常见数据库
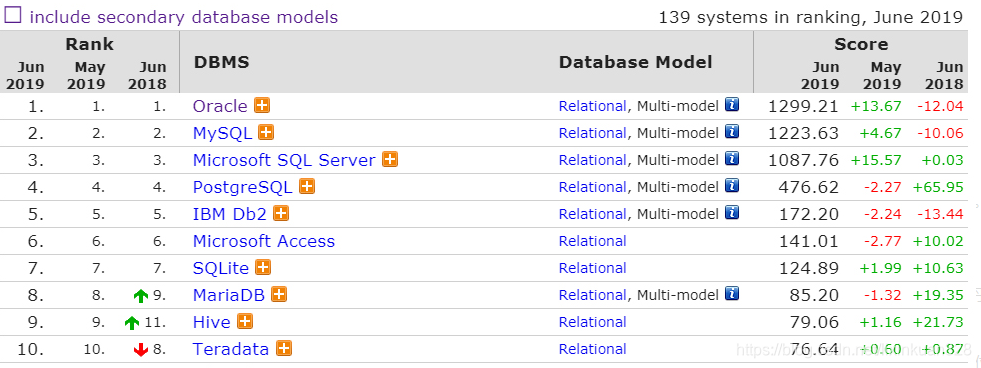
关系型数据库:
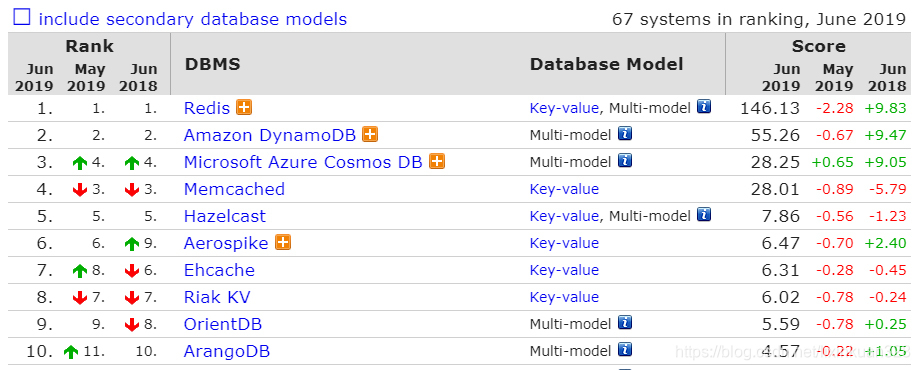
非关系型数据库:
一、cmd操作数据库:
1、以管理员身份运行cmd
2、net start MariaDB //运行MariaDB10.5.9
3、net stop MariaDB //停止MariaDB10.5.9
3、mysql -u用户名 -p密码
连接本地mysql服务器
-u后面用户名,-t后面密码
可以先mysql -uroot -p,然后输密码
4、mysql -h127.0.0.1 -uroot -proot //连接异地mysql
5、exit //退出程序
6、quit //退出程序
7、语句的注释:
单行:--(后面跟空格) 或 #(mysql特有)
多行:/*...*/
二、idea链接数据库
8.5以后的版本需要指定时区
MySQLjdbc:mysql://localhost:3306/nacos_config?serverTimezone=Asia/Shanghai&characterEncoding=utf8:
三、SQL语句分类:
是结构化查询语言,专门用来操作数据库的语言.是一种标准化语言,可以操作各种数据库产品.
分类:
DML 数据操作语言 , 对数据进行CRUD
DDL 数据库定义语言 , 创建库 , 创建表,修改表结构
DCL 数据库控制语言 , 管理操作数据库的权限
DQL 数据库查询语言,对数据发起查询需求
四、基础语法
1、其他语法
IF(expr1,expr2,expr3) -- if语法SELECT count(1) from information_schema.COLUMNS WHERE table_schema='库名' and table_name='表名'; -- 查看表中字段数量
SELECT VERSION() -- 查看mysql的版本号2、数据库操作基础语法
1、show create database mysql(或数据库名); -- 查询创建mysql的语法,主要用来查看字符集.
2、create database 数据库; -- 创建数据库
3、drop database 数据库; -- 删除数据库
4、create database if not exists 数据库; -- 如果不存在,创建 数据库 //A哥rei 死
5、drop database if exists 数据库; -- 如果存在,删除数据库。
6、create database 数据库 character set 字符集; -- 创建数据库,指定字符集 //凯瑞科特
7、alter database 数据库 character set gbk; -- 修改数据库字符集
8、show databases; -- 查看所有数据库
9、select database(); -- 查询正在使用的数据库
10、use 数据库; -- 进入数据库
-- 判断是否存的语句也适用于创建表删除表的操作.(if exists/if not exists)
注释:除了数字类型,其他类型都要用引号(单双都行)引起3、表的基本语法
1、set names gbk; -- 解决中文乱码方案(固定写法)
2、show tables; -- 查看所有表
3、create table 表名(字段名 字段类型(长度) , 2 ,3,4,…); -- 创建表
4、drop table 表名; -- 删除表
5、create table 表 like 被复制的表; -- 复制表
6、alter table 表 rename to 新表明; -- 修改表的名字
7、show create table 表; -- 查看表的字符集
8、alter table 表 character set 字符集; -- 修改表的字符集
9、alter table 表 add 列名 类型; -- 向表中添加新列
10、alter table 表 drop 列名; -- 删除表中某列
11、alter table 表 change 列名 新列名 数据类型; --修改列名
12、alter table 表 modify 列名 新数据类型; --修改某列类型
13、desc 表名; -- 描述表
14、insert into 表名(列1,列2) values(值1,值2),(); -- 向表中添加值,可以同时添加多行.
15、update 表名 set 字段名=新值,字段名=新值 , .... [where 条件]; -- 修改表中数据
16、delete from 表名 where 条件; -- 删除指定行,删除所有内容效率低,使用下面方法
17、truncate table 表名;--删除表,创建一个一样的空表//串kei的 4、表查询方法:
1、select distinct 列1 from 表名; -- 去重查询 2、select 列1,列2,列1+列2 from 表名; -- 将两列相加生成新列
注释1:如果有nul类型参与运算,结果都为null
解决方法:ifnull(列2,0) -- 如果为null,变为0
注释2:将合起来的两列重新起名子
解决方法:列1+列2 as 新名 as可用空格代替
注释3:如果两列为int类型,合并取和,两列为string类型,合并为新字符串3、select * from 表名 [where 条件] ; -- 条件查询
条件符号 >、<、>=、<=、!=(<>)、&&、||、and、or
与where相连的关键字:
between...and -- 在...之间(适用于int类型)
in(元素1,元素2,...) -- 包含于
not in(元素1,元素2,...) -- 不包含于
is null -- 查询为null值,对于null查询不能用等号
is not null -- 查询不为null值
like 模糊查询
not like 不包含某某
_ :表示单个任意字符
% :表示多个任意字符
%1%: 表示包含1
%1:以1结尾
1%:以1开头4、order by 字段1 排序方式1,字段2 排序方式2
排序查询,只有当方式一相同时才会使用方式二,汉字按照编码表顺序排序,默认升序排序 asc 升序 desc 降序5、基础常用函数
lower(列):数据转小写
upper(列):数据转大写
length(列):求数据长度 汉字utf8占3个字符
replace(列,目标字符串,替换成):替换
substr(列,开始索引,截取长度):截取 -- 索引1开始,截取长度可省略
ifnull(列,替换成):将null替换成目标字符串
concat(列,字符串):拼接
round(列,number) 四舍五入、ceil(列,number) 向上取整、floor(列,number) 向下取整
now():获取当前系统年月日 可以直接select now()
year(日期字符串/now())、month()、day()、hour、minute、second
date_format(日期列,”%Y-%m”)-- 日期格式化
转义字符\:修饰字符串中特殊字符6、聚合函数
注意:①所有聚合函数都会排除null类型
②聚合列和普通列不进行分组不能写在一起
1、count :计算个数 select count(ifnull(列1,0)) from 表;
count(*)包括了所有的列,不会忽略NULL
count(1) 会统计表中的所有的记录数,不会忽略NULL,效率高
count(列名) 会统计该列字段在表中出现的次数,忽略字段为NULL
2、max:最大数
3、min:最小数
4、sum:求和
5、avg:平均值7、分组查询
group by //将某列一样的分为一组,再用聚合函数做数学操作
SELECT mgr,AVG(sal) FROM emp where sal>4000 GROUP BY mgr
SELECT mgr,AVG(sal) FROM emp where sal>4000 GROUP BY mgr having AVG(sal)>5000
注意事项:
①参与的列为分组列或者聚合函数列
②加where可以对参加分组成员进行限制,作用在分组之前
③having作用于分组之后,将符合的组进行筛选
④where后不能跟聚合函数,having后可跟聚合函数.8、分页查询 -->方言
limit 开始的索引,每页查询的条数
select * from 表名 limit 1,3;
每页索引开始公式:(第几页(当前页码) - 1) * 每页显示条数
select * from 表名 limit 2; -- 取表中前两条数据9、switch函数
SELECT
CASE
DLDJ
WHEN 1 THEN
'快速路'
WHEN 2 THEN
'主干路'
WHEN 3 THEN
'次干路' ELSE '支路'
END AS DLDJ,
COUNT( ID ) AS roadNum,
SUM( DLMJ ) AS DLMJ,
SUM( DLCD ) AS DLCD
FROM
basic_road_info
GROUP BY
DLDJ五、约束
主键约束:primary key 非空且唯一 //普ruai么瑞
非空约束: not null
唯一约束:unique //u内口
外键约束:foreign key //fao 润
默认约束:default 规定字段默认值
检查约束:check 例子:
新语句 check(age>0 and age<200)
show index from 表名; -- 查看索引,主键会自动创建索引
Ⅰ、主键约束
1、添加主键 alter table 表 modify 列名 新数据类型 primary key
2、删除主键 alter table 表名 drop primary key
Ⅱ、自动增长
1、主键自动增长 alter table 表 modify 列名 新数据类型 auto_increment
注意事项:主要和主键约束配合使用, 主键列添加值时写入null表示自动增加,也可手动赋值
2、删除自动增长 alter table 表 modify 列名 新数据类型
Ⅲ、非空约束
1、添加非空约束 alter table 表 modify 列名 新数据类型 nut null
2、删除非空约束 alter table 表 modify 列名 新数据类型;
Ⅳ、唯一约束
唯一约束限定的值可以有多个null值
1、添加唯一约束 alter table 表 modify 列名 新数据类型 unique
2、删除唯一约束 alter table 表名 drop index 列名
Ⅴ、外键约束
为了解耦,一般不使用外键约束
1、添加外键
constraint 外键名称 foreign key(子表外键列名称) references 主表(主表主键列名称)注意事项:
①主表主键列名称也可以是被唯一约束的列名称
②constraint 外键名称 语句在创建时可以省略,系统会自动分配一个外键名
2、单独添加外键
alter table 表名 add constraint 外键名 foreign key (子表外键列名称) references 主表(主表主键列名称)3、删除外键: alter table 表名 drop foreign key 外键名
4、删除数据: 必须先删除子表数据,在删除主表数据
5、级联操作: 子表外键列的值可以为null值或者主表列中的值
修改关联字段的值
(1)、设置级联更新:
①先删除外键约束 ②设置级联更新-->修改值
alter table 表名 add constraint 外键名 foreign key (子表外键列名称) references 主表(主表主键列名称) on update cascade #就可以在主表更新值了 凯斯kei的(2)、级联删除-->删除值
alter table 表名 add constraint 外键名 foreign key (子表外键列名称) references 主表(主表主键列名称) on delete cascade注意事项:级联更新和级联删除可以同时进行
七、视图-->当作一张虚拟表
作用:视图是基于 SQL 语句的结果集的可视化的表。下次还要发起相同的sql,直接查视图
优点:使用视图,可以简化数据操作。
缺点: ①性能差。②修改限制
创建语法:CREATE VIEW视图名 AS sql语句
使用视图:select * from 视图名;
八、数据库设计
Ⅰ、多表关系
1、一对一 人和身份证
可以在任意一方添加唯一外键指向另一个方主键
2、多对一(一对多) 部门里有多个员工 一个员工对应一个部门
在多的一方建立外键,指向一的主键
3、多对多 课程和学生 一个课程多个学生学 一个学生学多个课程
需要一个中间表,命名规则 表一名字_表二名字
中间表至少包含两个字段,这两个字段作为中间表的外键,分别指向两张表的主键.
中间表表的主键 primary key(字符1,字段2) 叫联合主键
Ⅱ、范式
范式:设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
1、第一范式(1NF)
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的原子数据项.
2、第二范式(2NF)
在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分的函数依赖)
概念解析:
①函数依赖:如果通过A属性或属性组的值,可以确定唯一的B属性的值,则称B依赖于A
例如:A(学号) -->B姓名 A(学号,课程名称) --> B分数
②完全依赖:B属性的值的确定依赖于A属性组中全部的值
例如:A(学号,课程名称) -->B分数
③不完全依赖:B属性的值的确定不完全依赖A属性组的全部值
例如:A(学号,课程名称) -->B姓名
④传递函数依赖:A-->B ,B-->C .如果通过A属性或属性组的值,可以唯一确定B属性的值,在通过
B属性或属性组的值可以唯一去顶C属性的值,就称C传递函数依赖于A
⑤码:如果在一张表中,一个属性或属性组,被其他所有属性完全依赖,则称这个属性或属性组为该表的码
主属性:码属性中所有的属性 非主属性:除了码属性外的属性
3、第三范式(3NF)
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
九、数据库的备份和还原
命令行:
- 备份:mysqldump -u用户名 -p密码 数据库名 > 保存的路径
- 还原: ①登录数据库
②创建数据库
③进入数据库
④执行文件 source 文件路径 //扫死
十、多表连查
-->小表驱动大表,从而让性能更优
查询两个表,A和B的数据 -->笛卡尔积,又称’直积‘,共A×B条数据,会产生冗余数据
消除冗(rong)余数据的方法
1、内连接
①隐式内连接-->又叫笛卡尔积,效率最低
使用where过滤无用信息
语法:select 字段列表 from 表1,表2 where 表关系+条件
②显式内连接 左边小表
语法:select 字段列表 from 表名1 join 表名2 on 表关系
1、on 后跟表关系 2、如果有条件,on后加where
inner join 可以简写为join
2、外连接
①左外连接
select 字段列表 from 表1 left join 表2 on 表关系
注释:查询左表中所有信息及其交集部分
②右外连接
select 字段列表 from 表1 right join 表2 on 表关系
注释:查询右表中所有信息及其交集部分
3、子查询,可以进行多表查询也可单表查询
select语句里面嵌套select语句,里面的select叫子查询
子查询多种查询结果:
①单行单列:
子查询作为条件,查询运算符为 := < > 等等
SELECT * FROM emp WHERE sal = (SELECT MAX(sal) FROM emp)
SELECT * FROM emp WHERE sal < (SELECT AVG(sal) FROM emp)
②多行单列
子查询作为条件,查询运算符为in
SELECT * FROM emp WHERE deptno IN(SELECT a FROM b WHERE epassword = "济宁" OR epassword = "广州")
③多行多列
子查询作为一张虚拟表
SELECT * FROM b t1,(SELECT * FROM emp WHERE hiredate > "2015-09-01") t2 WHERE t1.a=t2.deptno
十一、事务
1、概念:
包含多个步骤的业务,被事务管理,这些操作要么全部成功,要么全部失败
2、使用事务步骤:
①开启事务 start transaction;//穿rai可新
②写事务步骤
③如果结果有问题,则回滚 rollback;/肉百克
④如果结果没问题,则提交 commit;//抗密特
在默认情况下,MySQL每执行一条SQL语句,都是一个单独的事务。如果需要在一个事务中包含多条SQL语句,那么需要手动开启事务和结束事务。
3、事务提交
mysql默认自动提交
oracle默认手动提交
修改事务提交方式:
查看:select @@autocommit -- 0代表手动提交1代表默认提交
修改:set @@autocommit = 0;
4、事物的四大特征
①原子性:各个步骤不可分割,同时失败,同时成功
②持久性:当事物提交或者回滚,数据库内容发生永久变化
③隔离性:多个事物之间相互独立
④一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
5、事物的隔离级别(了解)

十二、数据库管理
1、管理用户
查询用户:
切换到mysql数据库 use mysql
查询user表 select * from user
创建新用户:
create user“用户名”@”主机名” identified by“密码”;
主机名可以用%号代替,表示该用户可在所有主机下登录
删除用户:
drop user “用户名”@“主机名”
2、修改密码
①update user set password=password(“新密码”) where user=“用户名”;
②set password for “用户名”@“主机名”=password(“新密码”)
找回root用户的密码方法:
①打开cmd ,net stop mysql停止mysql服务
②使用无验证方式启动mysql服务: mysqld --skip-grant-tables
③打开新的cmd窗口,直接输入mysql,敲回车就可登录成功
④选中mysql数据库,修改user表中密码
⑤关闭两个窗口
⑥打开任务管理器,手动结束mysql.exe的进程
3、权限管理
查询权限
show grants for “用户名”@“主机名”授予权限
grant 权限列表 on 数据库名.表名 to “用户名”@”主机名”授予所有权限
grant all on *.* to “用户名”@”主机名”
all代表所有权限,*代表所有库和表撤销权限
revoke 权限列表 on 数据库名.表名 from “用户名”@“主机名”撤销所有权限
revoke all on *.* from “用户名”@“主机名”4、开放其他ip访问权限
mysql默认只能本机连接
开放此权限需要修改mysql库中user表中root用户的Host为%号
然后重启

十三、数据库数据类型
1、整型
MySQL数据类型 | 含义(有符号) |
tinyint(m) | 1个字节 范围(-128~127) //台泥 |
smallint(m) | 2个字节 范围(-32768~32767) |
mediumint(m) | 3个字节 范围(-8388608~8388607) |
int(m) | 4个字节 范围(-2147483648~2147483647) |
bigint(m) | 8个字节 范围(+-9.22*10的18次方) |
2、浮点型(float和double)
MySQL数据类型 | 含义 |
float(m,d) | 单精度浮点型8位精度(4字节) ,m总个数,d小数位数 |
double(m,d) | 双精度浮点型 16位精度(8字节) m总个数,d小数位 |
3、定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。 //带设猫
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位。
4、字符串(char,varchar,_text)
MySQL数据类型 | 含义 |
char(n) | 固定长度,最多255个字符,查询效率高 |
varchar(n) | 可变长度,最多65535个字符,剩余空间节省出来。大文本使用 |
tinytext | 可变长度,最多255个字符 |
text | 可变长度,最多65535个字符 |
mediumtext | 可变长度,最多2的24次方-1个字符 |
longtext | 可变长度,最多2的32次方-1个字符 |
5.日期时间类型
MySQL数据类型 | 含义 |
date | 日期 '2008-12-2'h |
time | 时间 '12:25:36' |
datetime | 日期时间 '2008-12-2 22:06:44' |
timestamp | 自动存储记录修改时间//死代母坡 |
6、数据类型的属性
MySQL关键字 | 含义 |
NULL | 数据列可包含NULL值 |
NOT NULL | 数据列不允许包含NULL值 |
DEFAULT | 默认值 |
PRIMARY KEY | 主键 |
AUTO_INCREMENT | 自动递增,适用于整数类型 |
UNSIGNED | 无符号 |
CHARACTER SET name | 指定一个字符集 |
十四、sql优化
查询SQL尽量不要使用select *,而是具体字段
反例:SELECT * FROM student
正例:SELECT id,NAME FROM student
理由:
字段多时,大表能达到100多个字段甚至达200多个字段
只取需要的字段,节省资源、减少网络开销
select * 进行查询时,很可能不会用到索引,就会造成全表扫描
避免在where子句中使用or来连接条件
反例:SELECT * FROM student WHERE id=1 OR salary=30000
正例:# 分开两条sql写
SELECT * FROM student WHERE id=1
SELECT * FROM student WHERE salary=30000
理由:
使用or可能会使索引失效,从而全表扫描
对于or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描。也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定。虽然mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的
使用varchar代替char
反例:`deptname` char(100) DEFAULT NULL COMMENT '部门名称'
正例:`deptname` varchar(100) DEFAULT NULL COMMENT '部门名称'
理由:
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间
char按声明大小存储,不足补空格
其次对于查询来说,在一个相对较小的字段内搜索,效率更高
尽量使用数值替代字符串类型
主键(id):primary key优先使用数值类型int,tinyint
性别(sex):0-代表女,1-代表男;数据库没有布尔类型,mysql推荐使用tinyint
支付方式(payment):1-现金、2-微信、3-支付宝、4-信用卡、5-银行卡
服务状态(state):1-开启、2-暂停、3-停止
商品状态(state):1-上架、2-下架、3-删除
查询尽量避免返回大量数据
如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。同时,大量数据返回也可能没有实际意义。如返回上千条甚至更多,用户也看不过来。
通常采用分页,一页习惯10/20/50/100条。
对于一定的数据量使用索引
SQL很灵活,一个需求可以很多实现,那哪个最优呢?SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引。
EXPLAIN
SELECT * FROM student WHERE id=1
优化like语句
模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效
反例: EXPLAIN SELECT id,NAME FROM student WHERE NAME LIKE '%1' EXPLAIN SELECT id,NAME FROM student WHERE NAME LIKE '%1%'正例: EXPLAIN SELECT id,NAME FROM student WHERE NAME LIKE '1%'
优化字符串的使用
反例: #未使用索引 EXPLAIN SELECT * FROM student WHERE NAME=123正例: #使用索引 EXPLAIN SELECT * FROM student WHERE NAME='123'为什么第一条语句未加单引号就不走索引:
因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为数值类型再做比较
索引不宜太多,一般5个以内
索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率
索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间
再者,索引表的一个特点,其数据是排序的,那排序要不要花时间呢?肯定要
insert或update时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定
一个表的索引数最好不要超过5个,若太多需要考虑一些索引是否有存在的必要
索引不适合建在有大量重复数据的字段上
如性别字段。因为SQL优化器是根据表中数据量来进行查询优化的,如果索引列有大量重复数据,Mysql查询优化器推算发现不走索引的成本更低,很可能就放弃索引了。
避免在where子句中使用!=或<>操作符
应尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。记住实现业务优先,实在没办法,就只能使用,并不是不能使用。如果不能使用,SQL也就无需支持了。