目录
1.背景
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库,比如:HBase,Redis,MySQL等。把事实数据写入流中,进行进一步处理,最终行成宽表。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
本文所采取的方案是将配置数据存入到MySQL数据库,使用FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
2.说明
- 全部代码采用Java语言编写
- 采用广播流连接配置表
- 采用FlinkCDC监控MySQL配置表和业务库读取变化数据
- HBase版本:2.0.5
- Phoenix版本:5.0.0
- Flink版本:1.13.1
3.相关工具类
kafka工具类
public class MyKafkaUtil {
private static String brokers = "hadoop1:9092,hadoop2:9092,hadoop3:9092";
private static String defaultTopic = "DWD_DEFAULT_TOPIC";
public static FlinkKafkaProducer<String> getKafkaProducer(String topic){
return new FlinkKafkaProducer<String>(brokers,topic,new SimpleStringSchema());
}
public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String groupID){
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupID);
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaConsumer<String>(topic,new SimpleStringSchema(),properties);
}
public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaProducer<T>(
defaultTopic,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
}配置信息表JavaBean
public class TableProcess {
//动态分流Sink常量
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
String sourceTable;
//操作类型 insert update delete
String operateType;
//输出类型 hbase kafka
String sinkType;
//输出表(主题)
String sinkTable;
//字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}4.FlinkCDC读取MySQL业务库数据
业务库数据包括了事实表和维度表,使用FlinkCDC进行监控,读取到整个数据库所有变更数据,并写入到kafka主题中(ods_base_db),供下游消费。
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//TODO 1 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 开启CK并指定状态后端为FS
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://hadoop1:8020/flink/checkpoints/gmall-flink"));
env.enableCheckpointing(5000L); //头和头
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); //尾和头
//TODO 2 通过FlinkCDC构建SourceFunction并获取数据
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop1")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-flink")
.deserializer(new MyStringDeserializationSchema())
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//TODO 3.打印数据并将数据写入kafka中去
streamSource.print();
String sinkTopic = "ods_base_db";
streamSource.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
//TODO 4.启动任务
env.execute("FlinkCDC");
}
}5.FlinkCDC读取配置表信息
配置表内容如下:
- source_table:业务表名称
- operate_type:操作类型(需要监控的操作)
- sink_type:输出到目标库中的表名称(hbase中以dim打头,kafka中以dwd打头)
- sink_columns:输出的字段列表
- sink_pk:表主键
- sink_extend:建表扩展内容

FlinkCDC读取配置表并处理广播流:
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop1")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-realtime")
.tableList("gmall-realtime.table_process")
.deserializer(new MyStringDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> tableProcessDS = env.addSource(sourceFunction);
MapStateDescriptor mapStateDescriptor = new MapStateDescriptor<String, TableProcess>("map-state", String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = tableProcessDS.broadcast(mapStateDescriptor);6.从Kafka中消费主流数据
获取主流数据
- 从kafka主题中读取数据
- 对数据进行结构的转换 String -> JSONObject(方便处理)
- 过滤删除操作
//TODO 2.消费ods_base_db主题数据,创建流
String sourceTopic = "ods_base_db";
String groupId = "base_db_app";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为json对象并过滤delete流
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS
.map(s -> JSON.parseObject(s))
.filter(new FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//取出数据的操作类型
String type = jsonObject.getString("type");
if ("delete".equals(type)) {
return false;
}
return true;
}
});7.主流连接广播流
主程序中:
- 连接主流和广播流
- 处理广播流数据,发送至主流,主流根据广播流的数据进行处理自身数据(分流)
- 打印侧输出流(hbase)和主流数据(kafka)
//TODO 5.连接主流和广播流
BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);
//TODO 6.分流 处理数据 广播流数据 主流数据(根据广播流数据进行处理)
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>("hbase-tag") {};
SingleOutputStreamOperator<JSONObject> kafka = connectedStream.process(new TableProcessFunction(hbaseTag, mapStateDescriptor));
//TODO 7.提取kafka流数据和hbase流数据
DataStream<JSONObject> hbase = kafka.getSideOutput(hbaseTag);
//TODO 8.将kafka数据写入kafka主题,将hbase写入phoenix表
kafka.print("kafka>>>>>>>>>");
hbase.print("hbase>>>>>>>>>");8.处理主流和广播配置流
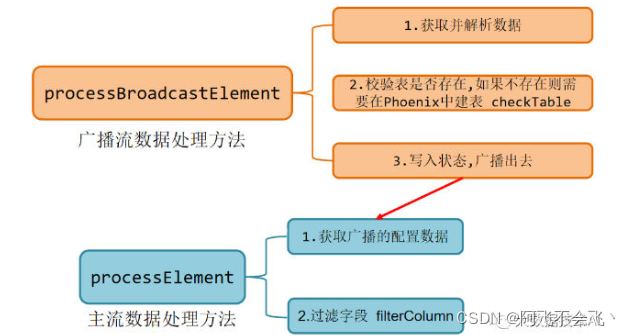
TableProcessFunction类:
1)构造方法TableProcessFunction()
- 传入侧输出流标签
- 传入状态描述器
2)open方法
- 获取Phoenix连接
3) 广播流处理方法processBroadcastElement()
- 将数据转换为JavaBean,方便处理
- 校验HBase表,如果不存在,则使用Phoenix创建
- 将数据写入状态,进行广播处理
4) 主流处理方法processElement()
- 从广播流中提取配置表信息
- 校验配置信息
- 根据sinkType类型字段,分流(kafka,hbase)
- 完善主流信息,将待写入的维表或者主题名称添加至数据中心
- 将要写入HBase的数据放入侧输出流
- 主流数据返回
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {
private OutputTag<JSONObject> objectOutputTag;
private MapStateDescriptor<String, TableProcess> mapStateDescriptor;
private Connection connection;
public TableProcessFunction(OutputTag<JSONObject> objectOutputTag, MapStateDescriptor<String, TableProcess> mapStateDescriptor) {
this.objectOutputTag = objectOutputTag;
this.mapStateDescriptor = mapStateDescriptor;
}
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
//广播流,用来写状态
//value:{"db":"","tn":"","before":{},"after":{},"type":""}
@Override
public void processBroadcastElement(String s, Context context, Collector<JSONObject> collector) throws Exception {
//1.获取并解析数据 String => JavaBean
JSONObject jsonObject = JSON.parseObject(s);
String data = jsonObject.getString("after");
TableProcess tableProcess = JSON.parseObject(data, TableProcess.class);
//2.检查HBase表是否存在并建表
if(TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())){
checkTable(tableProcess);
}
//3.写入状态(广播出去)
BroadcastState<String, TableProcess> broadcastState = context.getBroadcastState(mapStateDescriptor);
String key = tableProcess.getSourceTable() + "-" + tableProcess.getOperateType();
broadcastState.put(key, tableProcess);
}
//建表语句:create table if not exists db.tn(id varchar primary key,tm_name varchar) xxx;
private void checkTable(TableProcess tableProcess) {
PreparedStatement preparedStatement = null;
try {
if(tableProcess.getSinkPk() == null || tableProcess.getSinkPk().equals("")){
tableProcess.setSinkPk("id");
}
if(tableProcess.getSinkExtend() == null){
tableProcess.setSinkExtend("");
}
StringBuffer createTableSQL = new StringBuffer("create table if not exists ")
.append(GmallConfig.HBASE_SCHEMA)
.append(".")
.append(tableProcess.getSinkTable())
.append("(");
String[] fields = tableProcess.getSinkColumns().split(",");
for (int i = 0; i < fields.length; i++) {
String field = fields[i];
//判断是否为主键
if(tableProcess.getSinkPk().equals(field)){
createTableSQL.append(field).append(" varchar primary key");
}else{
createTableSQL.append(field).append(" varchar");
}
//判断是否是最后一个字段,如果不是则添加","
if(i < fields.length - 1){
createTableSQL.append(",");
}
}
createTableSQL.append(")").append(tableProcess.getSinkExtend());
//打印建表语句
System.out.println(createTableSQL);
//预编译sql
preparedStatement = connection.prepareStatement(createTableSQL.toString());
//执行
preparedStatement.execute();
} catch (SQLException e) {
throw new RuntimeException("Phoenix表" + tableProcess.getSinkTable() +"建表失败");
}finally {
if(preparedStatement!=null){
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//value:{"db":"","tn":"","before":{},"after":{},"type":""}
//主流,用来读状态(readonly)
@Override
public void processElement(JSONObject jsonObject, ReadOnlyContext readOnlyContext, Collector<JSONObject> collector) throws Exception {
//1.获取状态(获取广播状态)
ReadOnlyBroadcastState<String, TableProcess> broadcastState = readOnlyContext.getBroadcastState(mapStateDescriptor);
String key = jsonObject.getString("tableName") + "-" + jsonObject.getString("type");
TableProcess tableProcess = broadcastState.get(key);
if(tableProcess != null){
//2.分流
//将输出表/主题信息写入jsonObject
jsonObject.put("sinkTable", tableProcess.getSinkTable());
if(TableProcess.SINK_TYPE_KAFKA.equals(tableProcess.getSinkType())){
//kafka数据,写入主流
collector.collect(jsonObject);
}else if(TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())){
//HBase数据,写入侧输出流
readOnlyContext.output(objectOutputTag, jsonObject);
}
}else{
System.out.println("该组合key: "+ key + "不存在!");
}
}
}9.将侧输出流数据通过Phoenix写入HBase
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
connection.setAutoCommit(true);
}
//value:{"sinkTable":"dim_base_trademark","database":"gmall-flink","before":{"tm_name":"香奈儿","logo_url":"/static/default.jpg","id":11},
// "after":{"tm_name":"香奈","id":11},"type":"update","tableName":"base_trademark"}
@Override
public void invoke(JSONObject value, Context context) throws Exception {
PreparedStatement preparedStatement = null;
try{
//获取sql语句
String sinkTable = value.getString("sinkTable");
JSONObject after = value.getJSONObject("after");
String upsertSql = getUpsertSql(sinkTable, after);
System.out.println(upsertSql);
//预编译sql
preparedStatement = connection.prepareStatement(upsertSql);
//判断如果当前数据为更新操作,则先删除Redis中的数据
if("update".equals(value.getString("type"))){
DimUtil.delRedisDimInfo(sinkTable.toUpperCase(), after.getString("id"));
}
//执行
preparedStatement.executeUpdate();
}catch (SQLException e){
e.printStackTrace();
}finally {
if(preparedStatement != null){
preparedStatement.close();
}
}
}
//sql:upsert into db.tn(id,tm_name) values('','')
private String getUpsertSql(String sinkTable, JSONObject after) {
Set<String> keys = after.keySet();
Collection<Object> values = after.values();
return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" +
StringUtils.join(keys, ",") + ") values ('" +
StringUtils.join(values, "','") + "')";
}
}
10.将主流数据写入Kafka
kafka.addSink(MyKafkaUtil.getKafkaProducer(new KafkaSerializationSchema<JSONObject>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
return new ProducerRecord<byte[], byte[]>(jsonObject.getString("sinkTable"),
jsonObject.getString("after").getBytes());
}
}));11.完整主程序
public class BaseDBApp {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//TODO 2.消费ods_base_db主题数据,创建流
String sourceTopic = "ods_base_db";
String groupId = "base_db_app";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为json对象并过滤delete流
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS
.map(s -> JSON.parseObject(s))
.filter(new FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//取出数据的操作类型
String type = jsonObject.getString("type");
if ("delete".equals(type)) {
return false;
}
return true;
}
});
//TODO 4.使用flinkcdc消费配置表并处理成广播流
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop1")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-realtime")
.tableList("gmall-realtime.table_process")
.deserializer(new MyStringDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> tableProcessDS = env.addSource(sourceFunction);
MapStateDescriptor mapStateDescriptor = new MapStateDescriptor<String, TableProcess>("map-state", String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = tableProcessDS.broadcast(mapStateDescriptor);
//TODO 5.连接主流和广播流
BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);
//TODO 6.分流 处理数据 广播流数据 主流数据(根据广播流数据进行处理)
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>("hbase-tag") {
};
SingleOutputStreamOperator<JSONObject> kafka = connectedStream.process(new TableProcessFunction(hbaseTag, mapStateDescriptor));
//TODO 7.提取kafka流数据和hbase流数据
DataStream<JSONObject> hbase = kafka.getSideOutput(hbaseTag);
//TODO 8.将kafka数据写入kafka主题,将hbase写入phoenix表
kafka.print("kafka>>>>>>>>>");
hbase.print("hbase>>>>>>>>>");
hbase.addSink(new DimSinkFunction());
kafka.addSink(MyKafkaUtil.getKafkaProducer(new KafkaSerializationSchema<JSONObject>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
return new ProducerRecord<byte[], byte[]>(jsonObject.getString("sinkTable"),
jsonObject.getString("after").getBytes());
}
}));
//TODO 9.启动任务
env.execute("BaseDBApp");
}
}版权声明:本文为zhaozhufeng原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。