gmflow, self, cross attention
后面再补一篇gmflow的解读
相关文章:《GMFlow: Learning Optical Flow via Global Matching》基于全局匹配的光流估计算法可视化
1. 前言
gmflow是一种基于全局匹配的光流估计方法,在全局匹配之前,会采用self attention,cross attention进行特征增强。这里实验对比一下self attention,cross attention两个部件。
2. 实验
训练采用realflow数据集,采用train_gmflow.sh原始的训练脚本,只是二者在网络构建时,一个只用self attention,一个只用cross attention,attention采用swin transformer,6个layer 层。验证集采用flying chairs, sintel数据集
- self attention版本训练时验证集上的指标
6w step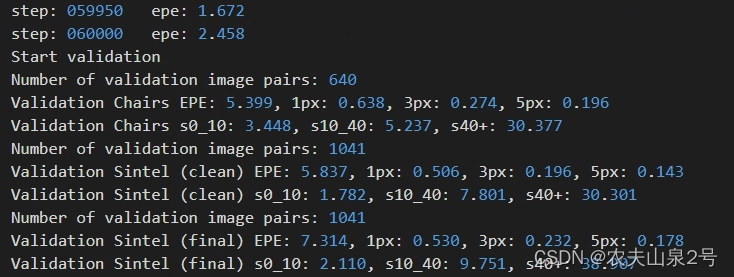
9w step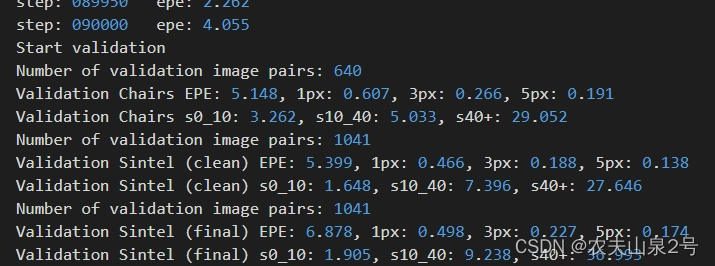
- cross attention
6w step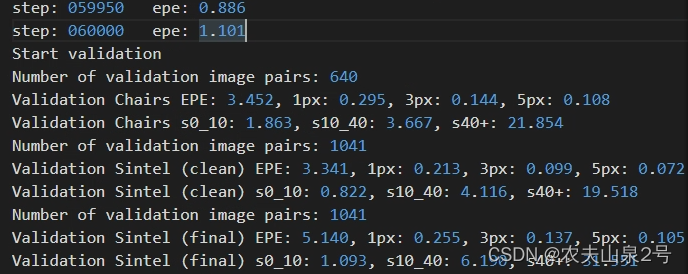
9w step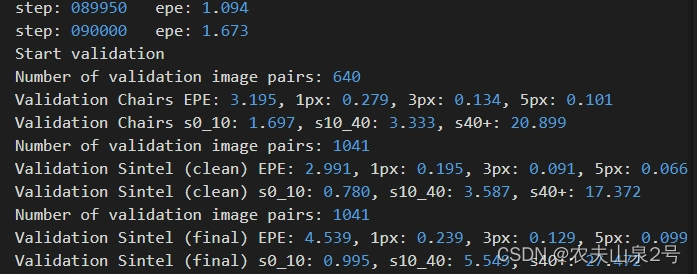
从实验来看,符合预期,cross attention的作用大于 self attention。但是transformer中的cross attention,计算代价太大。如何做替换,或高效。
结论
光流估计从匹配的思路来看,是估计两张图中的对应匹配点的关系,所以两张图的相关关系建模至关重要,对应到实现中时,cross attention > self attention 的作用,所以优化,提高的方向应更关注cross attention
- 如何高效的做cross attention
版权声明:本文为u011622208原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。