Transformer详解
1. 简介
Transformer是一个面向sequence to sequence任务的模型,在17年的论文《Attention is all you need》中首次提出。Transformer 是第一个完全依赖自注意力(self-attention)来计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型。
1.1 Sequence to Sequence
简单地说就是输入一个向量,输出一个向量,两个向量长度不一定相等,如翻译任务等。Decoder这里要注意,其前面的输出会作为当前的输入,然后重复下去。
停止这个重复过程有AT(Autoregressive)和NAT(Non-autoregressive)两种方式。
AT:增加一个特殊的字符end,当输出为end,就停止
NAT:让模型输出一定长度的结果后截止,然后从中截取出需要的部分
2. Transformer网络结构
网络结构如下图所示,左边为编码器(encoder),右边为解码器(decoder)。
编码器:编码器是由N=6个相同的层堆叠而成。每层有两个子层。第一层是一个multi-head self-attention机制,第二层是一个简单的、按位置排列的全连接前馈网络。两个子层都采用了一个residual(残差)连接,然后进行层的归一化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是由子层本身的输出。
解码器:解码器也是由N=6个相同层的堆栈组成。除了每个编码器层的两个子层之外,解码器还插入了第三个子层,它对编码器堆栈的输出进行multi-head self-attention。与编码器类似,两个子层都采用了一个residual(残差)连接,然后进行层的归一化。为确保对位置i的预测只取决于小于i的位置的已知输出,修改了解码器堆栈中的multi-head self-attention层。
2.1 Self-attention
self-attention做的就是每一输出都与所有的输入有关,从而有效地利用上下文信息,如下图所示,a为输入,b为输出。
计算步骤:(以b1的计算为例)
q = Wq * a , k = Wk * a , v = Wv * a;其中Wq、Wk、Wv为三个矩阵(或向量),通过学习得到。
- q与各个输入点乘,得到了它们之间的相关性,即下图中的Alpha(可以理解成分数或权重),一般会再通过Soft-max
- v为各个输入的特征,各个Alpha与v相乘求和得到b1
- b2等的计算类似,最后易得其实就是矩阵运算

计算公式:
Q、K、V即上面的Wq、Wk、Wv,dk是缩放因子
除以dk的原因:点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域,除以一个缩放因子,可以一定程度上减缓这种情况。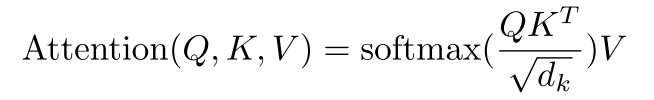
加上位置信息(Positional Encoding):
可以看到,上面各个输入之间没有位置信息,所以需要先进行positional encoding再进行计算,以利用位置信息。如下图所示,先给输入加上一个位置编码e,再计算attention。
位置编码e可以是认为设置,也可以尝试通过学习的方法得到。
2.2 Multi-head self-attention
Multi-head self-attention是self-attention的进阶版本,其实就是每个输入的q、k、v的数量变多,解决的是相关性的形式可能不是一种,所以想要提取到更多的相关性。
下面是Head=2时的示意图。
2.3 Masked Multi-head self-attention
self-attention计算了所有输入的相关性,但是有些任务中,输入是存在时间(或空间)差异的,即有的输入不需要与后面的输入计算相关性,所以采用masked的做法,遮掩其后面的输入。
如下图所示,b2只与a1和a2有关,与a3、a4无关。
2.4 Residual(残差)
Residual的做法就是将输入加到输出上,作为最后的输出,这种思想在Resnet中提出。
这样做的好处:解决了深度神经网络的退化问题,同等层数的前提下残差网络也收敛得更快(这里可以理解为通过计算残差,下一层中只需继续优化未匹配的地方,所以收敛快)
2.5 Layer normalization
Layer normalization是数据归一化的一种方式,计算均值和方差。即Transformer结构图中的Norm。
3. Self-attention与CNN、RNN的对比
3.1 优点
- Self-attention可并行计算
- CNN是Self-attention的一个子集
参考文献:
《On the Relationship between Self-Attention and Convolutional Layers》
《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》
3.2 缺点
attention只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。这种文本块会导致上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。