一、docker无法启动
今日发现一启动docker就提示错误
[root@sccstestenv yum.repos.d]# systemctl start docker
Job for docker.service failed because start of the service was attempted too often. See "systemctl status docker.service" and "journalctl -xe" for details.
To force a start use "systemctl reset-failed docker.service" followed by "systemctl start docker.service" again.
根据提示查看日志
systemctl status docker.service
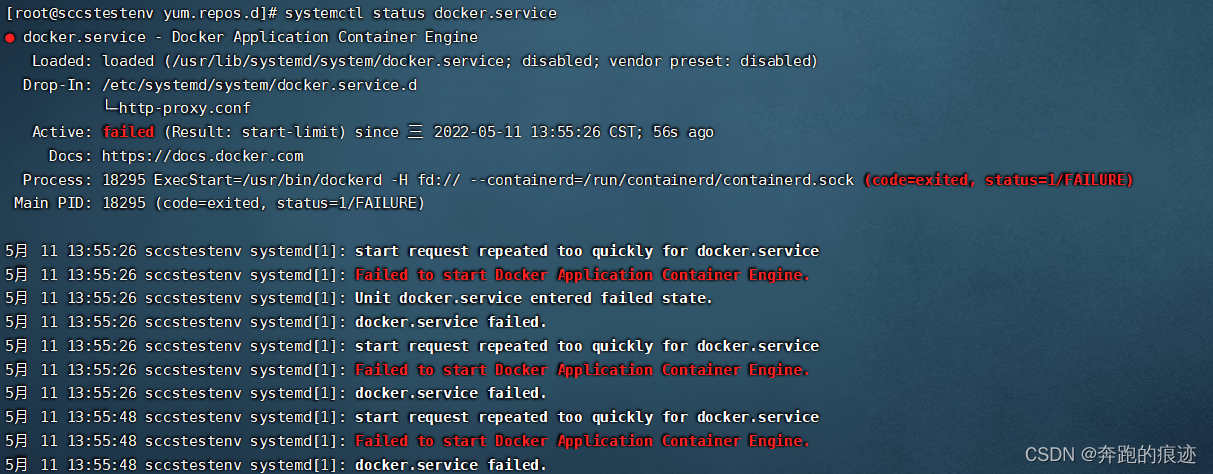
一脸懵逼???
。。。。。。。。。。
。。。。。。。。。。
。。。。。。。。。。
根据这个提示我纠结了好久,就把这个错误贴到网络进行查找,一查一个准很多这种错误
,心想哇塞这个应该可以,拿去比作修改,测试,no
,心想哇塞这个应该可以,拿去比作修改,测试,no
,心想哇塞这个应该可以,拿去比作修改,测试,no
,心想哇塞这个应该可以,拿去比作修改,测试,no
经历过无数次测试
我想到了人家说的docker 有问题,我直接就把他给卸载了,重新安装。。。。
再然后有人说yum 有问题我把yum 也重新装了一遍,但是问题依然存在,哈哈啊哈哈。
后来有人说 新建shell 然后执行一下就可以修复上面的问题
#!/bin/sh
# Copyright 2011 Canonical, Inc
# 2014 Tianon Gravi
# Author: Serge Hallyn <serge.hallyn@canonical.com>
# Tianon Gravi <tianon@debian.org>
set -e
# for simplicity this script provides no flexibility
# if cgroup is mounted by fstab, don't run
# don't get too smart - bail on any uncommented entry with 'cgroup' in it
if grep -v '^#' /etc/fstab | grep -q cgroup; then
echo 'cgroups mounted from fstab, not mounting /sys/fs/cgroup'
exit 0
fi
# kernel provides cgroups?
if [ ! -e /proc/cgroups ]; then
exit 0
fi
# if we don't even have the directory we need, something else must be wrong
if [ ! -d /sys/fs/cgroup ]; then
exit 0
fi
# mount /sys/fs/cgroup if not already done
if ! mountpoint -q /sys/fs/cgroup; then
mount -t tmpfs -o uid=0,gid=0,mode=0755 cgroup /sys/fs/cgroup
fi
cd /sys/fs/cgroup
# get/mount list of enabled cgroup controllers
for sys in $(awk '!/^#/ { if ($4 == 1) print $1 }' /proc/cgroups); do
mkdir -p $sys
if ! mountpoint -q $sys; then
if ! mount -n -t cgroup -o $sys cgroup $sys; then
rmdir $sys || true
fi
fi
done
# example /proc/cgroups:
# #subsys_name hierarchy num_cgroups enabled
# cpuset 2 3 1
# cpu 3 3 1
# cpuacct 4 3 1
# memory 5 3 0
# devices 6 3 1
# freezer 7 3 1
# blkio 8 3 1
exit 0
于是我新建了如上shell, 然后运行想着能修复,然并卵。
二、ERROR: ZONE_CONFLICT: ‘docker0’ already bound to a zone
后来再次查看防火墙状态
[root@sccstestenv yum.repos.d]# systemctl status firewalld.service
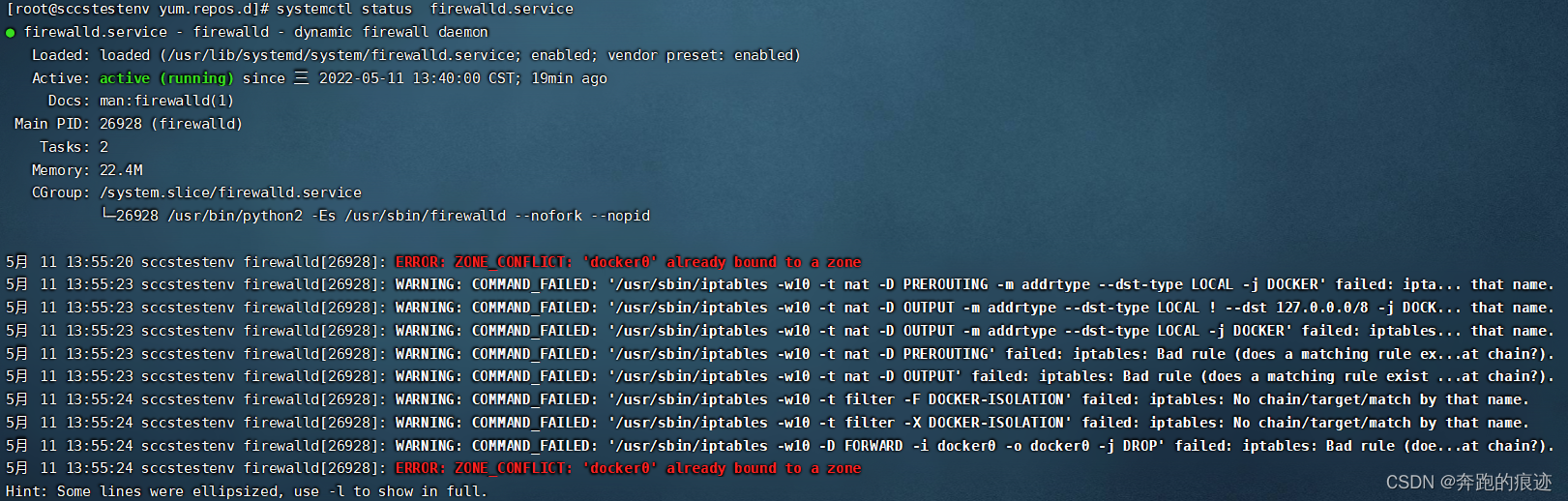
看到了显眼的 ERROR: ZONE_CONFLICT: ‘docker0’ already bound to a zone
三、第一次修复
然后根据这个异常查询网络资料,看见了ZONE_CONFLICT: ‘docker0‘ already bound to a zone博客
根据他的描述 查看防火墙配置
[root@sccstestenv yum.repos.d]# sudo firewall-cmd --list-all-zones
trusted 的interfaces 中有docker0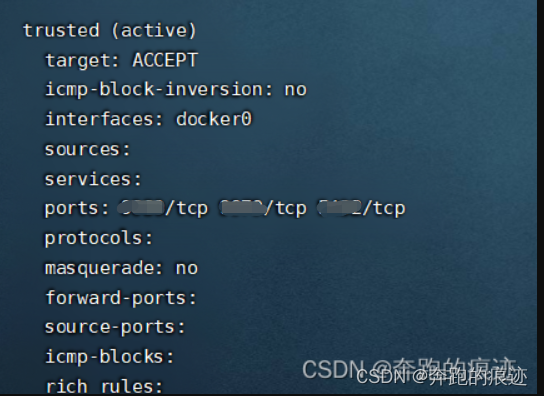
而docker 项的interfaces却没有

根据描述执行trusted项的docker0的删除操作
[root@sccstestenv yum.repos.d]# sudo firewall-cmd --zone=trusted --remove-interface=docker0 --permanent
success
然后重启防火墙
[root@sccstestenv yum.repos.d]# sudo firewall-cmd --reload
重启docker

麻蛋还是失败了,呜呜呜。
既然有了方向就好办,继续找找…
四、第二次修复
又看到了ERROR: ZONE_CONFLICT: ‘docker0’ already bound to a zone博客
根据描述再次执行修改
[root@sccstestenv yum.repos.d]# sudo firewall-cmd --permanent --zone=docker --change-interface=docker0
success
再次重启防火墙
[root@sccstestenv yum.repos.d]# sudo systemctl restart firewalld
再次查看防火墙配置
[root@sccstestenv yum.repos.d]# sudo firewall-cmd --list-all-zones
发现这次docker 有了配置

而trusted成了这样
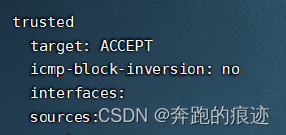
再次重启docker
[root@sccstestenv ~]# systemctl restart docker
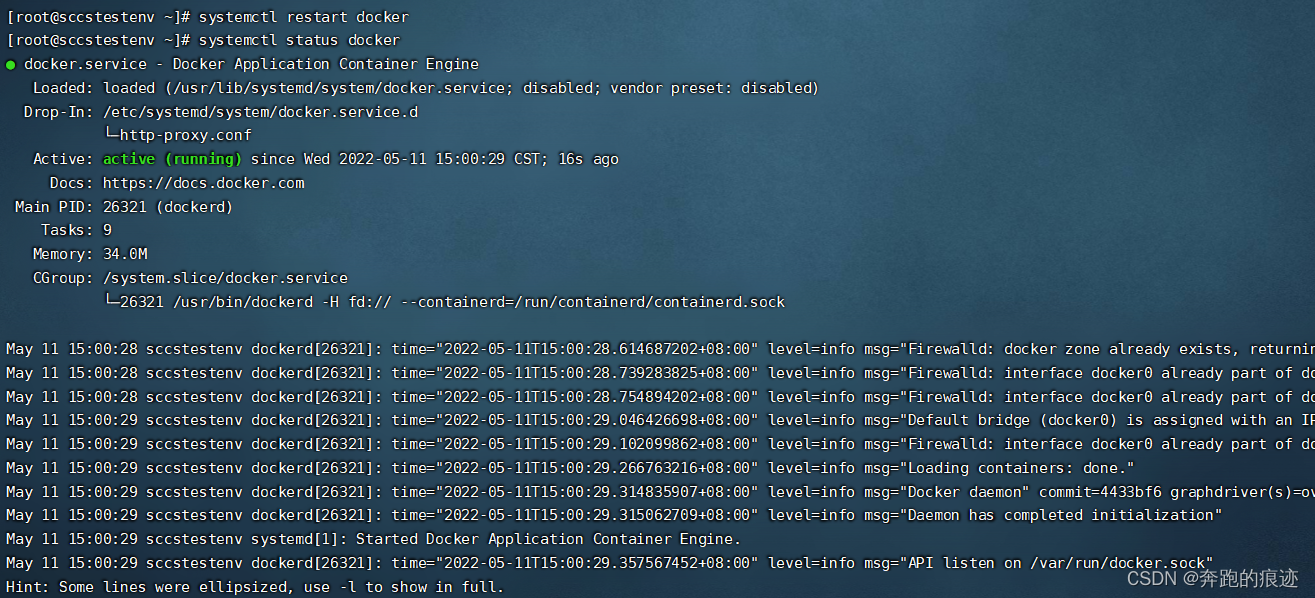
终于OK了,
再看看防火墙的状态
这个也没有错误了,终于解决了docker 启动异常的问题
再次感谢运维自动化&云计算和SmalltalkVoice两位博主的分享,谢谢