目录
使用场景
分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。
有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。
分布式与单机情况下最大的不同在于其不是多线程而是多进程。多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置。而进程之间甚至可能都不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
分布式锁的要求
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
这把锁要是一把可重入锁(避免死锁)
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
有高可用的获取锁和释放锁功能
获取锁和释放锁的性能要好
常见方案
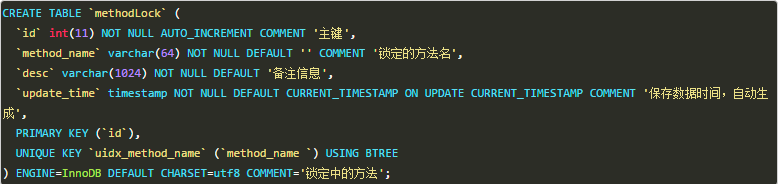
1、基于数据库表
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
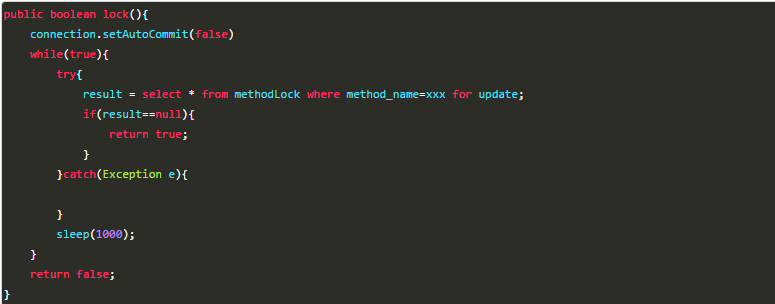
- 当我们想要锁住某个方法时,执行以下SQL:
insert into methodLock(method_name, desc) values ('method_name', 'desc')由于已对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
- 当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:
delete from methodLock where method_name = 'method_name'这种实现存在一些问题:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决办法:
搞主、备两个库,同步数据,做灾备,一旦挂掉快速切换到备库
2.没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
3.非阻塞的?搞一个while循环,直到insert成功再返回成功。
4.非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
2、基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
查询语句后面增加 for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:

通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
阻塞锁? for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
- 缺点是数据的建立会消耗资源,效率低下,而且从安全和规范操作上,数据库禁止使用for update 是比较常见的方案。
一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
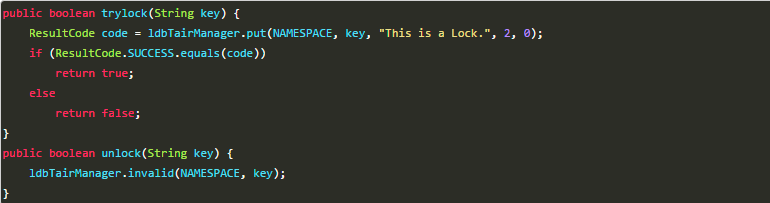
3、基于分布式缓存
redis、memcached、ttserver等
1、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在tair中,其他线程无法再获得到锁。
2、这把锁只能是非阻塞的,无论成功还是失败都直接返回。
3、这把锁是非重入的,一个线程获得锁之后,在释放锁之前,无法再次获得该锁,因为使用到的key在tair中已经存在。无法再执行put操作
解决办法:
没有失效时间?tair的put方法支持传入失效时间,到达时间之后数据会自动删除。
非阻塞?while重复执行。
非可重入?在一个线程获取到锁之后,把当前主机信息和线程信息保存起来,下次再获取之前先检查自己是不是当前锁的拥有者。
- 可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
- 使用缓存实现分布式锁的优点
性能好,实现起来较为方便。
- 使用缓存实现分布式锁的缺点
通过超时时间来控制锁的失效时间并不是十分的靠谱。
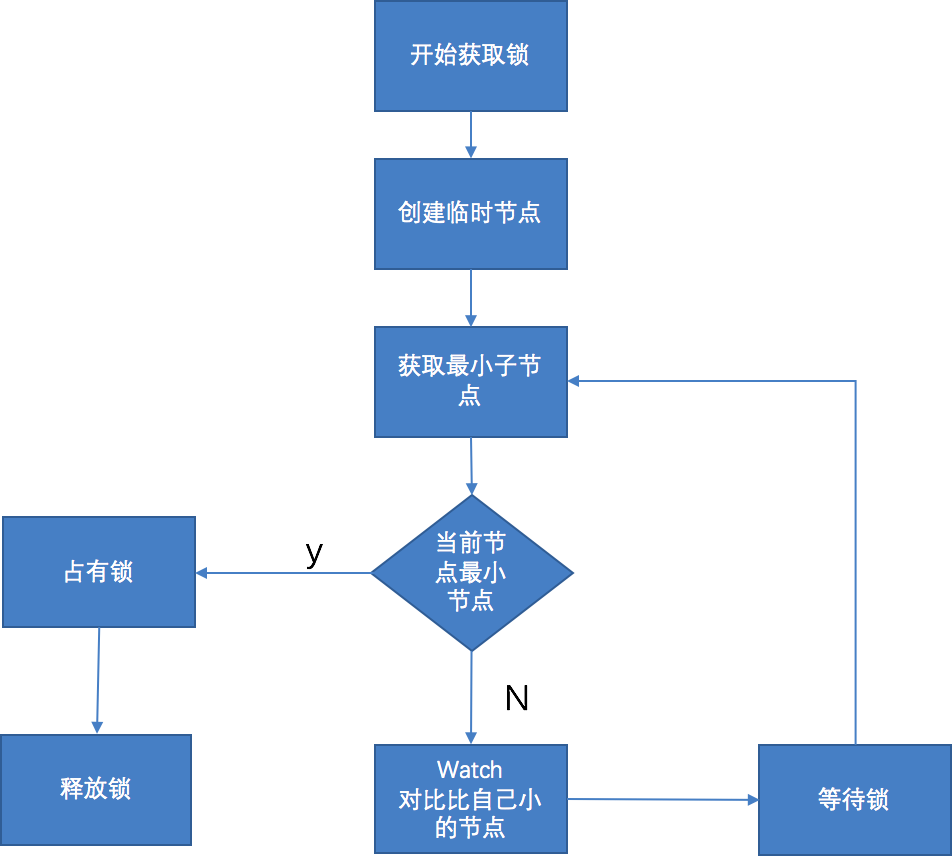
4、基于zookeeper
基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可下。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。