
1
前言训练深度学习模型,就像“炼丹”,模型可能需要训练很多天。
我们不可能像「太上老君」那样,拿着浮尘,24 小时全天守在「八卦炉」前,更何况人家还有炼丹童、天兵天将,轮流值守。

2
初级“法宝”,sys.stdout 训练模型,最常看的指标就是 Loss。我们可以根据 Loss 的收敛情况,初步判断模型训练的好坏。 如果,Loss 值突然上升了,那说明训练有问题,需要检查数据和代码。 如果,Loss 值趋于稳定,那说明训练完毕了。 观察 Loss 情况,最直观的方法,就是绘制 Loss 曲线图。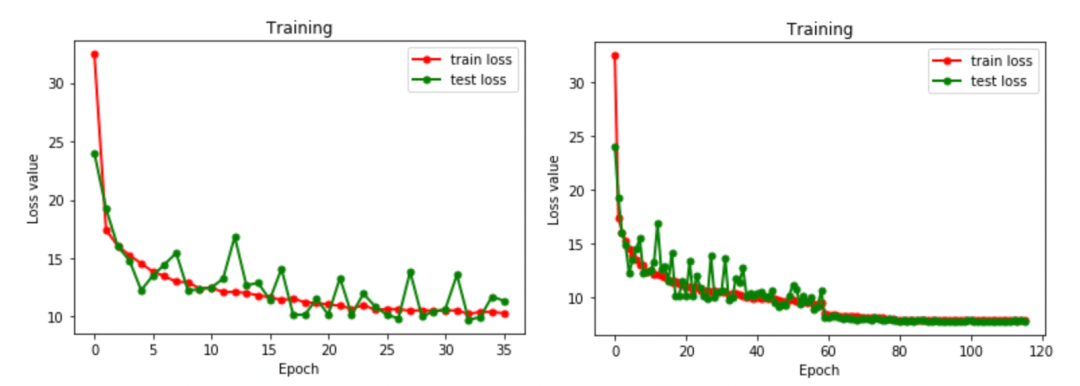
import osimport sysclass Logger(): def __init__(self, filename="log.txt"): self.terminal = sys.stdout self.log = open(filename, "w") def write(self, message): self.terminal.write(message) self.log.write(message) def flush(self): passsys.stdout = Logger()print("Jack Cui")print("https://cuijiahua.com")print("https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA")
3
中级“法宝”,matplotlib Matplotlib 是一个 Python 的绘图库,简单好用。 简单几行命令,就可以绘制曲线图、散点图、条形图、直方图、饼图等等。 在深度学习中,一般就是绘制曲线图,比如 Loss 曲线、Acc 曲线。 举一个,简单的例子。 使用 sys.stdout 保存的 train_loss.txt,绘制 Loss 曲线。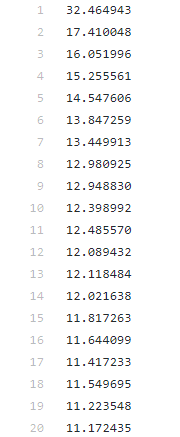
import matplotlib.pyplot as plt# Jupyter notebook 中开启# %matplotlib inlinewith open('train_loss.txt', 'r') as f: train_loss = f.readlines() train_loss = list(map(lambda x:float(x.strip()), train_loss))x = range(len(train_loss))y = train_lossplt.plot(x, y, label='train loss', linewidth=2, color='r', marker='o', markerfacecolor='r', markersize=5)plt.xlabel('Epoch')plt.ylabel('Loss Value')plt.legend()plt.show()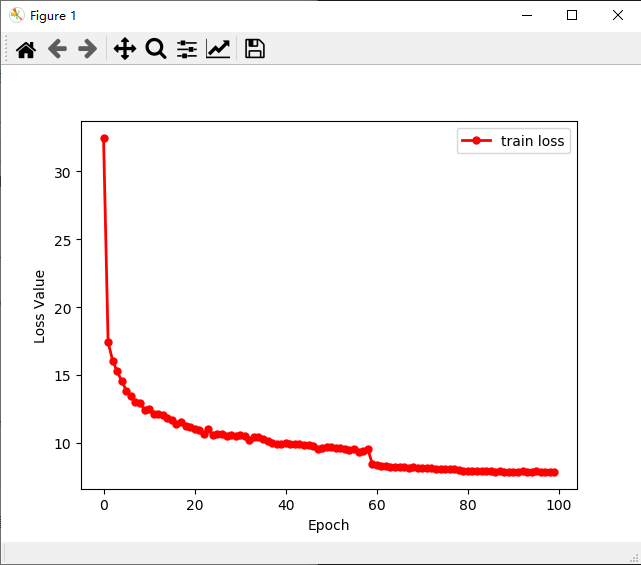
4
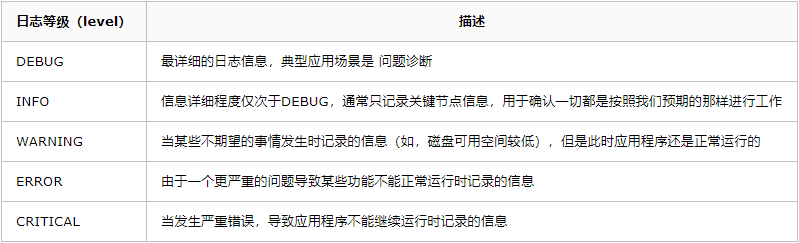
中级“法宝”,Logging 说到保存日志,那不得不提 Python 的内置标准模块 Logging,它主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等,同时,我们也可以设置日志的输出格式。import loggingdef get_logger(LEVEL, log_file = None): head = '[%(asctime)-15s] [%(levelname)s] %(message)s' if LEVEL == 'info': logging.basicConfig(level=logging.INFO, format=head) elif LEVEL == 'debug': logging.basicConfig(level=logging.DEBUG, format=head) logger = logging.getLogger() if log_file != None: fh = logging.FileHandler(log_file) logger.addHandler(fh) return loggerlogger = get_logger('info')logger.info('Jack Cui')logger.info('https://cuijiahua.com')logger.info('https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA')
import logginglogging.debug("debug_msg")logging.info("info_msg")logging.warning("warning_msg")logging.error("error_msg")logging.critical("critical_msg")WARNING:root:warning_msgERROR:root:error_msgCRITICAL:root:critical_msg默认的日志格式为日志级别:Logger名称:用户输出消息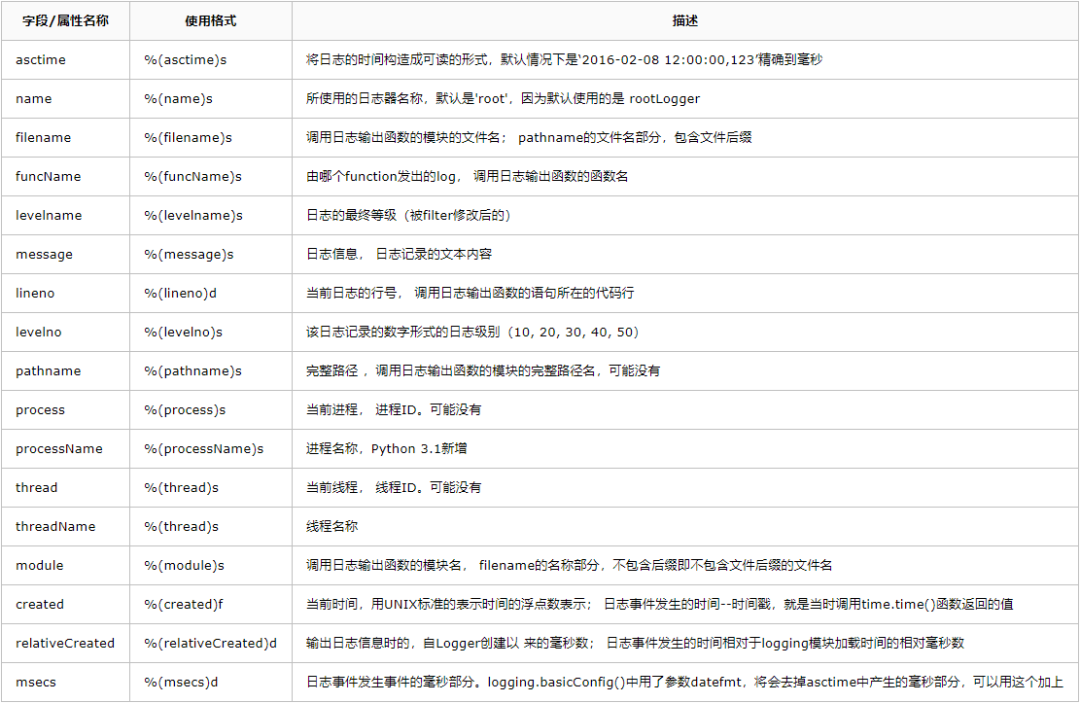
5
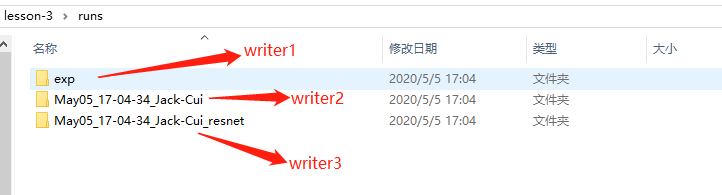
高级“法宝”,TensorboardX 上文介绍的“法宝”,并非针对深度学习“炼丹”使用的工具。 而 TensorboardX 则不同,它是专门用于深度学习“炼丹”的高级“法宝”。 早些时候,很多人更喜欢用 Tensorflow 的原因之一,就是 Tensorflow 框架有个一个很好的可视化工具 Tensorboard。 Pytorch 要想使用 Tensorboard 配置起来费劲儿不说,还有很多 Bug。 Pytorch 1.1.0 版本发布后,打破了这个局面,TensorBoard 成为了 Pytorch 的正式可用组件。 在 Pytorch 中,这个可视化工具叫做 TensorBoardX,其实就是针对 Tensorboard 的一个封装,使得 PyTorch 用户也能够调用 Tensorboard。 TensorboardX 安装也非常简单,使用 pip 即可安装,需要注意的是 Pytorch 的版本需要大于 1.1.0。pip install tensorboardXfrom tensorboardX import SummaryWriter# 创建 writer1 对象# log 会保存到 runs/exp 文件夹中writer1 = SummaryWriter('runs/exp')# 使用默认参数创建 writer2 对象# log 会保存到 runs/日期_用户名 格式的文件夹中writer2 = SummaryWriter()# 使用 commet 参数,创建 writer3 对象# log 会保存到 runs/日期_用户名_resnet 格式的文件中writer3 = SummaryWriter(comment='_resnet')提供一个路径,将使用该路径来保存日志
无参数,默认将使用 runs/日期_用户名 路径来保存日志
提供一个 comment 参数,将使用 runs/日期_用户名+comment 路径来保存日志
add_scalar(tag, scalar_value, global_step=None, walltime=None)tag (string): 数据名称,不同名称的数据使用不同曲线展示
scalar_value (float): 数字常量值
global_step (int, optional): 训练的 step
walltime (float, optional): 记录发生的时间,默认为 time.time()
from tensorboardX import SummaryWriter writer = SummaryWriter('runs/scalar_example')for i in range(10): writer.add_scalar('quadratic', i**2, global_step=i) writer.add_scalar('exponential', 2**i, global_step=i)writer.close()tensorboard --logdir=runs/scalar_example --port=8088http://localhost:8088/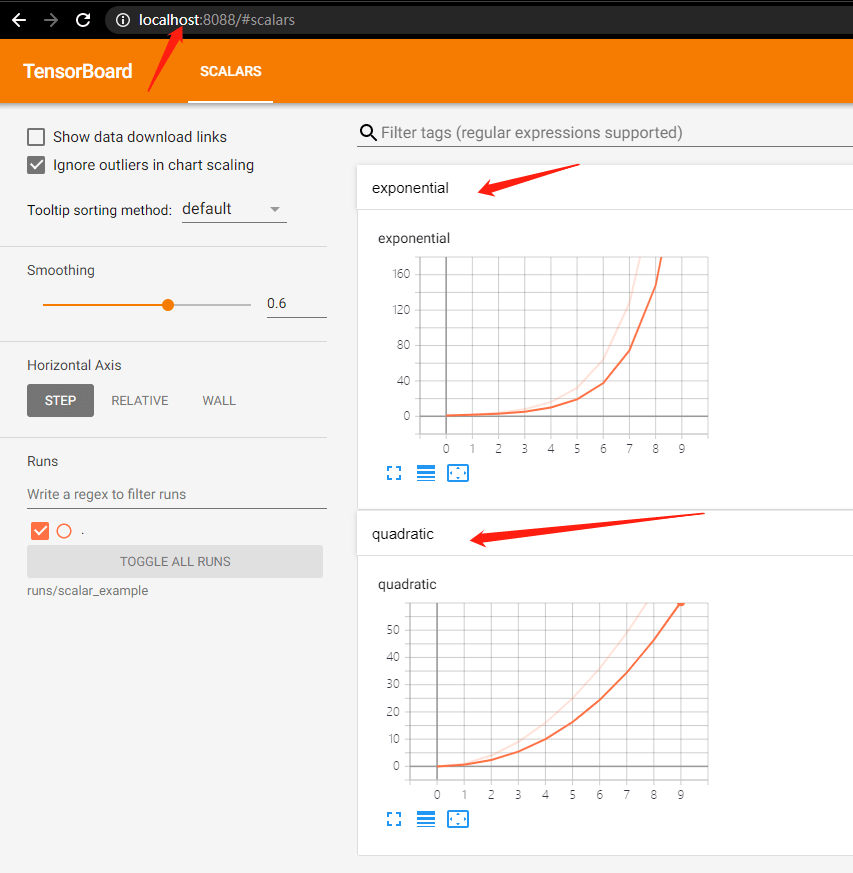
图片 (image)
使用 add_image 方法来记录单个图像数据。注意,该方法需要 pillow 库的支持。add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')tag (string):数据名称
img_tensor (torch.Tensor / numpy.array):图像数据
global_step (int, optional):训练的 step
walltime (float, optional):记录发生的时间,默认为 time.time()
dataformats (string, optional):图像数据的格式,默认为 'CHW',即 Channel x Height x Width,还可以是 'CHW'、'HWC' 或 'HW' 等
我们一般会使用 add_image 来实时观察生成式模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型。
from tensorboardX import SummaryWriterfrom urllib.request import urlretrieveimport cv2urlretrieve(url = 'https://raw.githubusercontent.com/Jack-Cherish/Deep-Learning/master/Pytorch-Seg/lesson-2/data/train/label/0.png',filename = '1.jpg')urlretrieve(url = 'https://raw.githubusercontent.com/Jack-Cherish/Deep-Learning/master/Pytorch-Seg/lesson-2/data/train/label/1.png',filename = '2.jpg')urlretrieve(url = 'https://raw.githubusercontent.com/Jack-Cherish/Deep-Learning/master/Pytorch-Seg/lesson-2/data/train/label/2.png',filename = '3.jpg')writer = SummaryWriter('runs/image_example')for i in range(1, 4): writer.add_image('UNet_Seg', cv2.cvtColor(cv2.imread('{}.jpg'.format(i)), cv2.COLOR_BGR2RGB), global_step=i, dataformats='HWC')writer.close()tensorboard --logdir=runs/image_example --port=8088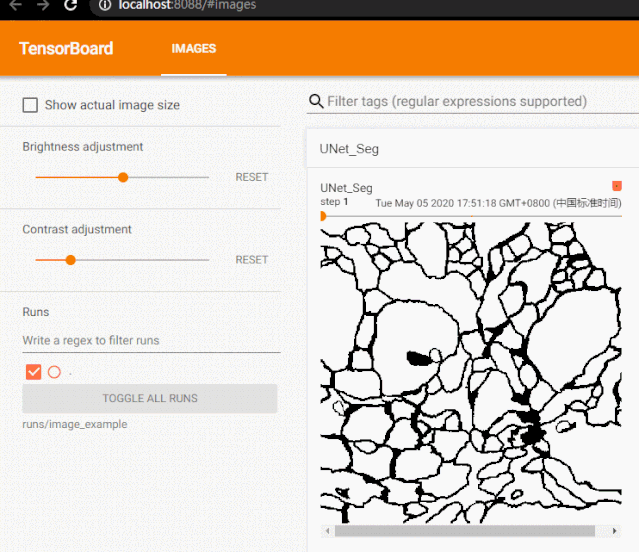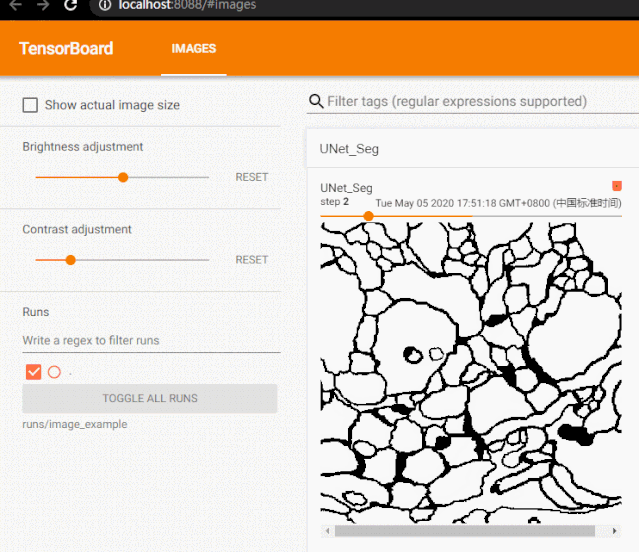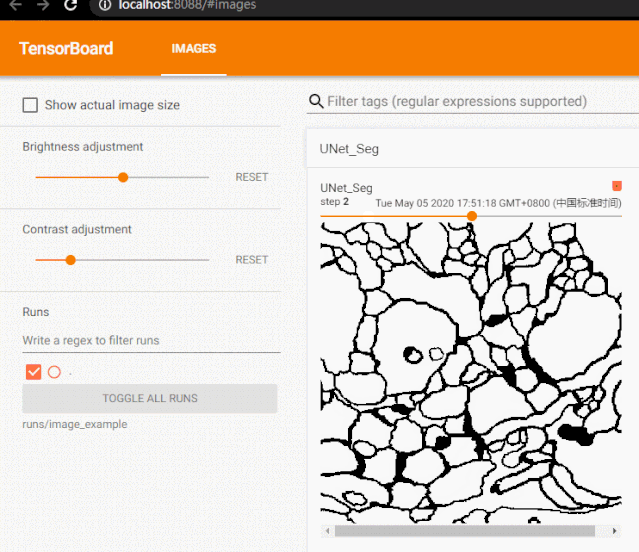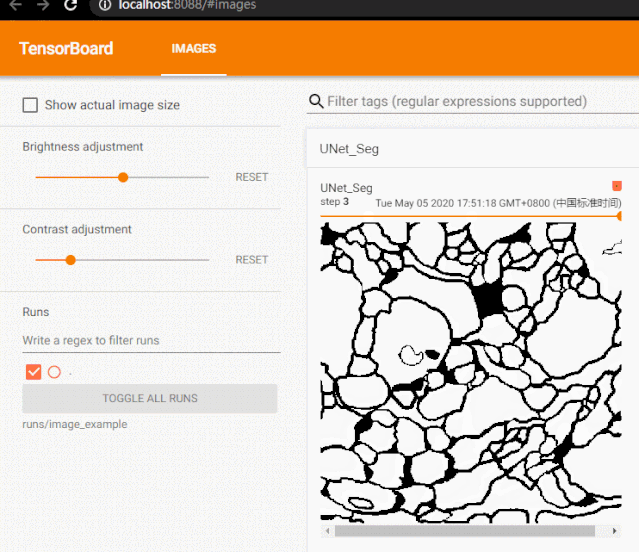
6
总结 工欲善其事,必先利其器。 本文讲解了深度学习中,常用的“炼丹法宝”的使用方法,sys.stdout、matplotlib、logging、tensorboardX 你更喜欢哪一款? 更多精彩内容(请点击图片进行阅读)

 公众号: AI蜗牛车 保持谦逊、保持自律、保持进步
公众号: AI蜗牛车 保持谦逊、保持自律、保持进步

点个在看,么么哒!

版权声明:本文为weixin_29198045原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。