首先看下顶象的滑块:
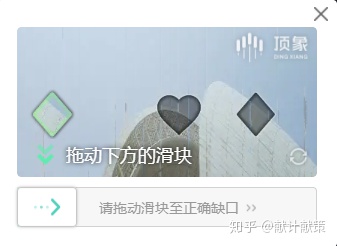
和市面上大部分正方形的滑块有区别的是,他的缺口是不规则的,增加了一个伪目标来混淆
在最初的时候,想到了最原始的识别方法,就是切割图像后,使用CV2的模板匹配进行识别:

res = cv2.matchTemplate(path_img, bg_image, cv2.TM_CCOEFF_NORMED)
value = cv2.minMaxLoc(res)然后发现,复杂一点的图片均识别失败了.错误率很高
于是想到使用深度学习来识别缺口的位置信息,这里使用YOLOv3
使用下面的模型来修改:
eriklindernoren/PyTorch-YOLOv3github.com
制作数据集:
既然使用深度学习来识别的话,那么,图片就不切割那么小了,直接使用原图片,压缩350*150大小来识别.这里的小方块使用了黑色背景与原图加权后合成,因为感觉本身目标的颜色相对于小方块的来说较深一些.
alpha = 0.45
beta = 1-alpha
gamma = 0
img_add = cv2.addWeighted(img1, alpha, img2, beta, gamma)之后就是这样子

没有使用labelimg直接转换的YOLO数据集,因为第一次标记了200 张,跑的时候总是莫名出错.
于是使用VOC来做数据集,然后手动转化VOC成YOLO的数据格式,这里的target只有一个:
0 0.6283333333333334 0.4466666666666667 0.17 0.32train.txt文件是用作训练的
ignore_thresh设置为0.7,可以设置到0.9,或者更高,更高的效果会好,但是0.7也没毛病,下面会解释
加载原始权重训练,加快拟合速度:
训练过程:
我使用CPU训练模型,100个Epoch跑了大概小半天.
后面用GPU大概不到一个小时就跑完了....
预测:
ignore_thresh 为0.7的时候,最好的模型在第40个Epoch,不过识别到的是这样:

使用了20 个样本要做预测,有6个是预测有错的,主要是有的一个图中预测到了2个目标
这个时候的解决办法是,提高置信度,将ignore_thresh设置为0.9或者更高,测试后的效果是20张中只有2张预测出错的.
也可以不更改ignore_thresh,直接在预测的2个结果中做对比,哪一个更加接近于真实的目标就选用哪一个,这样就不会出现2个目标了:
于是修改了预测代码:
if detections.shape[0] > 1:
detection0 = detections[0,:]
detection1 = detections[1,:]
score0=detection0[-2].item()
score1=detection1[-2].item()
if score0>score1:
detections=detection0.unsqueeze(0)
else:
detections=detection1.unsqueeze(0)达到的效果:

就只有一个预测值了