Hadoop Core - HDFS, MapReduce, YARN
参加拉勾教育大数据训练营课程笔记
引用:《Hadoop - The Definitive Guide, 4th Edition》,《拉勾导师笔记》
简介
大数据特性(5V)
引用自IBM’s Watson Health: The 5 V’s of big data - Watson Health Perspectives (ibm.com)
Volume - 量大
采集、存储和计算的数据量都非常大
1GB = 1024 MB
1TB = 1024 GB
1PB = 1024 TB
1EB = 1024 PB
1ZB = 1024 EB
1YB = 1024 ZB
1BB = 1024 YB
1NB = 1024 BB
1DB = 1024 NB基于IDC的报告预测,从2013年到2020年,全球数据量会从4.4ZB猛增到44ZB!而到了
2025年,全球会有163ZB的数据量!Velocity - 增加速度快,要求处理、计算速度快(甚至实时)。原文关键句:the rapidly increasing speed at which new data is being created by technological advances, and the corresponding need for that data to be digested and analyzed in near real-time.
数据的创建、存储、分析都要求被高速处理,比如电商网站的个性化推荐尽
可能要求实时完成推荐,这也是大数据区别于传统数据挖掘的显著特征。Variety - 多样 。原文关键语句:this third “V” describes just what you’d think: the huge diversity of data types that healthcare organizations see every day.
Veracity - 真实性,确保数据的真实性,才能保证分析结果(和原文第五点重复)。原文是Variability,多变性,是基于医学每个案例都不相同、多变的特点
Value - 大数据必须有价值,原文关键语句:big data must have value. That is, if you’re going to invest in the infrastructure required to collect and interpret data on a system-wide scale, it’s important to ensure that the insights that are generated are based on accurate data and lead to measurable improvements at the end of the day.
应用场景
- 仓储物流
- 电商零售
- 汽车
- 电信、通讯
- 生物医学
- 智慧城市
发展趋势和职业路线
目前大数据高、中、低三个档次的人才都很缺。 现在我们谈大数据,就像当年谈电商一样,未来
前景已经很明确,接下来就是优胜劣汰,竞争上岗。不想当架构师的程序员不是好架构师!但是,大数
据发展到现阶段,涉及大数据相关的职业岗位也越来越精细。
从职业发展来看,由大数据开发、挖掘、算法、到架构。从级别来看,从工程师、高级工程师,再
到架构师,甚至到科学家。而且,契合不同的行业领域,又有专属于这些行业的岗位衍生,如涉及金融
领域的数据分析师等。大数据的相关工作岗位有很多,有数据分析师、数据挖掘工程师、大数据开发工
程师、大数据产品经理、可视化工程师、爬虫工程师、大数据运营经理、大数据架构师、数据科学家等
等。
从事岗位:ETL工程师,数据仓库工程师,实时流处理工程师,用户画像工程师,数据挖掘,算法
工程师,推荐系统工程。
Hadoop
定义:
Hadoop - 分布式存储、计算平台。
广义上讲Hadoop代表大数据的一个技术生态圈:
Hadoop(HDFS + MapReduce + Yarn)
Hive - 数据仓库工具
HBase - 海量列式非关系型数据库
Flume - 数据采集工具
Sqoop - ETL工具
Kafka - 高吞吐消息中间件
起源:Nutch → \to→ Google论文(GFS、MapReduce) → \to→ Hadoop产生→ \to→ 成为Apache顶级项目 → \to→ Cloudera公司成立(Hadoop快速发展)
Hadoop最早起源于Nutch,Nutch 的创始人是Doug Cutting

Hadoop这个名字来源于Hadoop之父Doug Cutting儿子的毛绒玩具象

特点
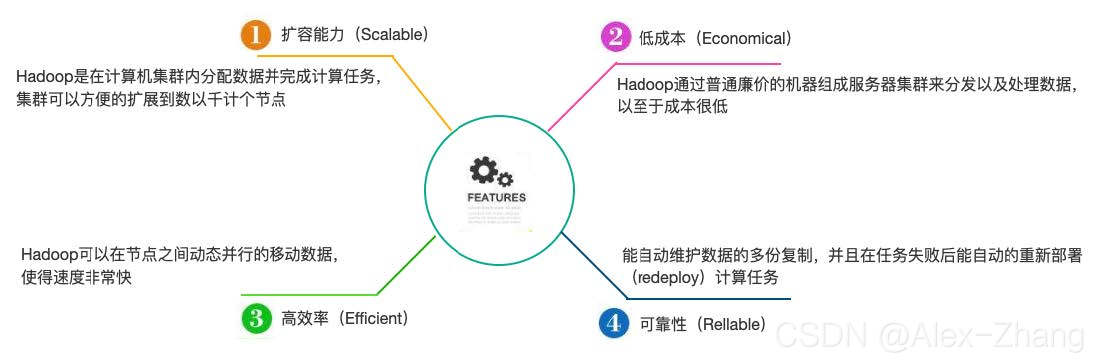
发行版本
- Cloudera发行版(CDH)
- Hortonworks
- 华为发行版
- Intel发行版
公司主要使用版本:
- Apache Hadoop 原始版本
官网地址:http://practice.hadoop.apache.org/
优点:拥有全世界的开源贡献,代码更新版本比较快
缺点:版本的升级,版本的维护,以及版本之间的兼容性,学习非常方便
Apache所有软件的下载地址(包括各种历史版本):http://archive.apache.org/dist/
软件收费版本ClouderaManager CDH版本 --生产环境使用
官网地址:https://www.cloudera.com/ - Cloudera主要是美国一家大数据公司在Apache开源Hadoop的版本上,通过自己公司内部的各种
补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版
本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用
免费开源版本HortonWorks HDP版本–生产环境使用
官网地址:https://hortonworks.com/ - hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,
核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通
过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
版本更迭
- 0.x 系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
- 1.x 版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
- 2.x 版本系列:架构产生重大变化,引入了yarn平台等许多新特性
- 3.x 版本系列:EC技术、YARN的时间轴服务等新特性
Hadoop核心模块
Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common模块
HDFS - Hadoop Distributed File System,是一个高可靠、高吞吐量的分布式文件系统,比如:100T数据存储。
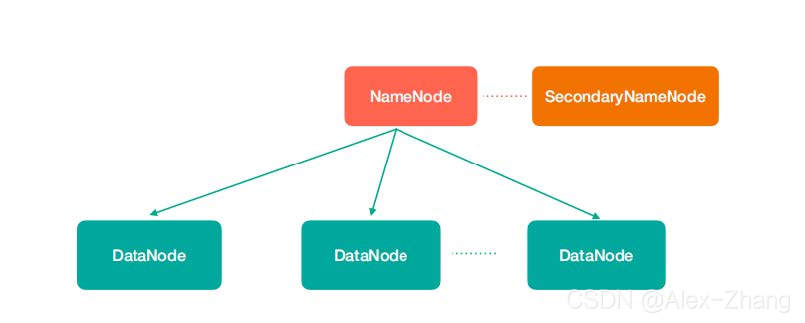
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副
本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台
程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验
注意:NN,2NN, DN这些既是角色名称,进程名称,代指电脑节点名称。MapReduce - Map阶段 + Reduce阶段
Map阶段就是“分”的阶段,并行处理输入数据;
Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总;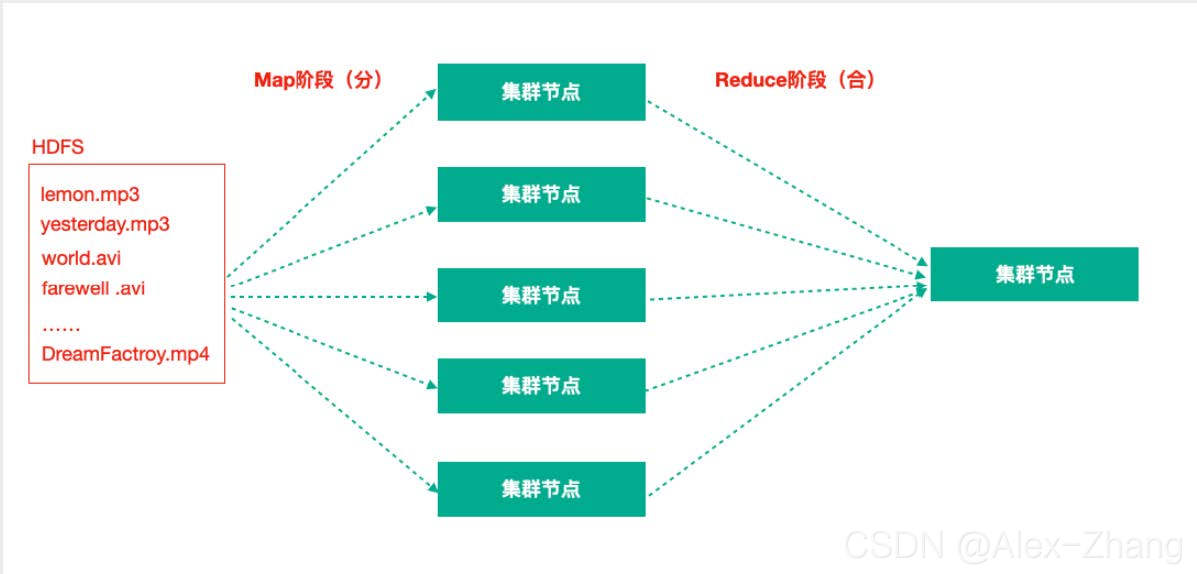
YARN - 作业调度与集群资源管理的框架
计算资源协调
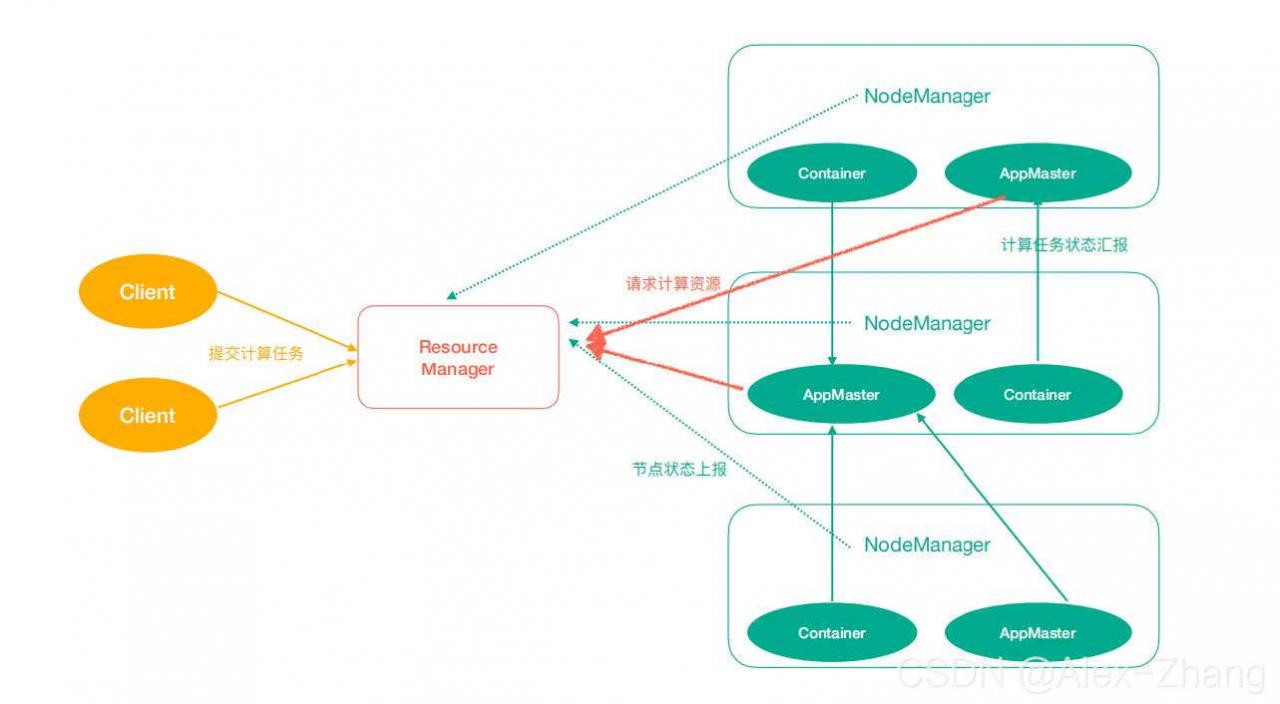
Yarn中有如下几个主要角色,同样,既是角色名、也是进程名,也指代所在计算机节点名称。
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控
NodeManager、资源分配与调度; - NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自
ApplicationMaster的命令; - ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容
错。 - Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任
务运行相关的信息。
ResourceManager是老大,NodeManager是小弟,ApplicationMaster是计算任务专员。
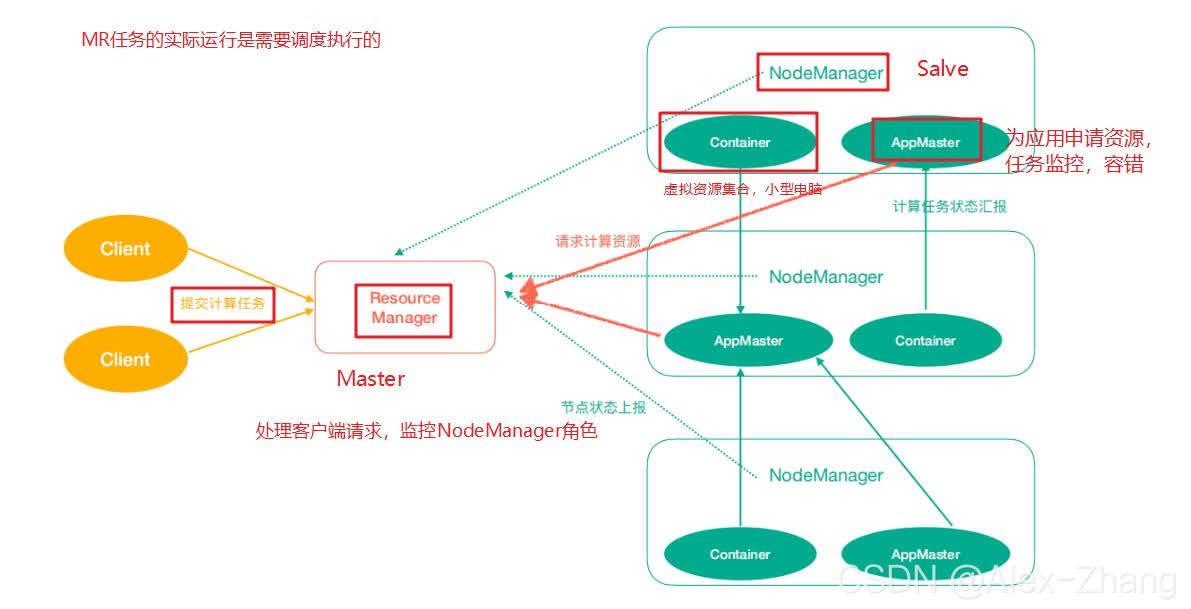
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控
Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
集群搭建
虚拟机安装准备(CentOS7 on VirtualBox & VMWare Workstation)
VirtualBox
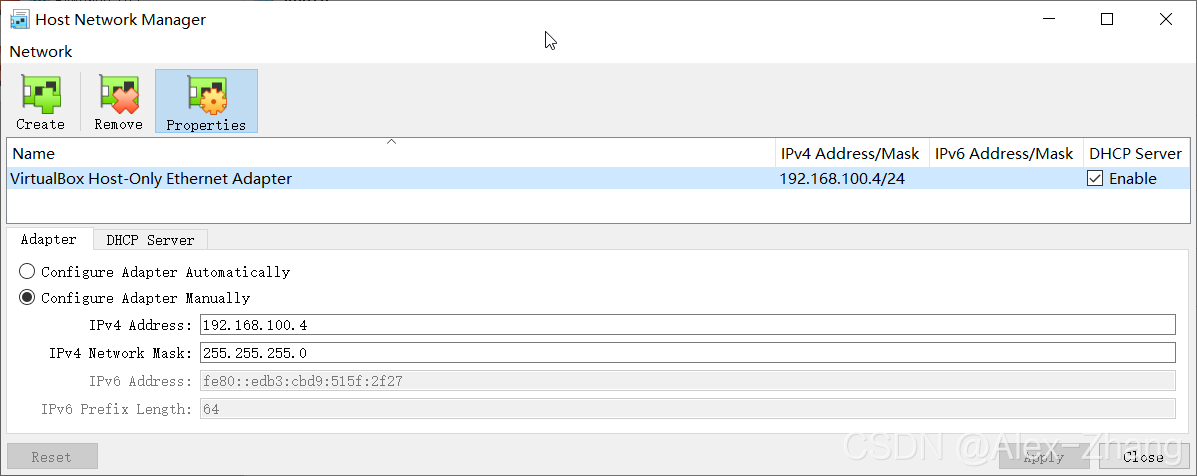
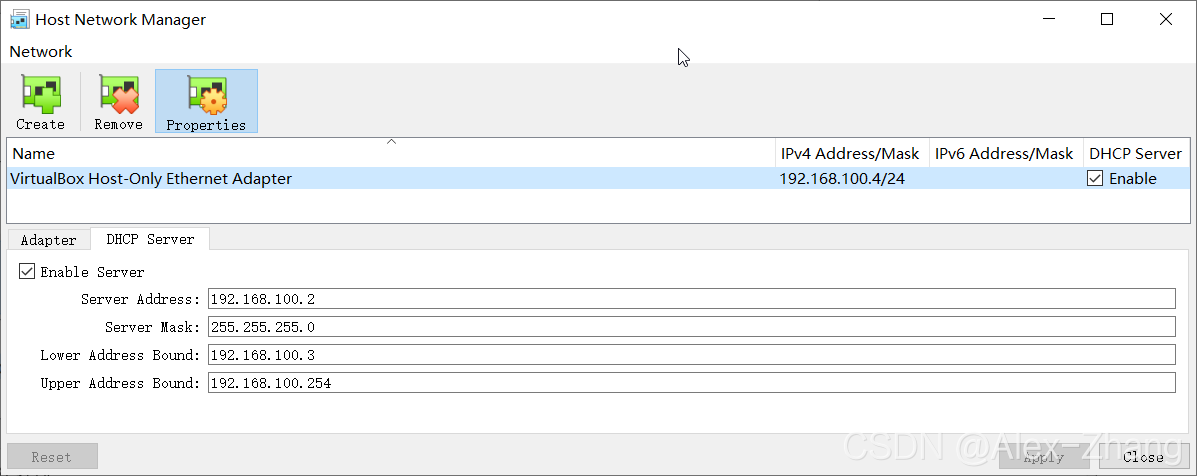
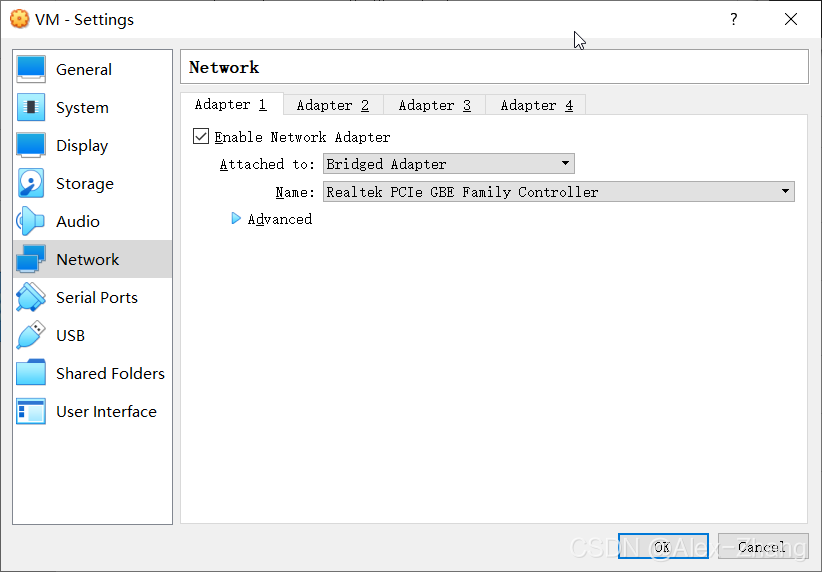
NAT Network Setup(桥接网络可跳过)
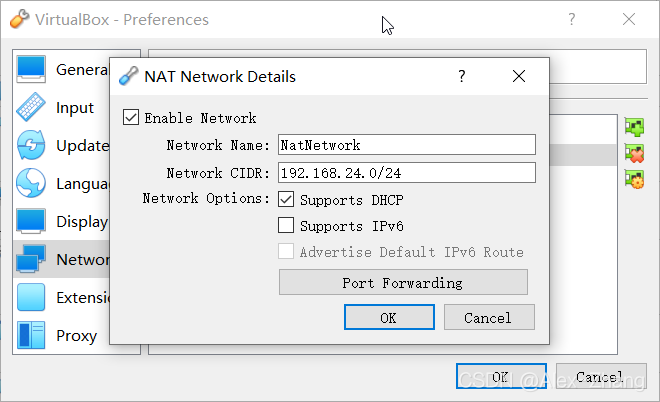
网段可自行设置
Host Network Setup(桥接网络可跳过)
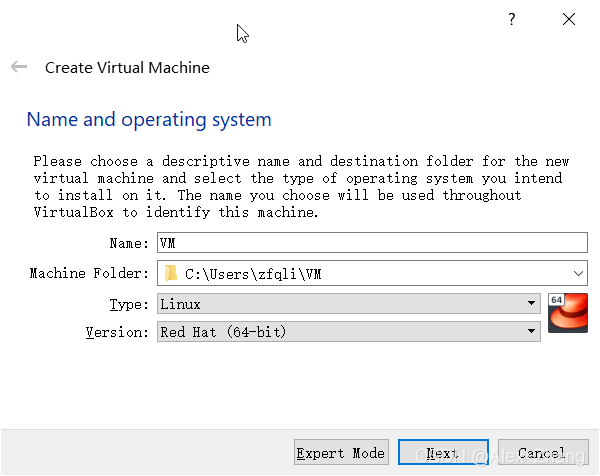
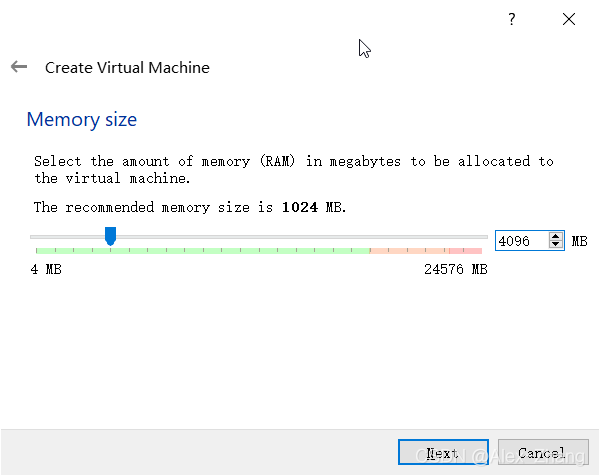
新建虚拟机
虚拟机设置
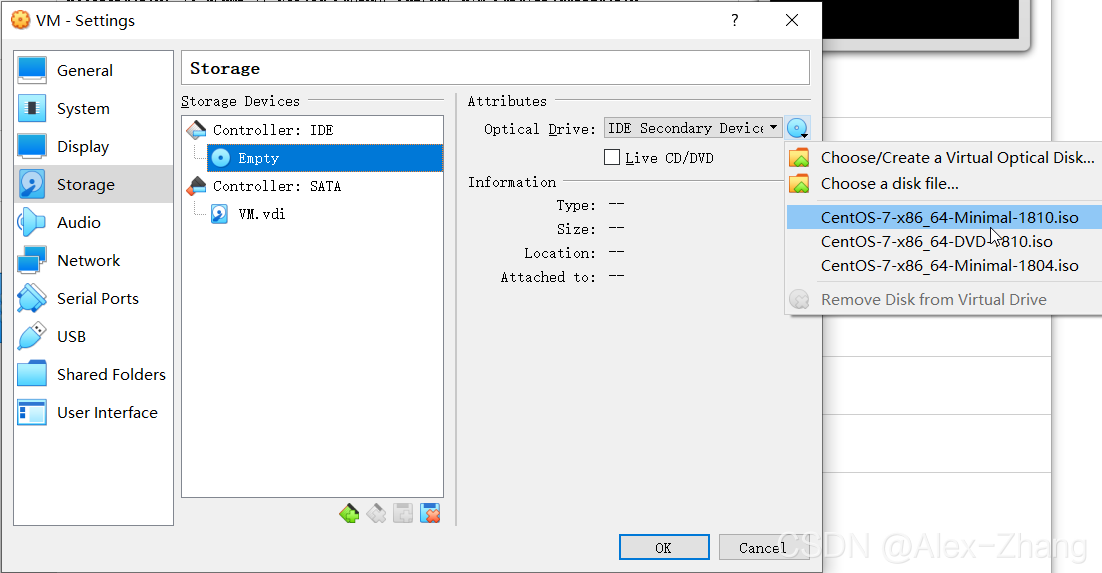
选择安装光盘
网络设置,选择了桥接,而不是NAT
安装CentOS7
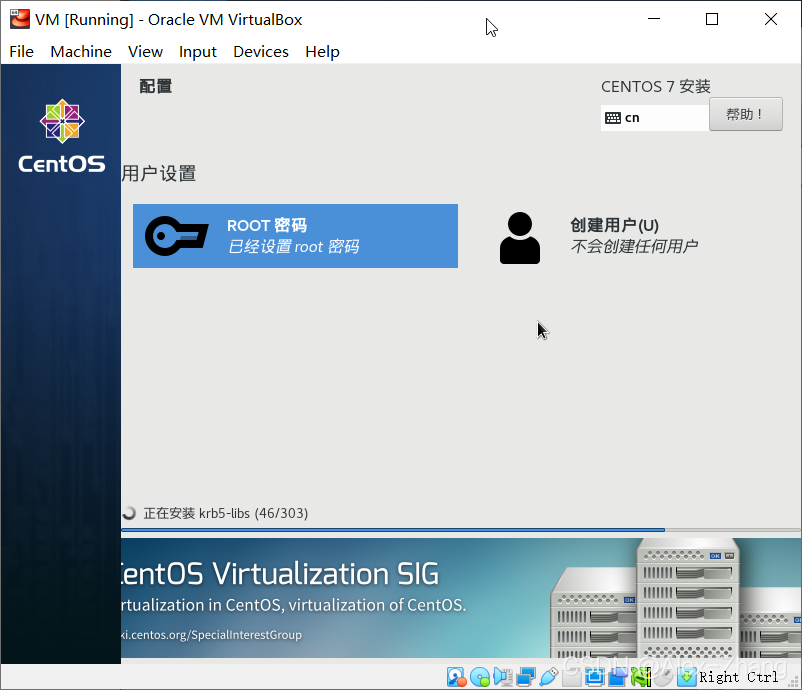
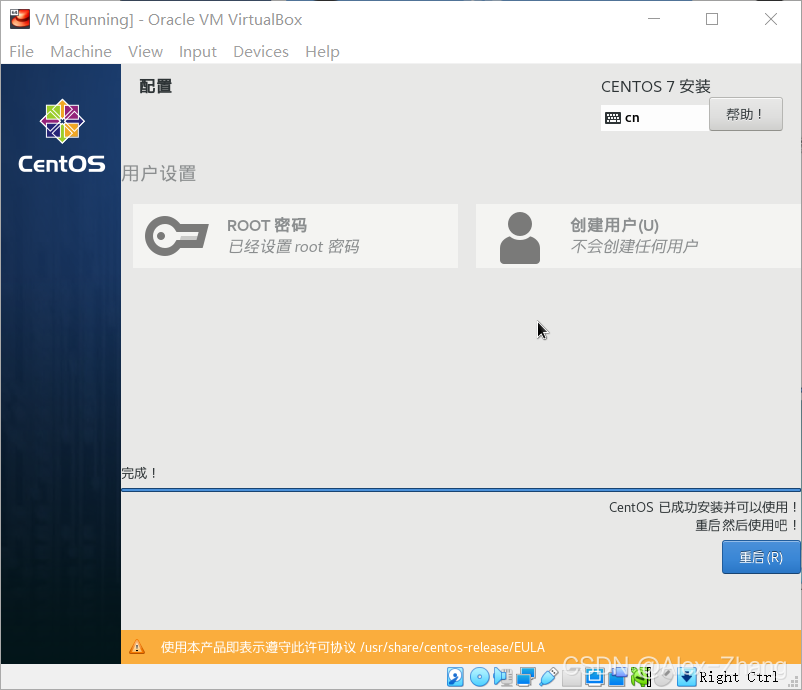
VMWare Workstation
暂缓
配置网络
配置
NAT Network(桥接网络跳过)通过修改网络配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-enp0s3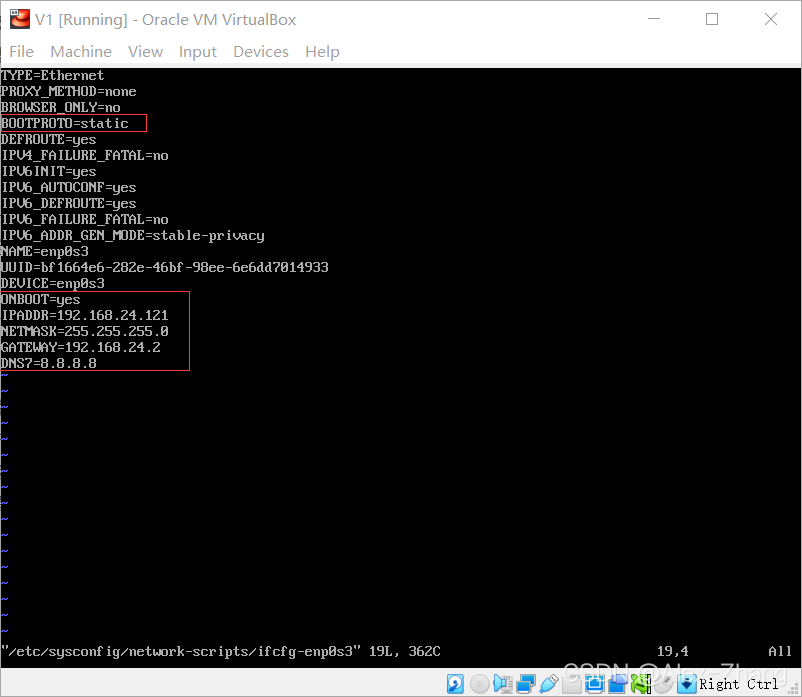
通过
nmtui- network manager terminal UI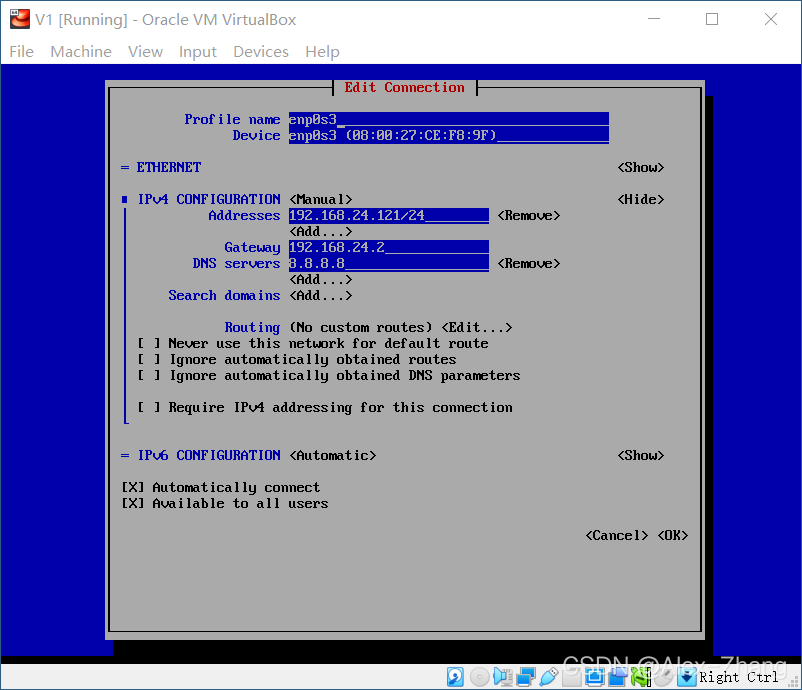
配置
hostonly网络(桥接网络跳过)通过修改网络配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-enp0s3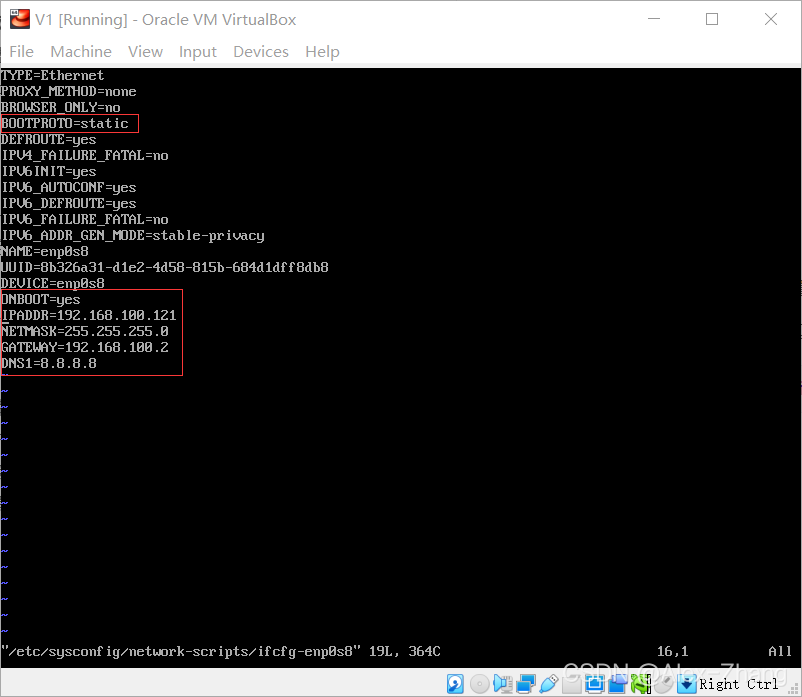
通过
nmtui- network manager terminal UI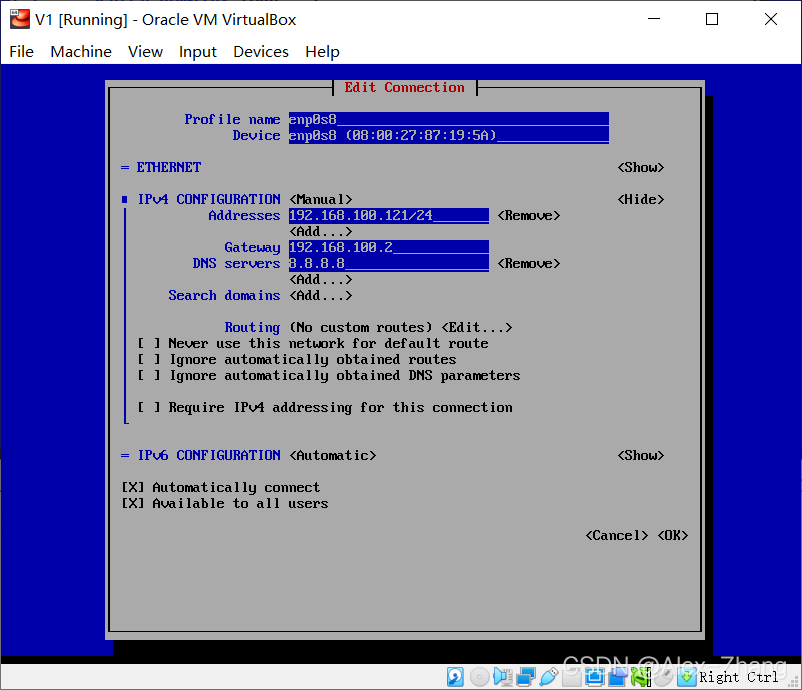
配置桥接网络
确保IP地址是在集群所在局域网内,并且没有冲突,我家里的路由网络是
192.168.31.*。/24代表NETMASK是255.255.255.0
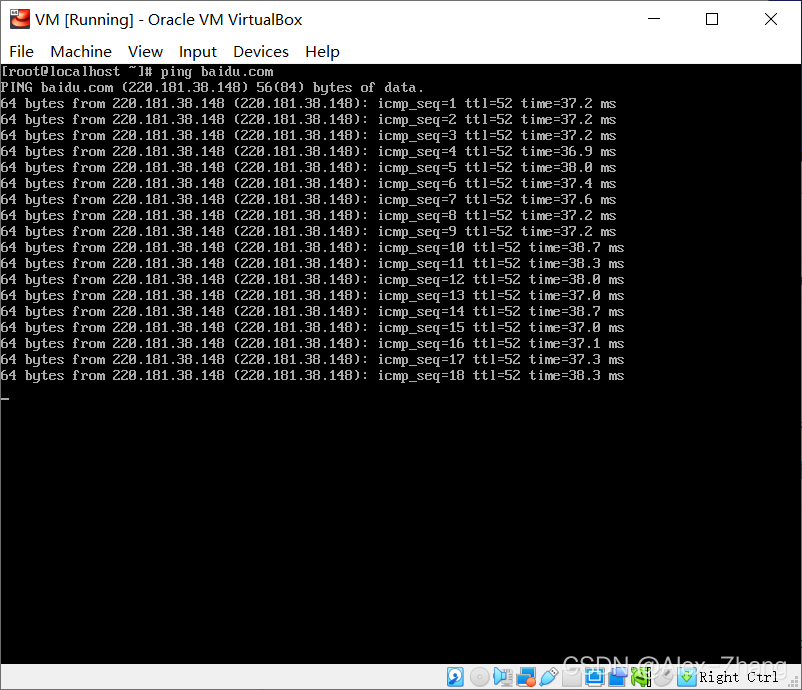
重启网络
systemctl restart network成功访问百度
宿主机通过
SSH连接虚拟机为了方便宿主机连接虚拟机,配置宿主机
hosts文件:192.168.100.121 h1 192.168.100.122 h2 192.168.100.123 h3关闭集群所有机器的防火墙
systemctl status firewalld systemctl stop firewalld vim /etc/selinux/config #SELINUX=enforcing SELINUX=disabled安装更新
yum -y update安装软件
yum -y install rsync vim ntpdate bzip2 net-tools kernel kernel-headers kernel-devel gcc gcc-c++ wget zip unzip mailxJDK
查找卸载已安装版本:
rpm -qa |grep java rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.i686 mkdir /usr/java cd /usr/java tar xf jdk-8u291-linux-x64.tar.gz -C /usr/java vim /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_291 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin source /etc/profile java -version
Tomcat
mkdir /usr/tomcat cd /usr/tomcat tar xf apache-tomcat-7.0.57.tar.gz /usr/tomcat/apache-tomcat-8.5.69/bin/startup.sh /usr/tomcat/apache-tomcat-8.5.69/bin/shutdown.sh
MySQL
rpm -qa | grep mysql mkdir /usr/software cd /usr/software wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm rpm -ivh mysql-community-release-el6-5.noarch.rpm yum install -y mysql-community-server systemctl start mysqld # 启动MySQL # 设置密码 /usr/bin/mysqladmin -u root password 'dont4get' mysql -uroot -pdont4getMySQL库已经安装成功, 成功连接到MySQL:
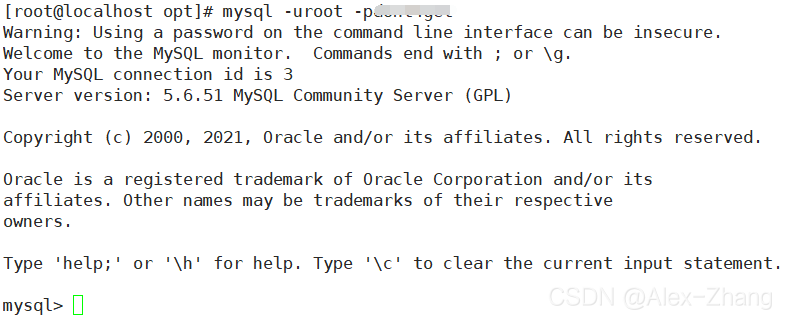
修改编码:> /etc/my.cnf # 清空文件 vim /etc/my.cnf [client] default-character-set=utf8 [mysql] default-character-set=utf8 [mysqld] character-set-server=utf8 systemctl restart mysqld # 重启MySQL配置远程连接:
```bash
grant all privileges on . to ‘root’@’%’ identified by ‘dont4get’ with grant option;
flush privileges;
Notes:
关闭和重启虚拟机:
shutdown now reboot now
配置时钟同步
MAILTO=""
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org;
禁止crontab发送邮件
在crontab末尾加上
>/dev/null 2>&1.
或者
&> /dev/null
例如
0 1 5 10 * /path/to/script.sh >/dev/null 2>&1
0 1 5 10 * /path/to/script.sh &> /dev/null
另外一种方法是编辑crontab
crontab -e
在第一行加入
MAILTO=""
配置虚拟机之间SSH免密连接
安装好的三台虚拟机:
生成
SSH密钥ssh-keygen发送
SSH密钥到需要免密连接到本机的机器cd .ssh ssh-copy-id -i id_rsa.pub h1 ssh-copy-id -i id_rsa.pub h2 ssh-copy-id -i id_rsa.pub h3
安装Hadoop集群
规划
| 框架 | 192.168.24.121(hostname=v1) | 192.168.24.122(hostname=v2) | 192.168.24.123(hostname=v3) |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
准备
添加环境变量:
export HADOOP_HOME=/opt/practice.hadoop-2.9.2
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
安装验证:

目录结构:
drwxr-xr-x 2 501 dialout 194 11月 13 2018 bin - operation相关,如practice.hadoop, hdfs等
drwxr-xr-x 3 501 dialout 20 11月 13 2018 etc - 配置文件,hdfs-site.xml,core-site.xml等
drwxr-xr-x 2 501 dialout 106 11月 13 2018 include
drwxr-xr-x 3 501 dialout 20 11月 13 2018 lib - 本地库jar包,解压缩的依赖
drwxr-xr-x 2 501 dialout 239 11月 13 2018 libexec
-rwxr-xr-x 1 501 dialout 104K 11月 13 2018 LICENSE.txt
-rwxr-xr-x 1 501 dialout 16K 11月 13 2018 NOTICE.txt
-rwxr-xr-x 1 501 dialout 1.4K 11月 13 2018 README.txt
drwxr-xr-x 3 501 dialout 4.0K 11月 13 2018 sbin - 启动停止等相关的管理脚本
drwxr-xr-x 4 501 dialout 31 11月 13 2018 share - Hadoop的jar包,官方的案例,文档等
配置
Hadoop集群配置 = HDFS配置 + MapReduce配置 + Yarn配置,官方默认参考配置:https://practice.hadoop.apache.org/docs/r2.9.2/practice.hadoop-project-dist/practice.hadoop-hdfs/hdfsdefault.xml
HDFS配置
practice.hadoop-env.shJDK路径vim practice.hadoop-env.sh # export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/usr/java/jdk1.8.0_231core-site.xml指定namenode节点及数据存储目录<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://v1:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>practice.hadoop.tmp.dir</name> <value>/opt/hadoop-2.9.2/data/tmp</value> </property> </configuration>hdfs-site.xml指定SecondaryNameNode节点<configuration> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>v3:50090</value> </property> <!--副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>slaves指定DataNode节点v1 v2 v3
MapReduce配置
将JDK路径明确配置给MapReduce(修改mapred-env.sh)
vim mapred-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_231指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml<configuration> <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Yarn配置
将JDK路径明确配置给Yarn(修改yarn-env.sh)
vim yarn-env.sh # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/usr/java/jdk1.8.0_231 fi指定ResourceManager老大节点所在计算机节点(修改yarn-site.xml)
<configuration> <!-- Site specific YARN configuration properties --> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>v3</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>指定NodeManager节点(会通过slaves文件内容确定)
修改owner和group
chown -R root:root /opt/practice.hadoop-2.9.2
分发配置 - 编写集群分发脚本rsync-script
scp
scp -r /opt/practice.hadoop-2.9.2 v2:opt/
scp -r /opt/practice.hadoop-2.9.2 v3:opt/
rsync同步工具,速度快,只对差异文件做更新,适合做同步
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号链接 |
yum install -y rsync # 三台机器上都需要安装
rsync /opt/practice.hadoop-2.9.2 root@v2:opt/
#!/bin/bash
# rsync-script
#1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$#
if((paramnum==0)); then
echo no params;
exit;
fi
#2 根据传入参数获取文件名称
p1=$1
file_name=`basename $p1`
echo fname=$file_name
#3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取用户名称
user=`whoami`
#5 循环执行rsync
for((host=1; host<4; host++)); do
echo ------------------- linux$host --------------
rsync -rvl $pdir/$file_name $user@v$host:$pdir
done
复制到v2,v3机器
rsync-script practice.hadoop-2.9.2
启动Hadoop
启动前需要格式化NameNode
practice.hadoop namenode -format
格式化后数据目录的变化:
在v1上启动NameNode
practice.hadoop-daemon.sh start namenode jps在v1、v2以及v3上分别启动DataNode
practice.hadoop-daemon.sh start datanode jpsweb端查看Hdfs界面
http://linux121:50070
查看HDFS集群正常节点Yarn单节点启动
yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager jps
Hadoop集群每次需要一个一个节点的启动,如果节点数增加到成千上万个怎么办?使用
Hadoop提供的群启脚本
Stop集群:
stop datanode, namenode
stop resourcemanager, nodemanager
practice.hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
yarn-daemon.sh start / stop resourcemanager / nodemanager
集群启动
start-dfs.sh # 根据规划,在h1执行
stop-dfs.sh
start-yarn.sh # 根据规划,在h3执行
stop-yarn.sh
mr-jobhistory-daemon.sh start historyserver # h1
三个节点均启动成功:
测试
hdfs dfs -mkdir -p /test/input
cd /root
vim test.txt
hdfs dfs -put /root/test.txt /test/input
hdfs dfs -put /test/input/test.txt
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /test/input /test/output
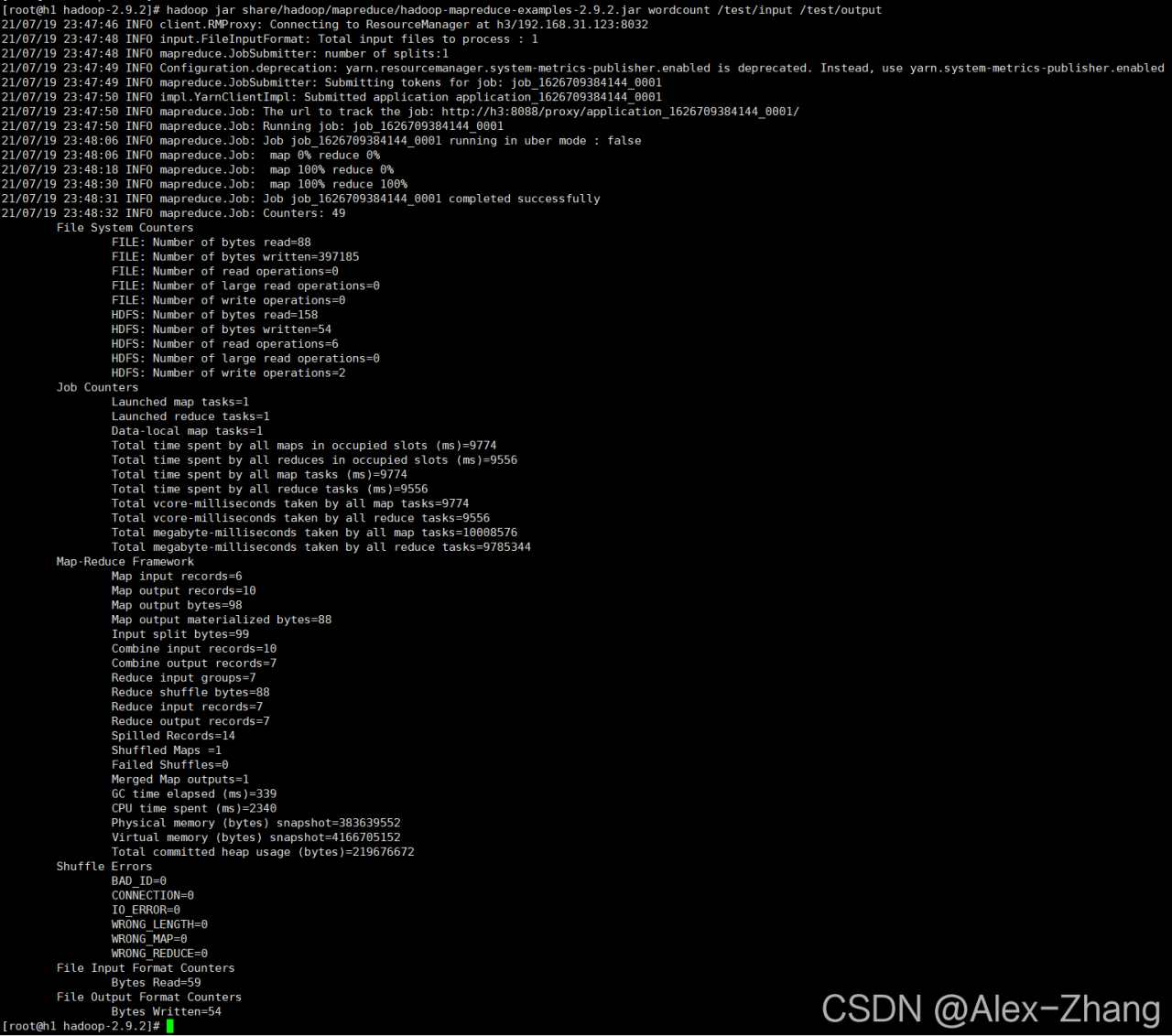
查看结果:
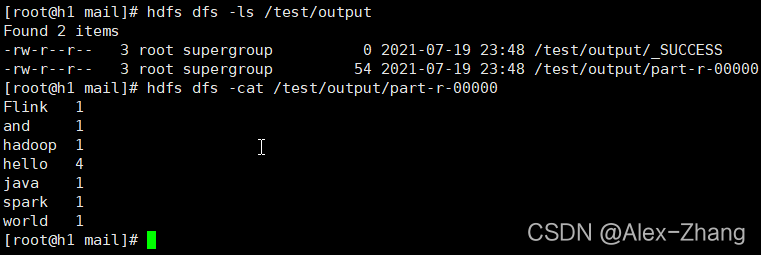
hdfs dfs -ls /test/output
hdfs dfs -cat /test/output/part-r-00000
backup hosts:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
配置历史服务器 (mapred-site.xml):
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>v1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>v1:19888</value>
</property>
# on v1
rsync-script mapred-site.xml
启动历史服务器:
# on v1
mr-jobhistory-daemon.sh start historyserver
配置日志聚集(yarn-site.xml):
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://v1:19888/jobhistory/logs</value>
</property>
# restart yarn
stop-yarn.sh # on v3
start-yarn.sh # on v3
# restart job history server
mr-jobhistory-daemon.sh stop historyserver
mr-jobhistory-daemon.sh start historyserver
HDFS文件系统
组成
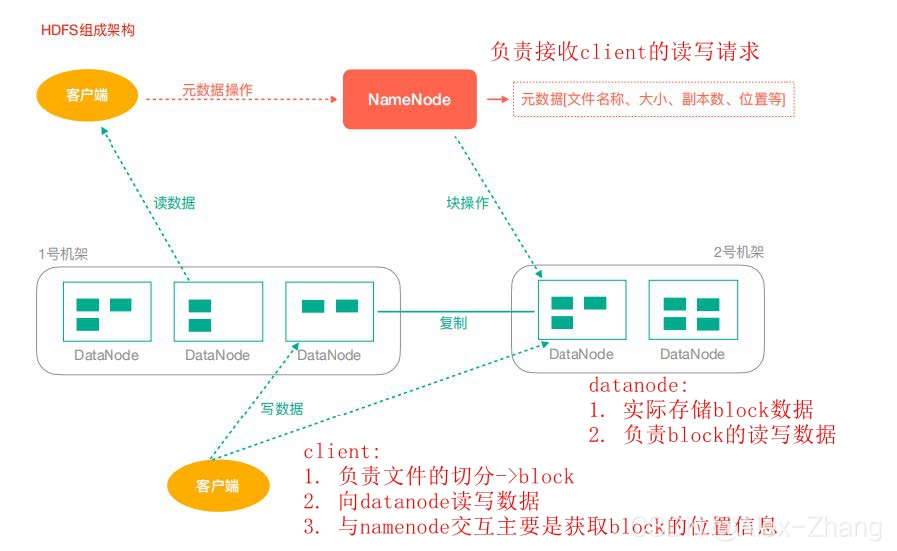
HDFS 通过统一的命名空间目录树来定位文件; 另外,它是分布式的,由很多服务器联合起来实现
其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职);
- 典型的 Master/Slave 架构
HDFS的架构是典型的Master/Slave结构。
HDFS集群往往是一个NameNode(HA架构会有两个NameNode,联邦机制)+ 多个DataNode组
成;
NameNode是集群的主节点,DataNode是集群的从节点。 - 分块存储(block机制)
HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定;
Hadoop2.x版本中默认的block大小是128M; - 命名空间(NameSpace)
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些
目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动
或重命名文件。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被
Namenode记录下来。
HDFS提供给客户单一个抽象目录树,访问形式:hdfs://namenode的hostname:port/test/input
hdfs://h1:9000/test/input - NameNode元数据管理
我们把目录结构及文件分块位置信息叫做元数据。
NameNode的元数据记录每一个文件所对应的block信息(block的id,以及所在的DataNode节点
的信息) - DataNode数据存储
文件的各个block的具体存储管理由DataNode节点承担。一个block会有多个DataNode来存
储,DataNode会定时向NameNode来汇报自己持有的block信息。 - 副本机制
为了容错,文件的所有block都会有副本。每个文件的block大小和副本系数都是可配置的。应用
程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
副本数量默认是3个。 - 一次写入,多次读出
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改。 (支持追加写入,
不只支持随机更新)
正因为如此,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用(修改不
方便,延迟大,网络开销大,成本太高)
架构
命令指南
hdfs dfs | hadoop fs
Java客户端读写
封装接口操作文件
package practice.P03M01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsTest {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
// conf.set("dfs.replication", "6"); // 设置hdfs参数
fs = FileSystem.get(new URI("hdfs://h1:9000"), conf, "root");
}
@After
public void close() throws IOException {
fs.close();
}
/**
* 创建文件夹
* @throws IOException IOException
*/
@Test
public void makeDirTest() throws IOException {
Path p = new Path("/api_test2");
if (!fs.exists(p)) {
fs.mkdirs(p);
}
}
/**
* 从本地复制文件到HDFS
* @throws IOException IOException
*/
@Test
public void uploadToHDFS() throws IOException {
Path src = new Path("C:\\Users\\zfqli\\Projects\\big_data_lagou\\lagou_bigdata_assignments\\.gitignore");
Path dst = new Path("/api_test");
fs.copyFromLocalFile(src, dst);
}
/**
* 删除HDFS文件/文件夹
* @throws IOException IOException
*/
@Test
public void delete() throws IOException {
Path toDelete = new Path("/api_test1");
fs.delete(toDelete, true);
}
/**
* 遍历HDFS文件/文件夹,fs.listFiles, LocatedFileStatus
* @throws IOException IOException
*/
@Test
public void listFiles() throws IOException {
Path p = new Path("/");
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(p, true);
while(remoteIterator.hasNext()) {
LocatedFileStatus lfs = remoteIterator.next();
final String filename = lfs.getPath().getName();
final long len = lfs.getLen();
final FsPermission permission = lfs.getPermission();
final String group = lfs.getGroup();
final String owner = lfs.getOwner();
final BlockLocation[] blockLocations = lfs.getBlockLocations();
System.out.println(filename + "\t" + len + "\t" + permission + "\t" + group + "\t" + owner);
for (BlockLocation blockLocation : blockLocations) {
final String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("==============================================");
}
}
/**
* 遍历HDFS文件/文件夹,fs.listFiles, LocatedFileStatus
* @throws IOException IOException
*/
@Test
public void listFileStatus() throws IOException {
Path p = new Path("/");
FileStatus[] fileStatuses = fs.listStatus(p);
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isFile()) {
System.out.println(fileStatus.getPath().getName() + " is a file.");
}
if(fileStatus.isDirectory()) {
System.out.println(fileStatus.getPath().getName() + " is a directory");
}
}
}
}
hdfs配置优先级:程序设置> \gt>本地hdfs-site.xml> \gt>集群配置> \gt>Hadoop默认值
IO流操作HDFS文件
package practice.P03M01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
public class IOHDFS {
private FileSystem fs;
private Configuration conf;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://h1:9000"), conf, "root");
}
@After
public void close() throws IOException {
fs.close();
}
/**
* 使用IO流上传文件
* @throws IOException IOException
*/
@Test
public void upload() throws IOException {
// 本地输入流读取文件,HDFS输出流写入文件
final FileInputStream fileInputStream = new FileInputStream(new File("C:\\Users\\zfqli\\Projects\\big_data_lagou\\lagou_bigdata_assignments\\.gitignore"));
final FSDataOutputStream fsDataOutputStream = fs.create(new Path("/.gitignore"));
IOUtils.copyBytes(fileInputStream, fsDataOutputStream, 4096, true);
}
/**
* 使用IO流下载文件
* @throws IOException IOException
*/
@Test
public void download() throws IOException {
// 本地输入流读取文件,HDFS输出流写入文件
final FileInputStream fileInputStream = new FileInputStream("C:\\Users\\zfqli\\Projects\\big_data_lagou\\lagou_bigdata_assignments\\.gitignore");
final FSDataOutputStream fsDataOutputStream = fs.create(new Path("/.gitignore"));
IOUtils.copyBytes(fileInputStream, fsDataOutputStream, 4096, true);
final FSDataInputStream open = fs.open(new Path("/.gitignore"));
final FileOutputStream fileOutputStream = new FileOutputStream("C:\\Users\\zfqli\\Projects\\big_data_lagou\\lagou_bigdata_assignments\\.gitignore");
IOUtils.copyBytes(open, fileOutputStream, conf);
}
/**
* 使用IO流下载文件
* @throws IOException IOException
*/
@Test
public void seekRead() throws IOException {
// 本地输入流读取文件,HDFS输出流写入文件
final FSDataInputStream open = fs.open(new Path("/.gitignore"));
IOUtils.copyBytes(open, System.out, 4096, false);
open.seek(0);
IOUtils.copyBytes(open, System.out, 4096, false);
IOUtils.closeStream(open);
}
}
HDFS读写机制
数据读取流程

客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
挑选一台DataNode(网络距离就近原则,然后随机)服务器,请求读取数据。
DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet(64KB)为单位来做校验)。
客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
数据写入流程
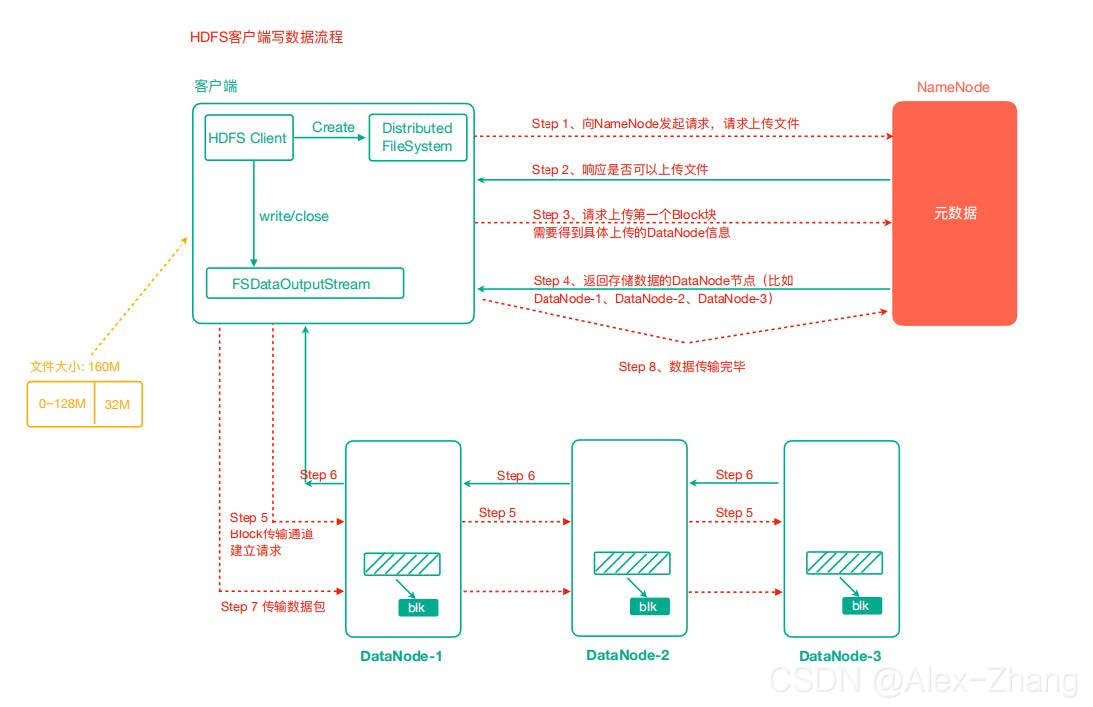
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS元数据管理
MapReduce编程 - 分而治之
思想
- Map阶段 - Map阶段的主要作用是“分”,即把复杂的任务分解为若干个相互独立的“简单任务”来并行处理。Map阶段的这些任务可以并行计算,彼此间没有依赖关系。
- Reduce阶段 - Reduce阶段的主要作用是“合”,即对map阶段的结果进行全局汇总。
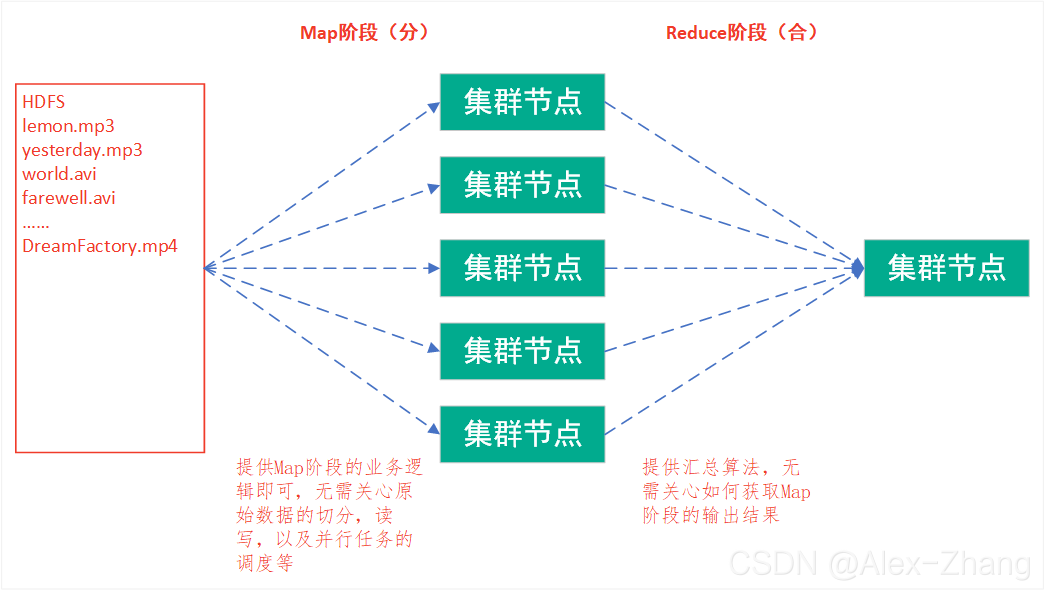
Map-Reduce ‘Hello World’ - WordCount
- Map阶段 - Extends
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>类, overridesmap方法。 - Reduce阶段 - Extends
Reducer<inputKey, inputValue, outKey, outValue>类, overridesreduce方法。输入即为Map输出的key+ 相同key的value集合
Hadoop序列化 - 网络传输,数据固化必需,Java默认序列化效率低,Hadoop去掉冗余部分,提升了效率,编写MapReduce程序均使用Hadoop的序列化类作为输入输出。
| Java基本类型 | Hadoop Writable类型 |
|---|---|
boolean | BooleanWritable |
byte | ByteWritable |
int | IntWritable |
float | FloatWritable |
long | LongWritable |
double | DoubleWritable |
String | Text |
map | MapWritable |
array | ArrayWritable |
WordCountMapper
一行数据运行一次
package practice.P03M01.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable ONE = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
while (stringTokenizer.hasMoreTokens()) {
word.set(stringTokenizer.nextToken());
context.write(word, ONE);
}
}
}
WordCountReducer
每个key调用运行一次
package practice.P03M01.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable count = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
count.set(sum);
context.write(key, count);
}
}
WordCountDriver
package practice.P03M01.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 获取配置,获取Job(任务)实例
final Configuration conf = new Configuration();
Job wordCount = Job.getInstance(conf, "WordCount");
// 2. 设置driver类
wordCount.setJarByClass(WordCountDriver.class);
// 3. 设置Map,Reduce类
wordCount.setMapperClass(WordCountMapper.class);
wordCount.setReducerClass(WordCountReducer.class);
// 4. 设置Map输出KEY-VALUE类型
wordCount.setMapOutputKeyClass(Text.class);
wordCount.setMapOutputValueClass(IntWritable.class);
// 5. 设置Reduce输出KEY-VALUE类型
wordCount.setOutputKeyClass(Text.class);
wordCount.setMapOutputValueClass(IntWritable.class);
// 6. 设置输入,输出路径
FileInputFormat.setInputPaths(wordCount, new Path(args[0]));
FileOutputFormat.setOutputPath(wordCount, new Path(args[1]));
// 7. 提交任务
boolean b = wordCount.waitForCompletion(true);
// 8. 处理返回结果
System.exit(b ? 0 : 1);
}
}
Run/Debug Configuration
提交到Yarn集群
1. 打包代码
Maven build配置
<!--maven打包插件 -->
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2. 上传jar包到集群
上传不包换依赖的jar包即可,因为WordCount中使用到的依赖集群中都有
[root@h1 wc]# pwd;ll
/root/projects/wc
总用量 12
-rwxr-xr-x 1 root root 4897 8月 22 15:42 wc.jar
-rwxr-xr-x 1 root root 304 8月 22 15:42 words.txt
3. 提交任务
[root@h1 wc]# hadoop jar wc.jar wordcount.WordCountDriver /wc /wc/output
21/08/22 15:47:53 INFO client.RMProxy: Connecting to ResourceManager at h3/192.168.31.123:8032
21/08/22 15:47:54 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
21/08/22 15:47:54 INFO input.FileInputFormat: Total input files to process : 1
21/08/22 15:47:54 INFO mapreduce.JobSubmitter: number of splits:1
21/08/22 15:47:54 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
21/08/22 15:47:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1629611371964_0001
21/08/22 15:47:55 INFO impl.YarnClientImpl: Submitted application application_1629611371964_0001
21/08/22 15:47:55 INFO mapreduce.Job: The url to track the job: http://h3:8088/proxy/application_1629611371964_0001/
21/08/22 15:47:55 INFO mapreduce.Job: Running job: job_1629611371964_0001
21/08/22 15:48:07 INFO mapreduce.Job: Job job_1629611371964_0001 running in uber mode : false
21/08/22 15:48:07 INFO mapreduce.Job: map 0% reduce 0%
21/08/22 15:48:15 INFO mapreduce.Job: map 100% reduce 0%
21/08/22 15:48:22 INFO mapreduce.Job: map 100% reduce 100%
21/08/22 15:48:22 INFO mapreduce.Job: Job job_1629611371964_0001 completed successfully
21/08/22 15:48:22 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=623
FILE: Number of bytes written=397743
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=396
HDFS: Number of bytes written=258
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5997
Total time spent by all reduces in occupied slots (ms)=3833
Total time spent by all map tasks (ms)=5997
Total time spent by all reduce tasks (ms)=3833
Total vcore-milliseconds taken by all map tasks=5997
Total vcore-milliseconds taken by all reduce tasks=3833
Total megabyte-milliseconds taken by all map tasks=6140928
Total megabyte-milliseconds taken by all reduce tasks=3924992
Map-Reduce Framework
Map input records=5
Map output records=53
Map output bytes=511
Map output materialized bytes=623
Input split bytes=92
Combine input records=0
Combine output records=0
Reduce input groups=35
Reduce shuffle bytes=623
Reduce input records=53
Reduce output records=35
Spilled Records=106
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=142
CPU time spent (ms)=1630
Physical memory (bytes) snapshot=364503040
Virtual memory (bytes) snapshot=4166545408
Total committed heap usage (bytes)=219676672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=304
File Output Format Counters
Bytes Written=258
4. 检查结果
[root@h1 wc]# hadoop fs -ls /wc/output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-08-22 15:48 /wc/output/_SUCCESS
-rw-r--r-- 3 root supergroup 258 2021-08-22 15:48 /wc/output/part-r-00000
[root@h1 wc]# hadoop fs -cat /wc/output/part-r-00000
A 1
Maps 2
The 1
a 2
are 1
as 1
be 1
given 1
individual 1
input 4
intermediate 3
into 1
key 2
many 1
map 1
may 1
need 1
not 1
of 2
or 1
output 1
pair 1
pairs 3
records 4
same 1
set 1
tasks 1
the 3
to 2
transform 1
transformed 1
type 1
value 2
which 1
zero 1
MR序列化 - 统计指南音箱设备内容播放时长
- 必须有空参构造方法,反射时调用。
- 实现
Writable接口,实现方法write,readFields。 write,readFields的字段顺序必须一致。- 重写
toString方便数据展示 - 如果要作为key,还必须实现
Comparable接口。Hadoop提供了WritableComarable接口,方便同时实现两个接口。
Mapper中相同key的values会去到同个Reducer。
reduce方法的输入K-V即是map方法输出的K-V,其中V是一个集合,是所有KEY相同的values集合。
字段定义:
| 日志id | 设备id | appkey(合作硬件厂商) | 网络ip | 自有内容时长(秒) | 第三方内容时长(秒) | 网络状态码 |
|---|---|---|---|---|---|---|
| 01 | a00df6s | kar | 120.196.100.99 | 384 | 33 | 200 |
PlayLogBean
package practice.P03M01.mapreduce.playtime;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PlayLogBean implements Writable {
private String deviceId;
private Long selfDuration;
private Long thirdDuration;
private Long totalDuration;
public PlayLogBean() {
}
public PlayLogBean(String deviceId, Long selfDuration, Long thirdDuration) {
this.deviceId = deviceId;
this.selfDuration = selfDuration;
this.thirdDuration = thirdDuration;
this.totalDuration = selfDuration + thirdDuration;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(deviceId);
out.writeLong(selfDuration);
out.writeLong(thirdDuration);
out.writeLong(totalDuration);
}
@Override
public void readFields(DataInput in) throws IOException {
deviceId = in.readUTF();
selfDuration = in.readLong();
thirdDuration = in.readLong();
totalDuration = in.readLong();
}
public String getDeviceId() {
return deviceId;
}
public void setDeviceId(String deviceId) {
this.deviceId = deviceId;
}
public Long getSelfDuration() {
return selfDuration;
}
public void setSelfDuration(Long selfDuration) {
this.selfDuration = selfDuration;
}
public Long getThirdDuration() {
return thirdDuration;
}
public void setThirdDuration(Long thirdDuration) {
this.thirdDuration = thirdDuration;
}
public Long getTotalDuration() {
return totalDuration;
}
public void setTotalDuration(Long totalDuration) {
this.totalDuration = totalDuration;
}
@Override
public String toString() {
return deviceId +
"\t" + selfDuration +
"\t" + thirdDuration +
"\t" + totalDuration;
}
}
PlayTimeMapper
package practice.P03M01.mapreduce.playtime;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PlayTimeMapper extends Mapper<LongWritable, Text, Text, PlayLogBean> {
private Text deviceId = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, PlayLogBean>.Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
String deviceId = fields[1];
this.deviceId.set(deviceId);
Long selfDuration = Long.parseLong(fields[4]);
Long thirdDuration = Long.parseLong(fields[5]);
PlayLogBean playLogBean = new PlayLogBean(deviceId, selfDuration, thirdDuration);
context.write(this.deviceId, playLogBean);
}
}
PlayTimeReducer
package practice.P03M01.mapreduce.playtime;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PlayTimeReducer extends Reducer<Text, PlayLogBean, Text, PlayLogBean> {
@Override
protected void reduce(Text key, Iterable<PlayLogBean> values, Reducer<Text, PlayLogBean, Text, PlayLogBean>.Context context) throws IOException, InterruptedException {
Long selfDurationAccumulator = 0L;
Long thirdDurationAccumulator = 0L;
for (PlayLogBean val : values) {
selfDurationAccumulator += val.getSelfDuration();
thirdDurationAccumulator += val.getThirdDuration();
}
PlayLogBean playLogBean = new PlayLogBean(key.toString(), selfDurationAccumulator, thirdDurationAccumulator);
context.write(key, playLogBean);
}
}
PlayTimeDriver
package practice.P03M01.mapreduce.playtime;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PlayTimeDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Play Time Calc");
job.setJarByClass(PlayTimeDriver.class);
job.setMapperClass(PlayTimeMapper.class);
job.setReducerClass(PlayTimeReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PlayLogBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PlayLogBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
MR原理分析
- 数据读取组件
InputFormat,是一个抽象类,默认使用TextInputFormat通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,每个split启动一个MapTask。默认切片大小=块大小(128M),意味着默认切片数目等于块数目。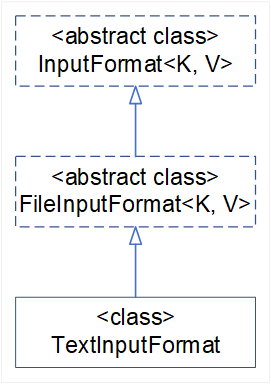
public abstract class InputFormat<K, V>
public abstract class FileInputFormat<K, V> implements InputFormat<K, V>
/** An InputFormat for plain text files. Files are broken into lines.
* Either linefeed or carriage-return are used to signal end of line. Keys are
* the position in the file, and values are the line of text.. */
public class TextInputFormat extends FileInputFormat<LongWritable, Text>
RecordReader,默认LineRecordReader从FileSplit以或者为分隔符按行读取数据,支持三种换行符(\n,\r,\r\n),返回KEY-VALUE,KEY是行首字符在文件中的偏移值,VALUE是整行文本内容\n- Linux/Unix\r- Mac\r\n- Windows
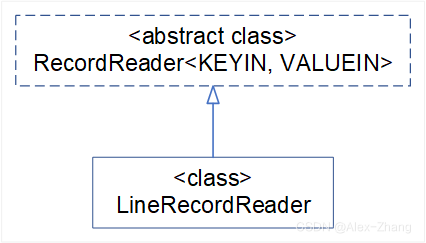
/** * The record reader breaks the data into key/value pairs for input to the * {@link Mapper}. * @param <KEYIN> * @param <VALUEIN> */ public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable/** * Treats keys as offset in file and value as line. */ public class LineRecordReader extends RecordReader<LongWritable, Text>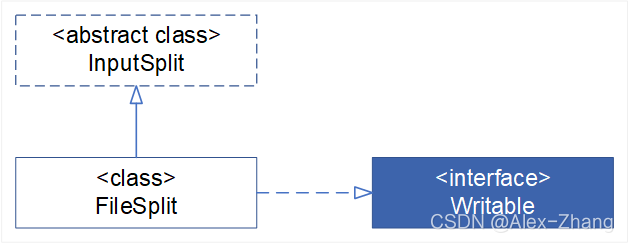
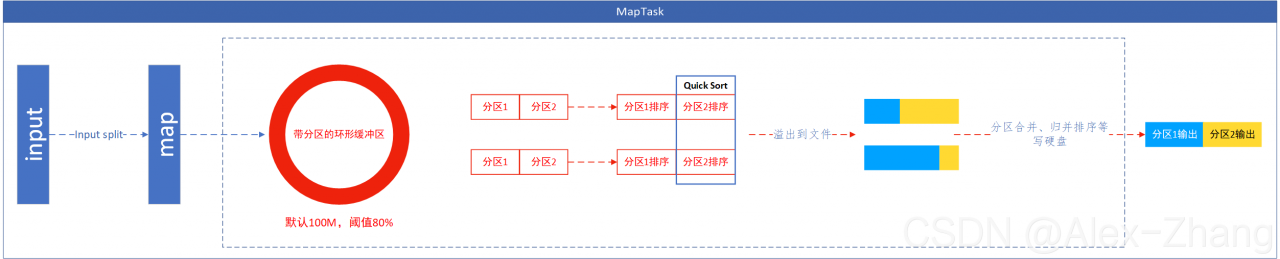
/** * <code>InputSplit</code> represents the data to be processed by an * individual Mapper. * * <p>Typically, it presents a byte-oriented view on the input and is the * responsibility of {@link RecordReader} of the job to process this and present * a record-oriented view. * * @see InputFormat * @see RecordReader */ public abstract class InputSplit/** A section of an input file. Returned by * InputFormat.getSplits(JobContext)} and passed to * InputFormat.createRecordReader(InputSplit,TaskAttemptContext). */ public class FileSplit extends InputSplit implements WritableRecordReader每读取一个KEY-VALUE,使用KEY-VALUE作为参数调用用户重写的map方法一次。map逻辑结束后,调用context.write进行collect数据收集,在collection过程中,会先对其进行分区处理,默认使用HashPartitioner。MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key进行hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。数据写入内存 - 环形缓冲区,减少硬盘I/O。
KEY-VALUE和partition结果都会写入缓冲区,KEY-VALUE在写入前被序列化为字节数组。- 环形缓冲区是一个数组,存放着
KEY-VALUE的序列化数据和KEY-VALUE的元数据信息,包括partition、key的起始位置,value的起始位置和长度。环形结构是一个抽象概念。 - 缓冲区大小限制,默认为
mapreduce.task.io.sort.mb = 100M。当MapTask输出结果超过缓冲区负荷时,需要将数据临时写入硬盘,腾出缓冲区内存区域以便从新使用。这个从缓冲区往硬盘写数据的过程称为spill,即溢写。溢写过程由单独的线程完成,不会影响往缓冲区写入MapTask输出数据的线程。不可能缓冲区使用完的时候才触发溢写,否则会影响MapTask的输出,所以会设置一个溢写比例(默认80%,mapreduce.map.sort.spill.percent=0.8),也就是当缓冲区数据达到阈值(buffer size * spill percent = 100M * 0.8 = 80M),触发溢写线程,锁定这80M内存,执行溢写过程。MapTask的输出数据继续写入剩下的20M缓冲内存,互不影响。但如果溢写结束前,缓冲区被写满,那么MapTask将被阻塞,直到溢写完成,释放出缓冲区的内存。
- 环形缓冲区是一个数组,存放着
当溢写线程启动后,在将缓冲区数据写入硬盘之前,会对每个分区进行排序(within each partition, the backgroud thread performs an in-memory sort by key. If there is a combiner function, it is run on the output of the sort. Running combiner function makes for a more compact map output, so thers is less data to write to local disk and to transfer to the reducer),需要对这
80M空间内的key做排序,排序是MapReduce的默认行为。每次达到spill阈值时,一个新的溢写文件()spill file)会被创建,所有一个MapTask可能会有多个spill file。- 如果有3个及以上
spill file(mapreduce.map.combine.minspills = 3),则在溢写前调用combiner - 切记当且仅当
combiner不会影响最终结果的时候,才能使用combiner。
- 如果有3个及以上
通常在写入/传输数据前压缩数据是一个好主意,可以减少硬盘写入、数据传输到
reducer的数据量,从而节约I/O开销。默认MapTask的输出没有压缩,可以设置mapreduce.map.output.compress来开启压缩,通过mapreduce.map.output.compress.codec来指定压缩策略(算法)。MapTask结束前,所有的spill file会被合并成一个已分区(partitioned)并且排好序(sorted)的输出文件,并为这个文件提供了一个索引文件,以记录每个reducer对应分区数据的偏移量。mapreduce.task.io.sort.factor控制合并时最多允许同时多少个文件流(maximum number of streams to merge at once),默认值是10。MapTask的输出文件的分区通过HTTP提供给对应的reducer,同时提供文件分区的worker thread最大数量由mapreduce.shuffle.max.threads, this setting is per node manager, not per map task. 默认值是0,将会使用机器的处理器个数 * 2(n u m b e r o f p r o c e s s o r s × 2 number\space of\space processors \times 2number of processors×2)。