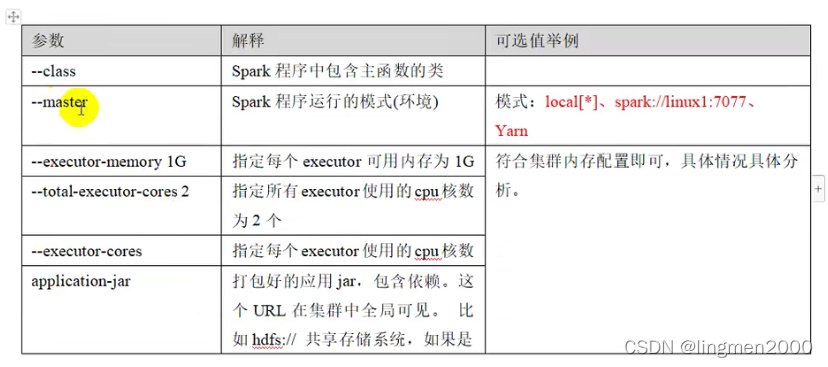
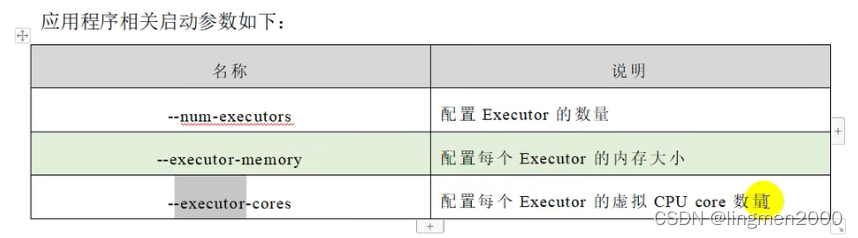
4.3,提交命令参数
4.4,配置历史服务
4.5,配置高可用(HA)
5,yarn 模式
5.1,yarn环境
5.2,提交命令


6,部署模式对比

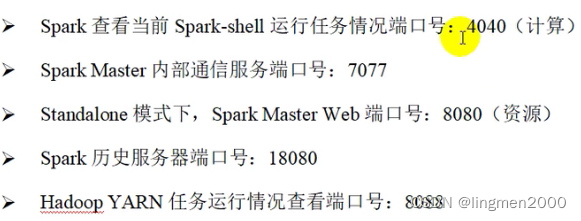
端口:
7,Driver

8,spark 核心组件
核心组件
driver、applicationMaster、master
核心概念
Executor
有向无环图(DAG):避免循环依赖
提交流程(资源申请、计算准备)

9,spark 三大数据结构
RDD
累加器
广播变量 
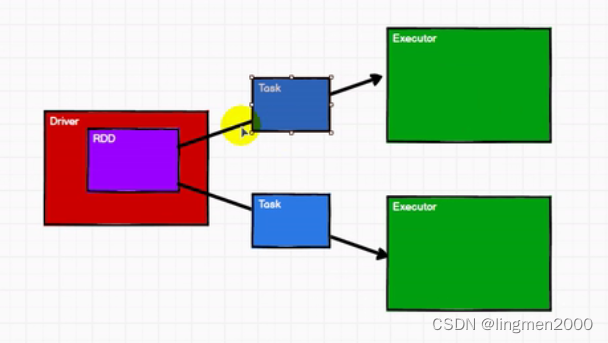
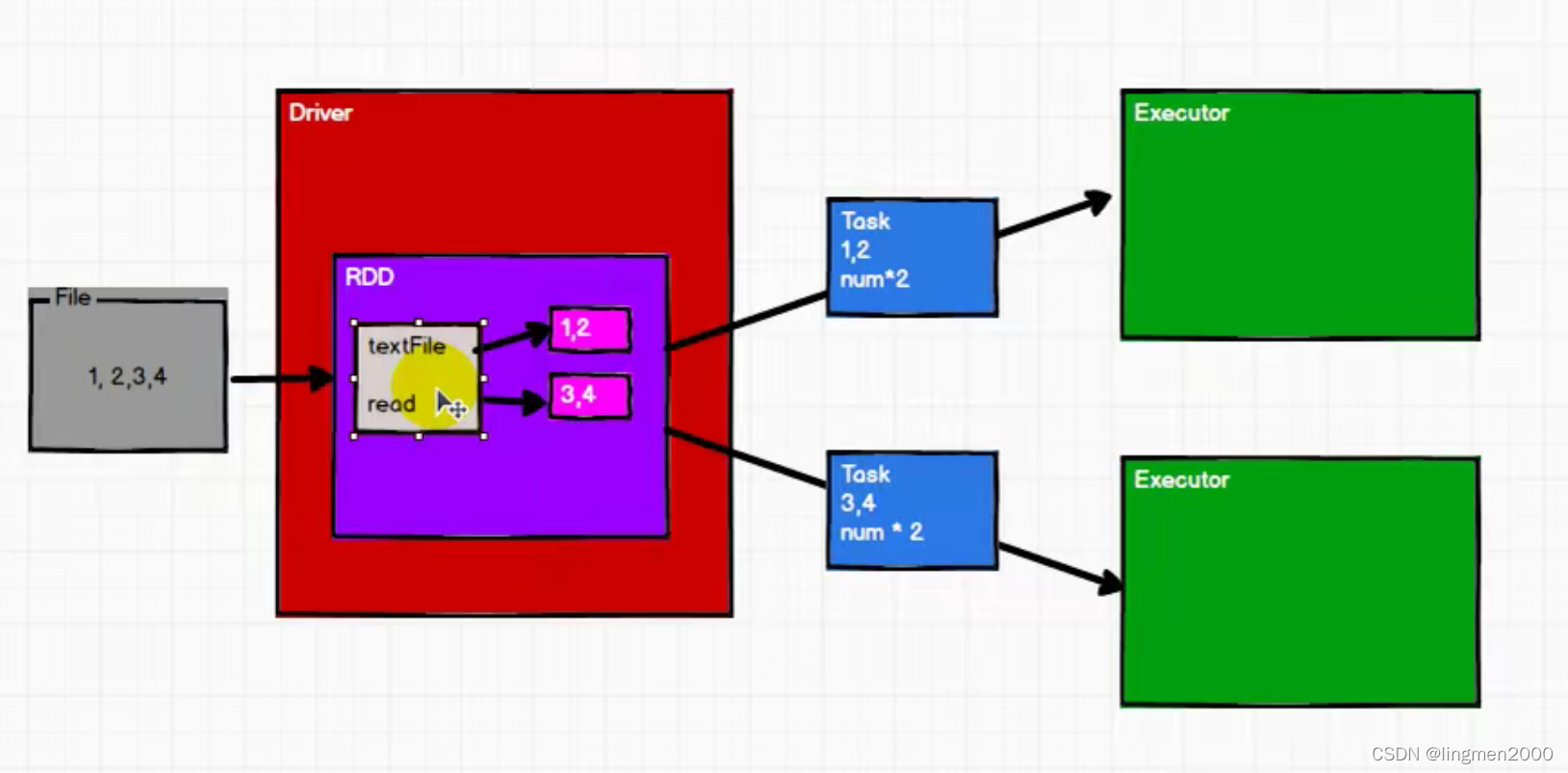
10,RDD 弹性分布式数据集(Resilient /rɪˈzɪliənt/ Distributed Dataset)
1,弹性(策略)
1.1,存储的弹性
1.2,容错的弹性
1.3,计算的弹性
1.4,分片的弹性(根据需要重新调整分区)
2,分布式:数据存储在大数据集群不同节点
3,数据集:RDD封装了数据逻辑,不保存数据
4,数据抽象:RDD是一个抽象类,需要子类具体实现
5,不可变:只能产生新的RDD(装饰者模式)
6,可分区、并行计算
RDD 核心属性
1,分区列表
2,分区计算函数
3,RDD之间的依赖关系
4,分区器(将数据分区处理)
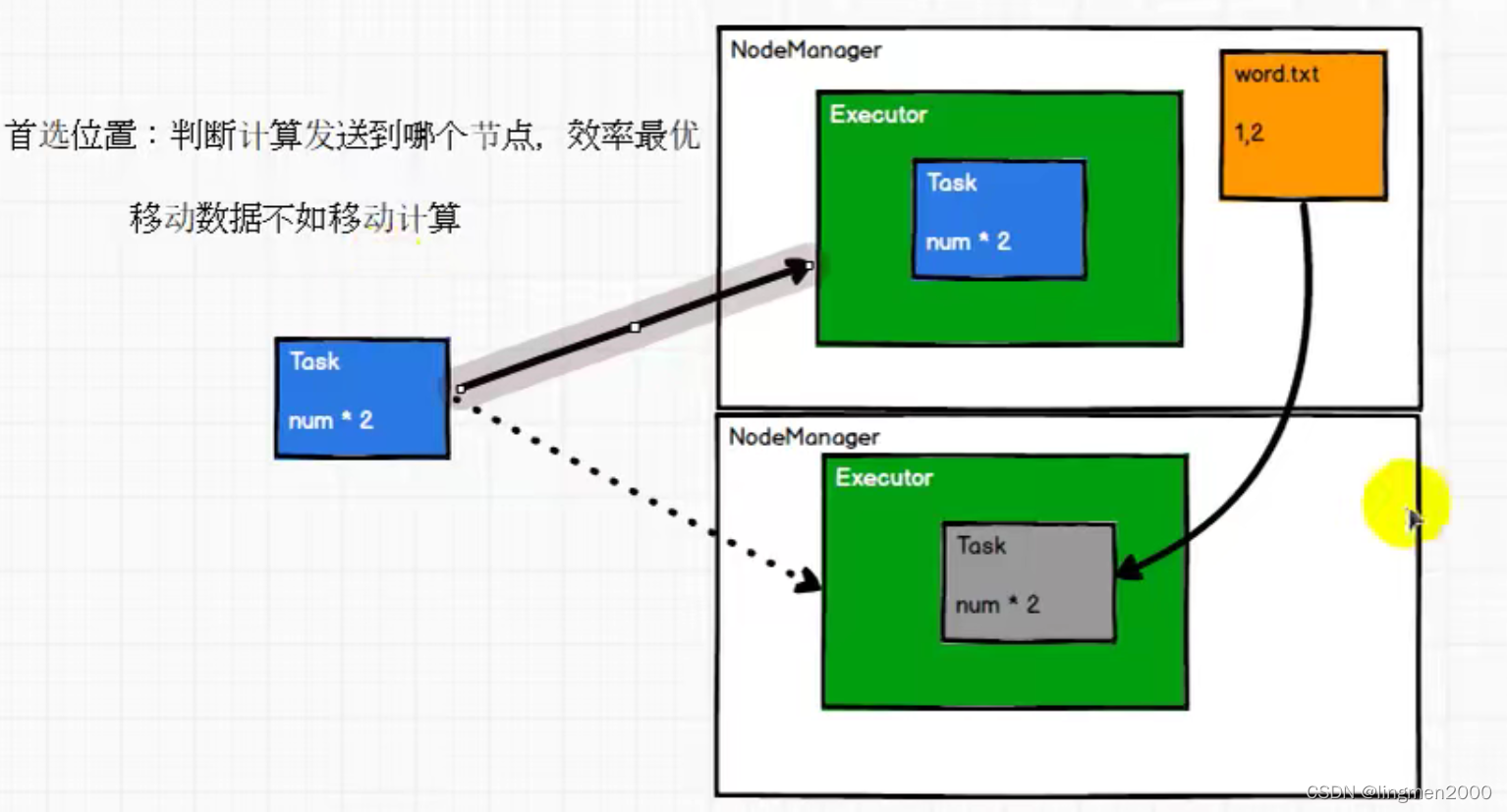
5,首选位置(判断计算发送到哪个节点效率最优),移动数据不如移动计算
执行原理

RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算
参考链接:
 https://www.bilibili.com/video/BV11A411L7CK?p=1
https://www.bilibili.com/video/BV11A411L7CK?p=1版权声明:本文为weixin_37998428原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。