目录
multi-head attention VS masked multi-head attention
整体结构
Transformer是一个Sequence to Sequence的模型,主要的结构是encoder和decoder
完整的网络结构如图:
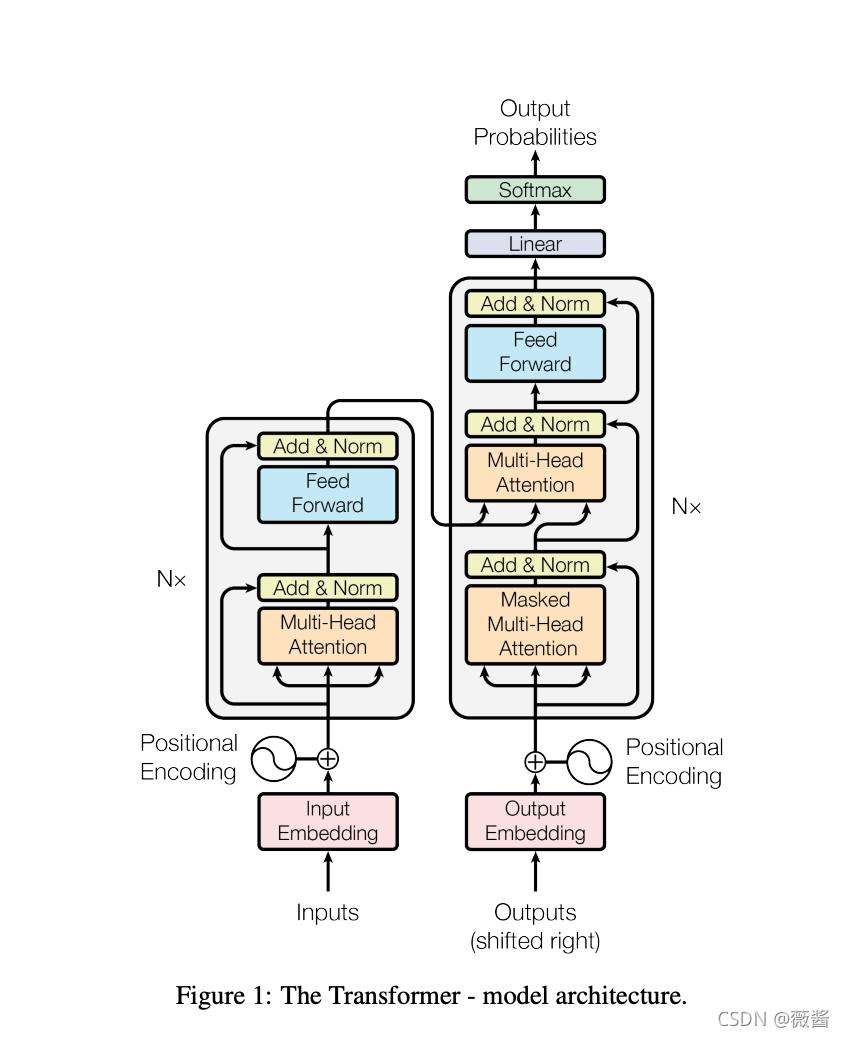
Encoder:
encoder对应整体结构图中的左边的部分,由好几个block组成,每个block里是好几层layer
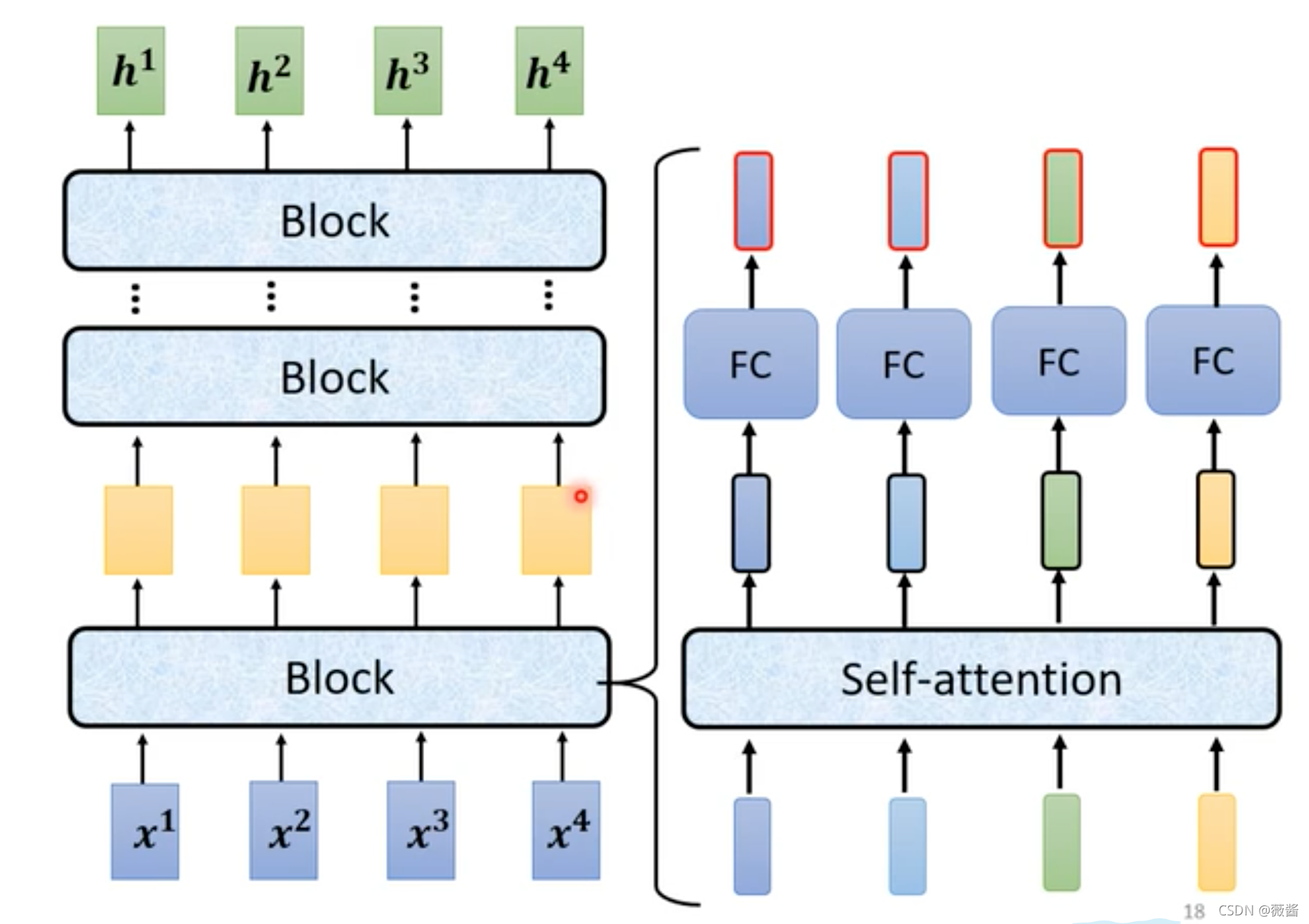
每一个block的结构:
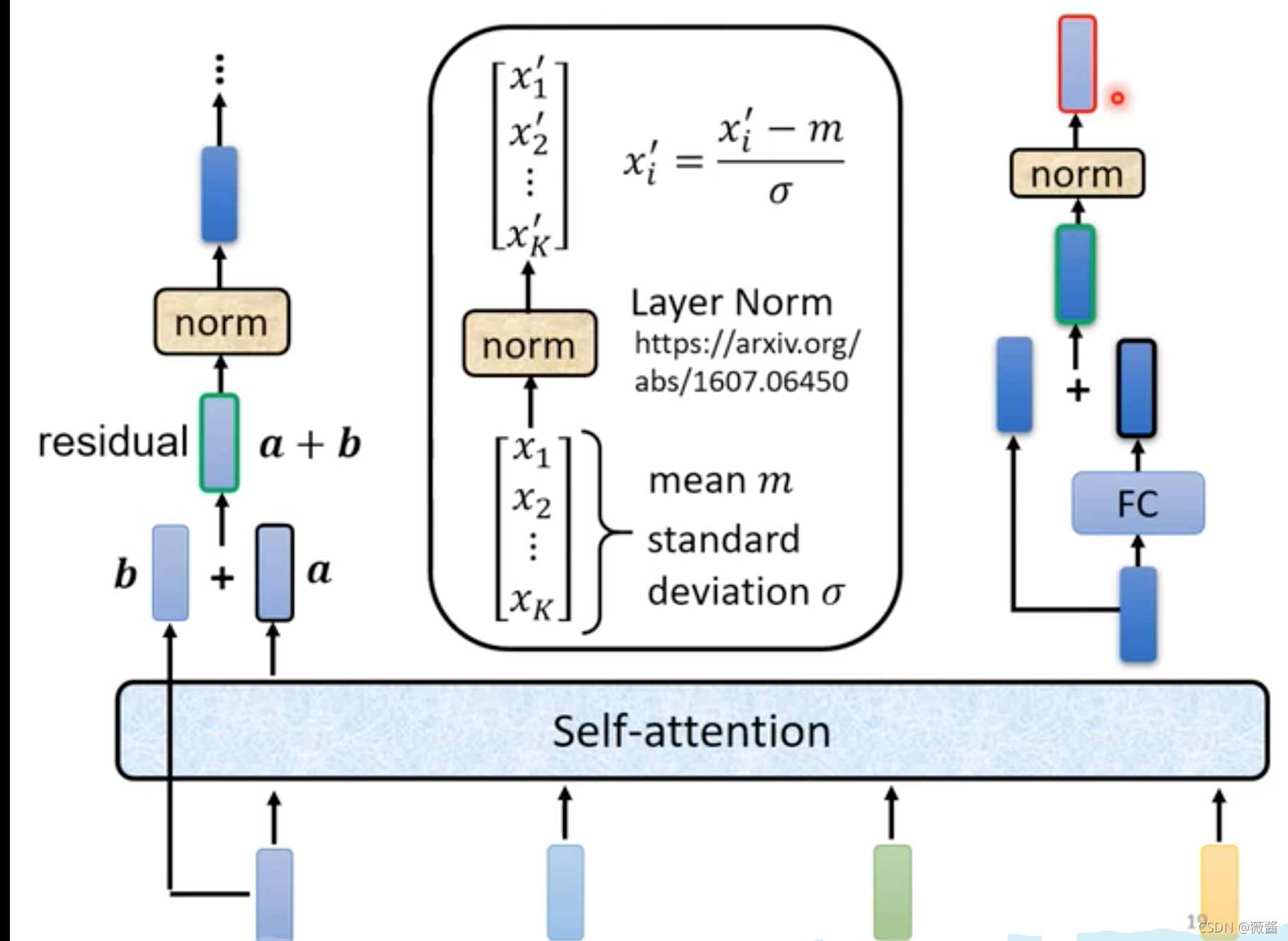
首先,输入一排vector,做self-attention之后,得到一排vector a,每一个vector都是考虑了所有输入的vector得到的结果,vector a再加上原先的vector b(这样的架构就是residual connection,残差),得到了一个新的output1。
第二步,将上一步得到的output再经过layer Normalization(LN,与batch Normlization的区别就是,BN是列标准化,LN是行标准化)得到output2
第三步,将第二步得到的结果output2通过全连接层(Fully Connected Feed Forward Network,FC),得到一个向量,再加上FC原先的输入,做一下residual,得到新的输出
最后,将第三步得到的结果再做一次LN,得到最终block的结果。
对应于整体的结构图,Add就是residual,Norm就是LN
Decoder:
decoder则是整体结构图右边的部分,分为2种,一种是AutoRegressive Decoder,另一种则是Non-AutoRegressive Decoder,两者的区别在于,AT预测的时候,除了使用encoder的结果,还会使用到之前预测的结果,是一个一个字依次预测的,而NAT的话,则是一次性预测整个句子。
Decoder-Autoregressive
 以语音识别为例:输出是所有中文词汇表+1(EOS,end of sentence,表示句子结束)大小的一个向量,输入是encoder和之前的预测结果,第一个字的话就是BOS,第二个字的输入就是encoder的结果+BOS+之前预测出来的机,预测结果经过softmax之后得到一个分布,取其中概率最大的字作为预测结果。
以语音识别为例:输出是所有中文词汇表+1(EOS,end of sentence,表示句子结束)大小的一个向量,输入是encoder和之前的预测结果,第一个字的话就是BOS,第二个字的输入就是encoder的结果+BOS+之前预测出来的机,预测结果经过softmax之后得到一个分布,取其中概率最大的字作为预测结果。
multi-head attention VS masked multi-head attention
encoder和decoder对比图:
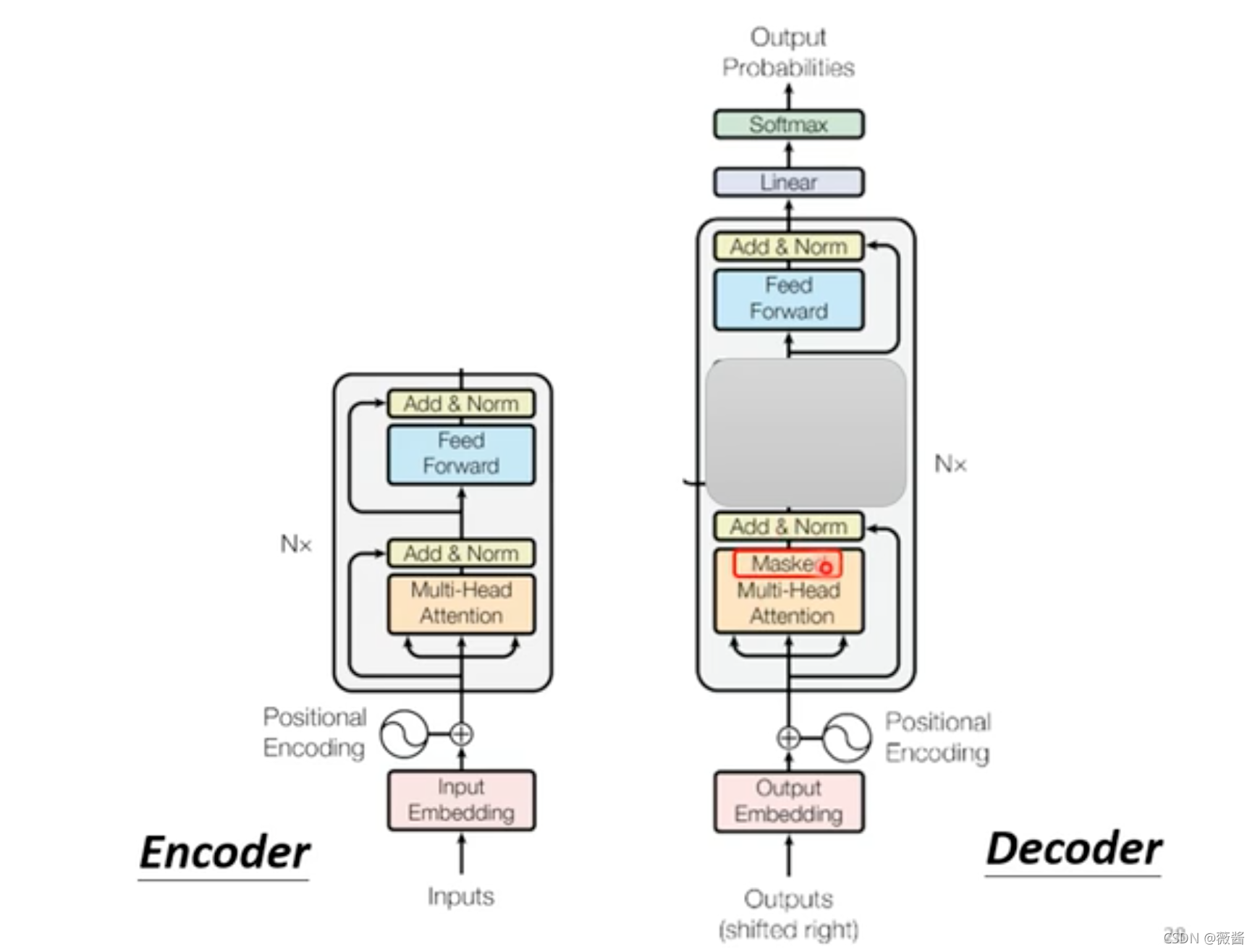
可以发现,除去中间的部分之后,encoder和decoder剩下的部分几乎是一样的,除了attention部分用的是masked multi-head attention。那masked 是指什么意思呢?
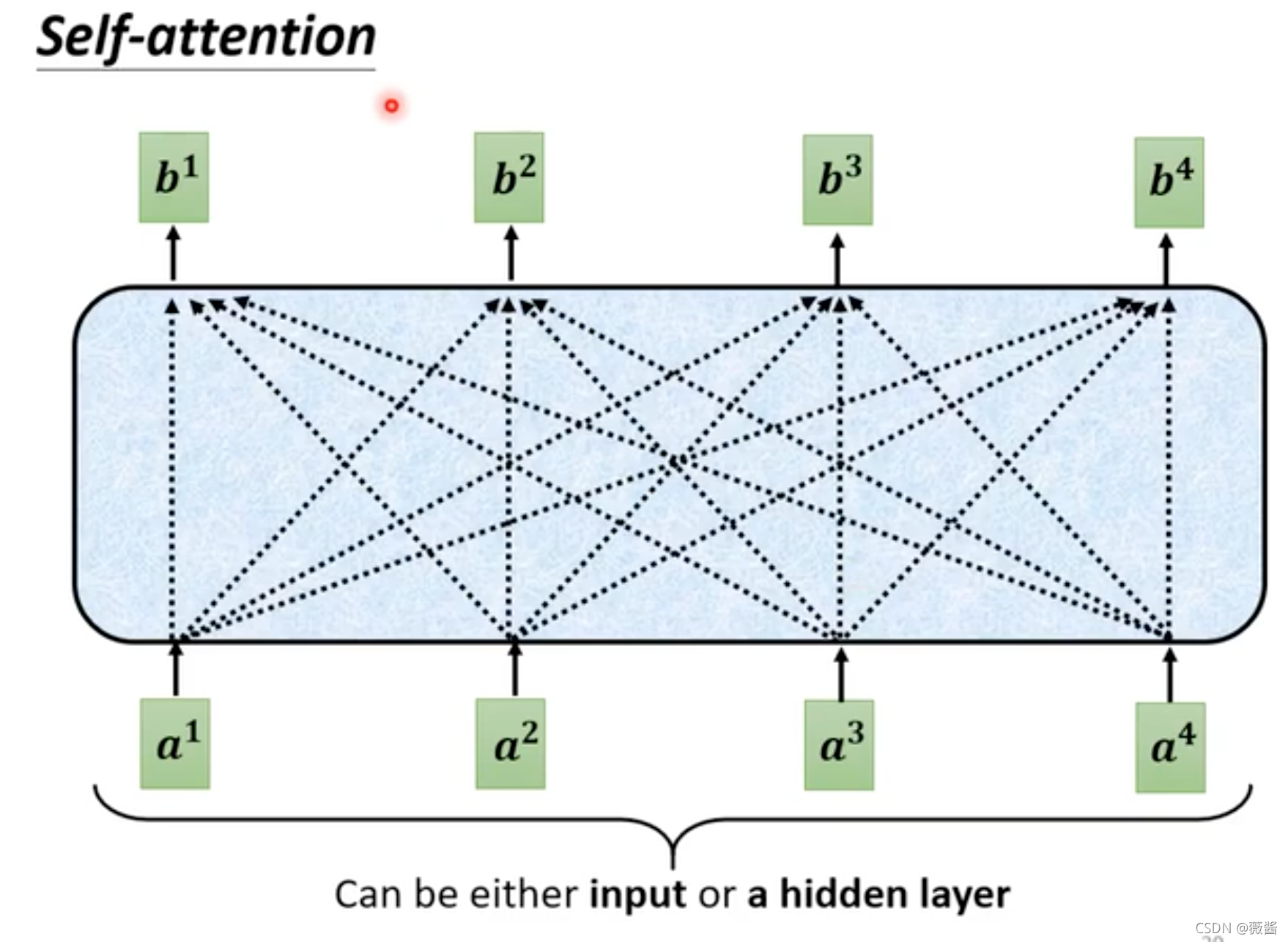
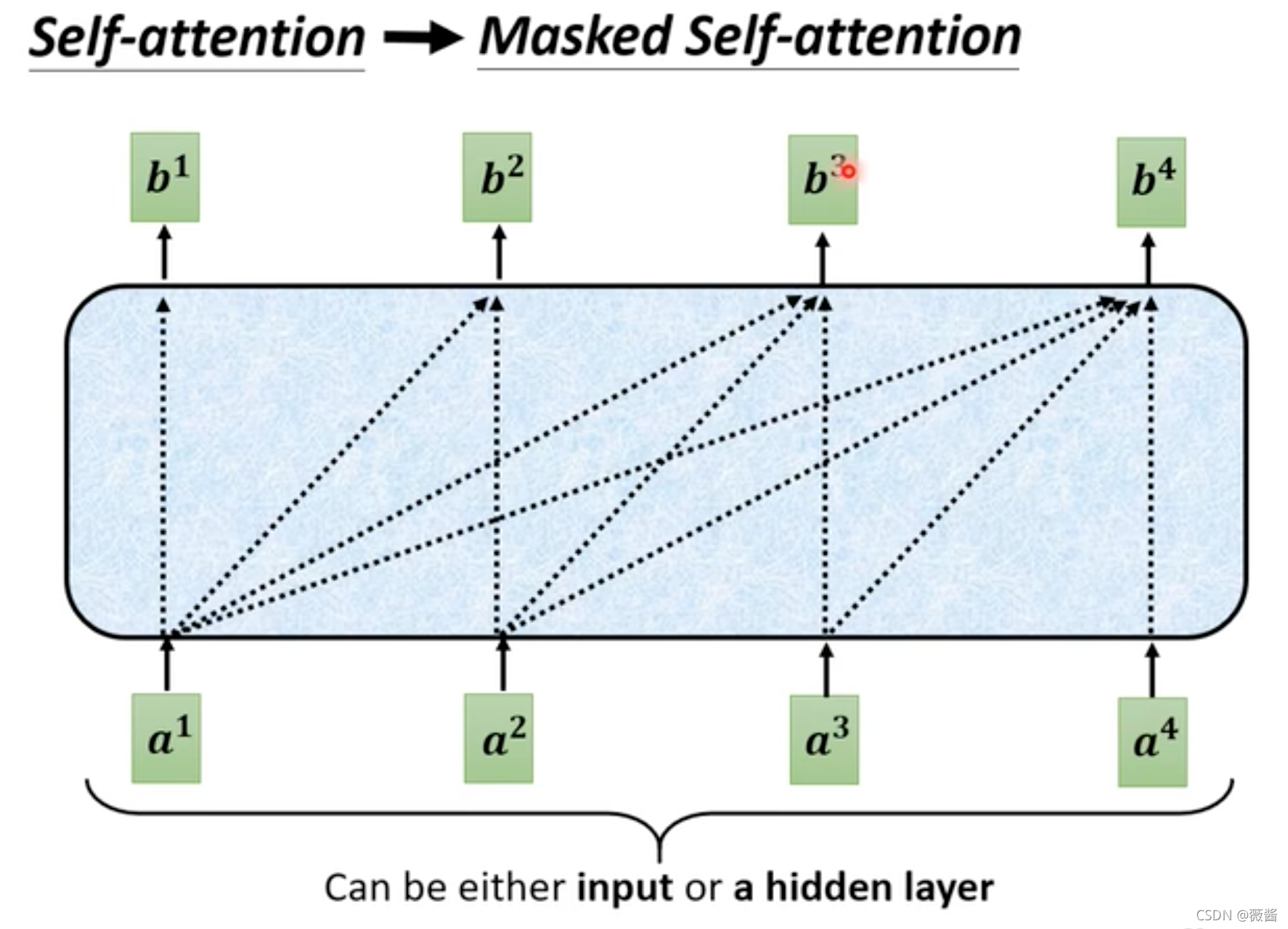
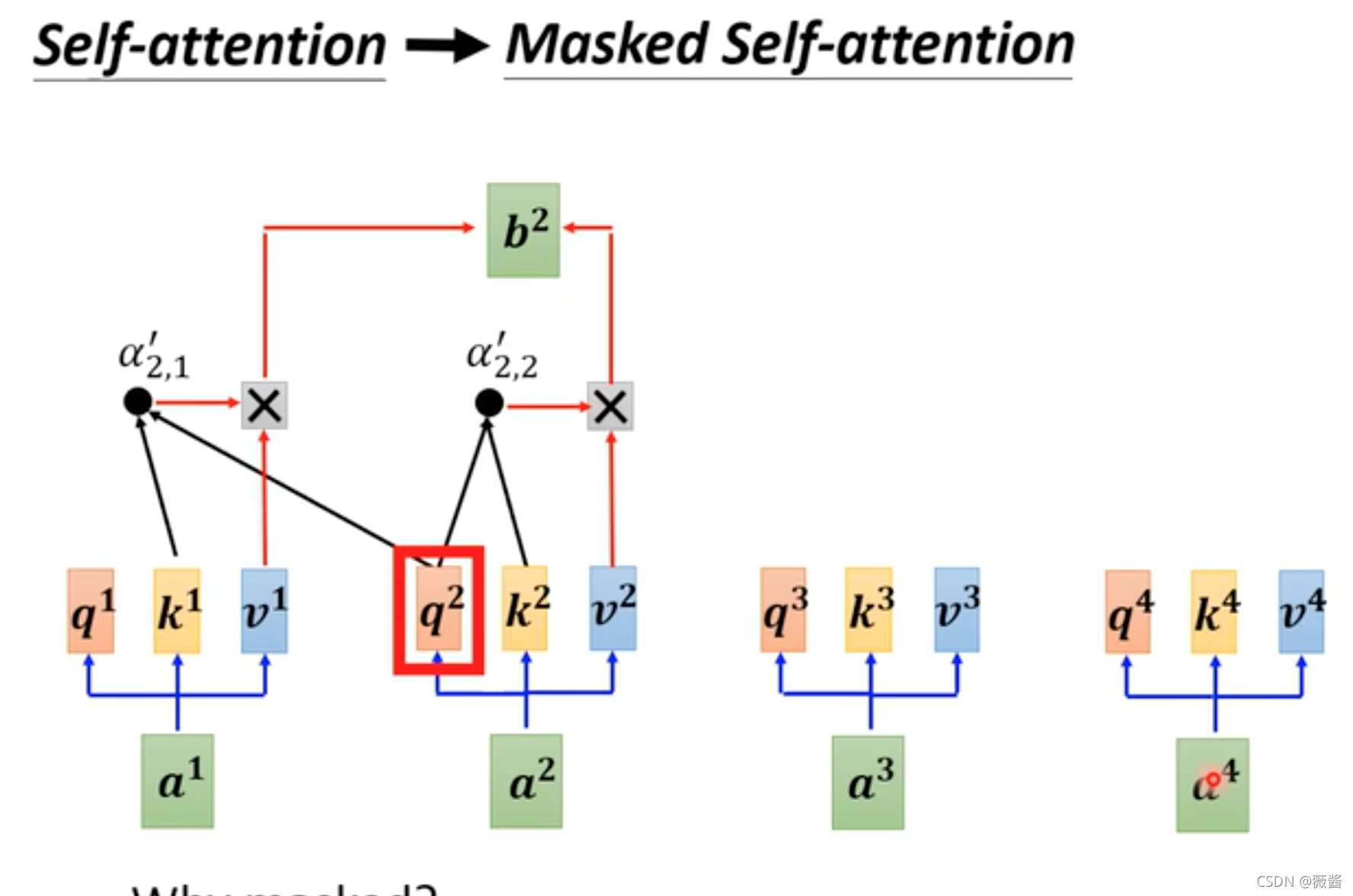
刚刚将AT的时候讲到,每一个字训练的时候,会使用到之前的数据,而self-attention 则是一开始就看到了所有的向量再做决定,决定训练出什么向量,而在mask attention则是每一个向量预测的时候,只能够看之前的向量的结果,而不能看之后向量的结果。
Decoder-Non-Autoregressive
AT vs NAT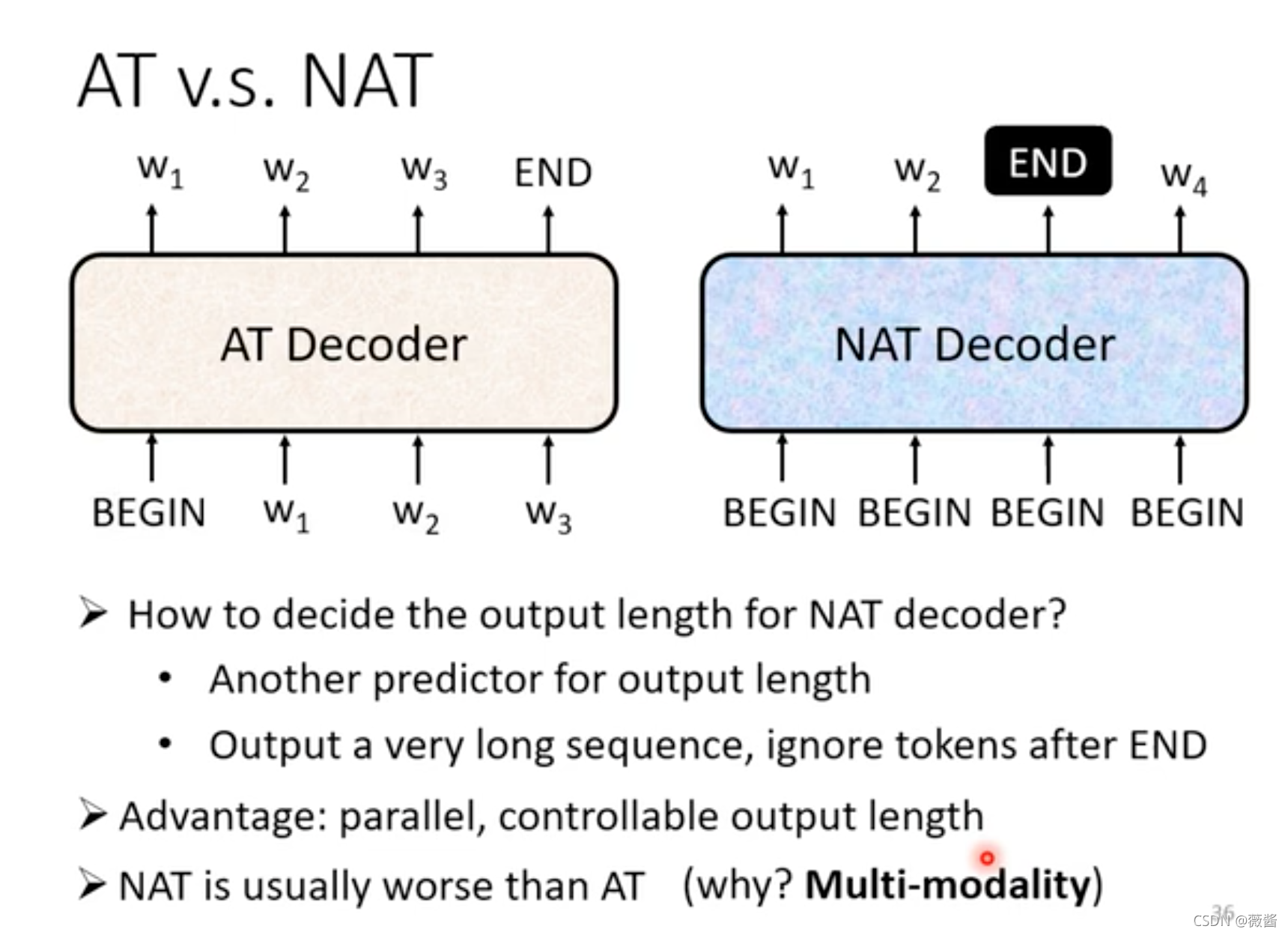
NAT:可以控制输出结果的长度,在语音合成时, 有一个分类器判断输出结果的长度,如果想要语速变快,就可以将分类器输出结果的长度除以2
Encoder和Decoder如何联合工作
在刚刚decoder的结构中,被遮挡住的,其实就是两者如何连接的部分。其实和self-attention的结构非常相似,只不过对应的q是来自于decoder,而k,v则是来自于encoder,这种结构我们称之为cross-attention
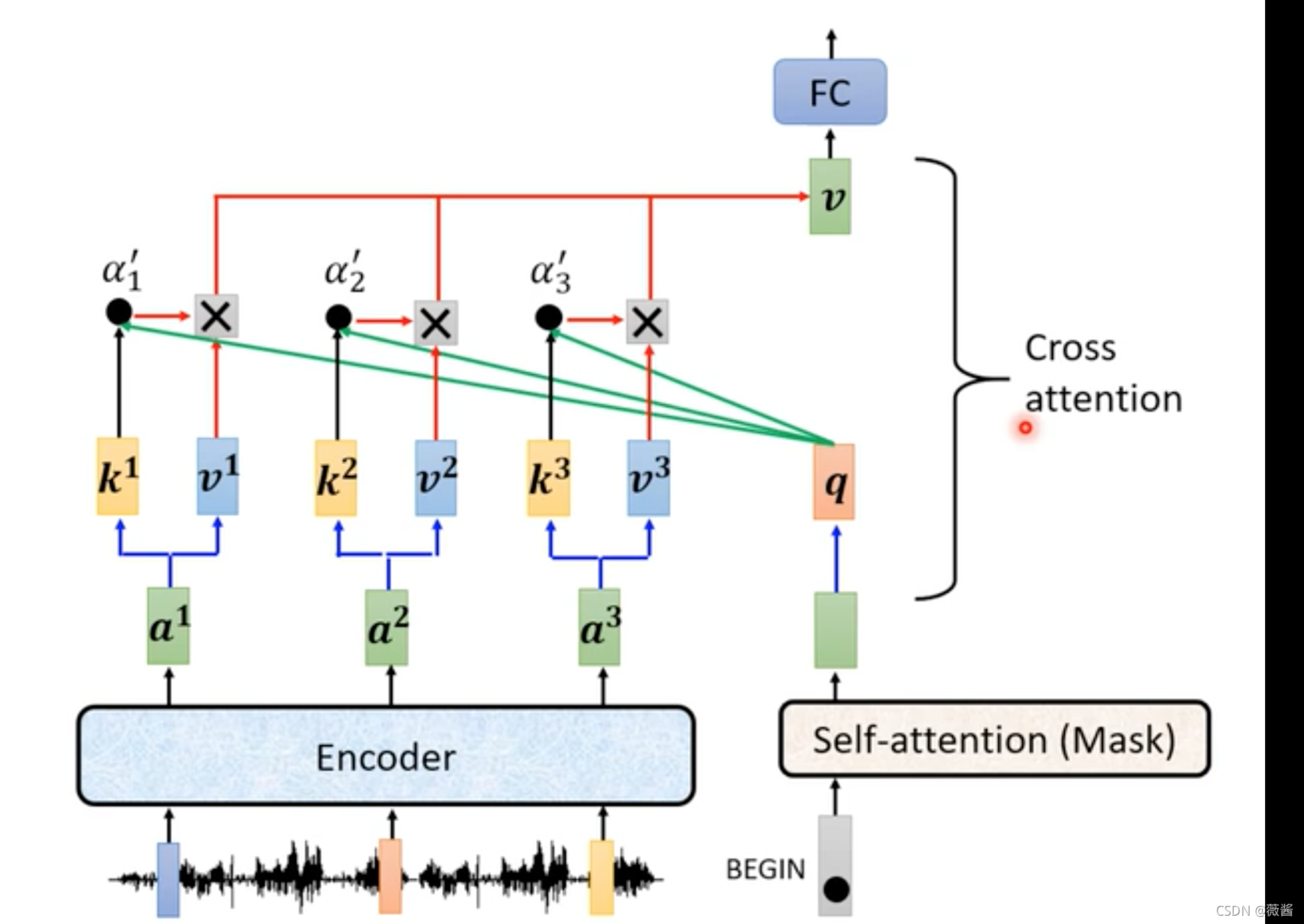
Training:
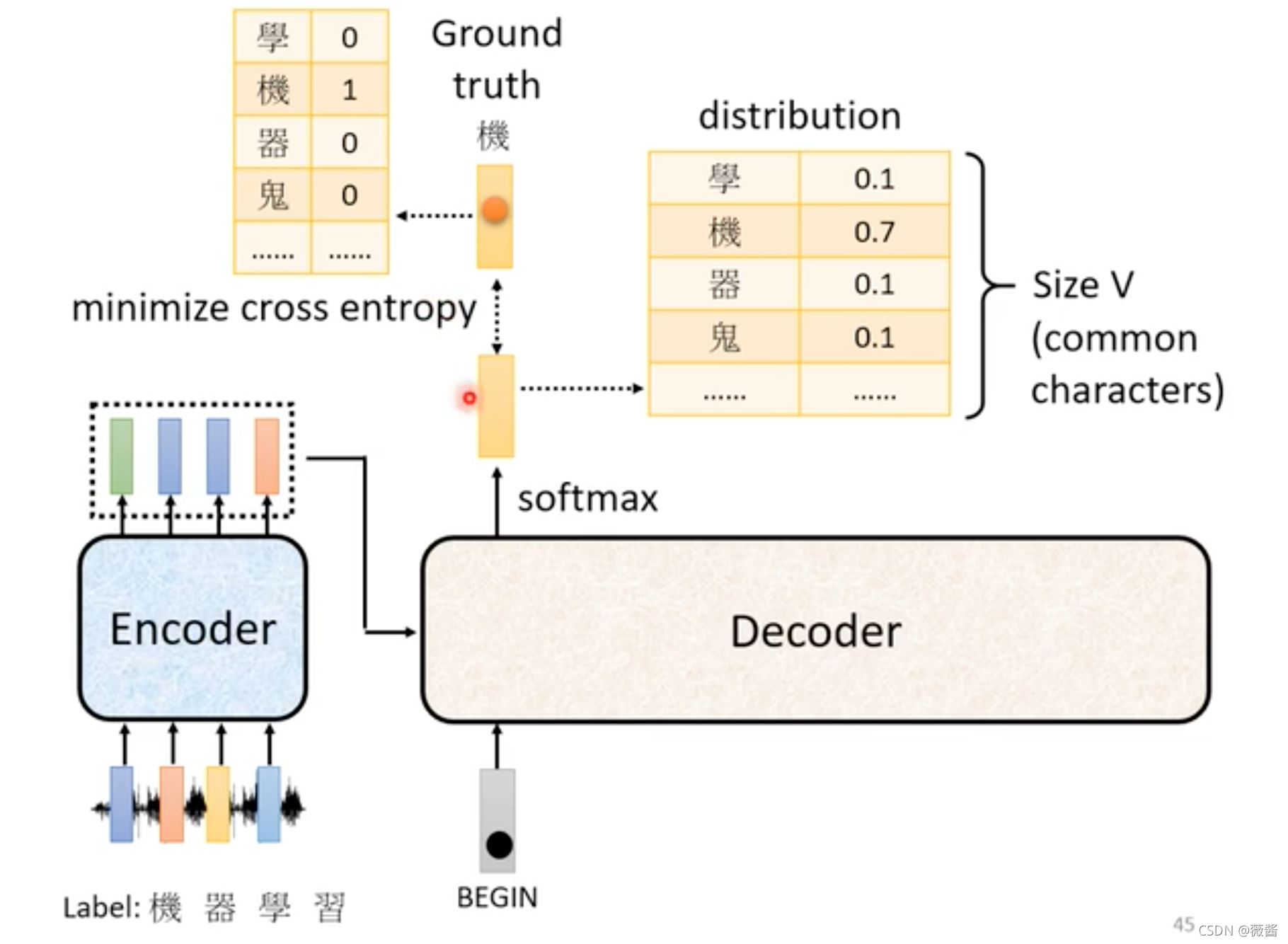
训练的目标是最小化输出的结果和原始结果之间的交叉熵
训练的时候使用的输入的是真实的数据,但是预测的时候使用的只能是之前预测出来的结果,这2者的不一致该如何解决呢?在训练时引入噪音,反而可以学的更好(Scheduled Sampling,下面会的技巧中会讲到)。
训练技巧
1.Copy Mechanism(复制机制),常见于对话机器人、摘要生成等工作
2.Guided Attention(引导注意力):引导机器做attention是有固定的方式的(比如语音合成,由左至右)
3.Beam Search(束搜索):相比于每次只保留最好的结果,beam search每次保留最好的k个结果。不一定每次都有效果,答案非常明确的工作(语音翻译这种),beam search会比较有帮助,需要创造力的那种,反而效果不好。
4.Scheduled Sampling():传统的Scheduled Sampling会伤害Transformer平行化的能力,所以有专门为transformer设计的Scheduled Sampling。https://arxiv.org/abs/1906.07651
评估指标
在validation set上,使用BLEU score而非交叉熵最高的那个模型。