文章目录
循环神经网络(Recurrent Neural Network,RNN)
NLP里最常用、最传统的深度学习模型就是循环神经网络 RNN。这个模型的命名已经说明了数据处理方法,是按顺序按步骤读取的。与人类理解文字的道理差不多,看书都是一个字一个字,一句话一句话去理解的。
CNN(卷积神经网络) vs RNN(循环神经网络)
1.CNN 需要固定长度的输入、输出,RNN 的输入和输出可以是不定长且不等长的
2.CNN 只有 one-to-one 一种结构,而 RNN 有多种结构,如下图: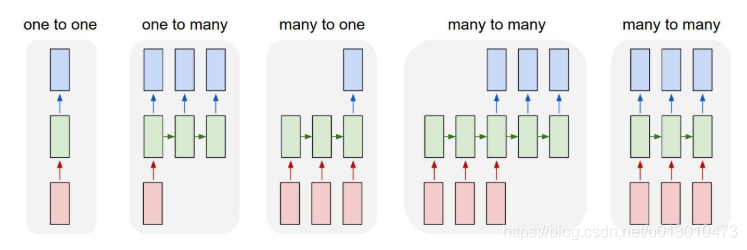
最基本的单层神经网络
下图是最简单的、最基本的单层神经网络。输入是x,经过变换Wx+b和激活函数f 得到输入y。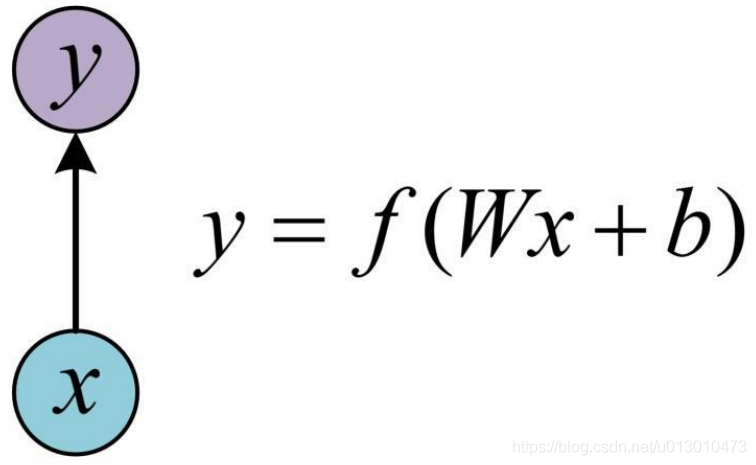
经典的RNN结构(N vs N)
在实际的应用中,我们经常会遇到很多序列型的数据,比如:
1)自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,以此类推。
2)语音处理。此时,x1,x2,x3……是每帧的声音信号。
3)时间序列问题。例如每天的股票价格等。
序列型的数据就不太好用原始的神经网络处理了。为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列型的数据提取特征,接着再转换为输出。先从h1的计算开始:
1)其中圆圈或方块表示的是向量;
2)一个箭头就表示对该向量做一次变换。
h2的计算和h1类似。在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的(所以可训练参数的数量与序列长度无关)。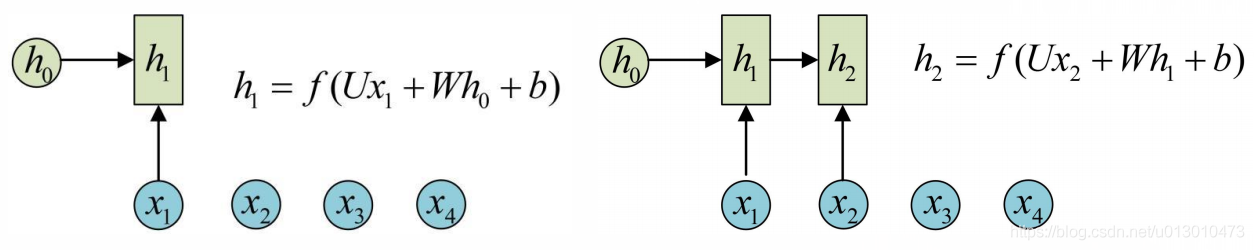
依次计算剩下的(使用相同的参数U、W、b):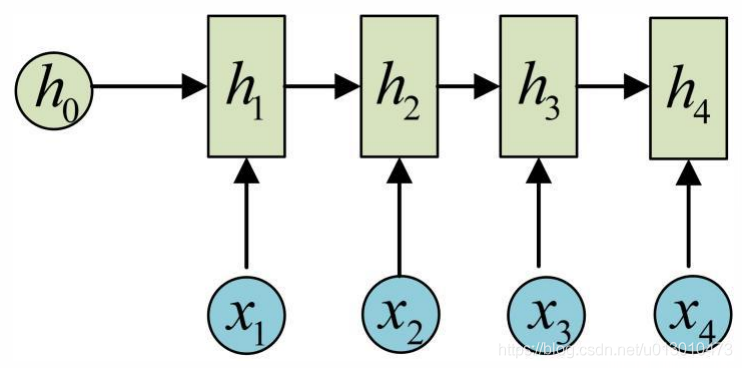
目前的RNN还没有输出,得到输出值的方法就是直接通过h进行计算,同上,一个箭头表示对对应的向量 做一次类似于f(Wx+b)的变换,这里的的箭头就是表示对h1进行一次变换,得到输出y1: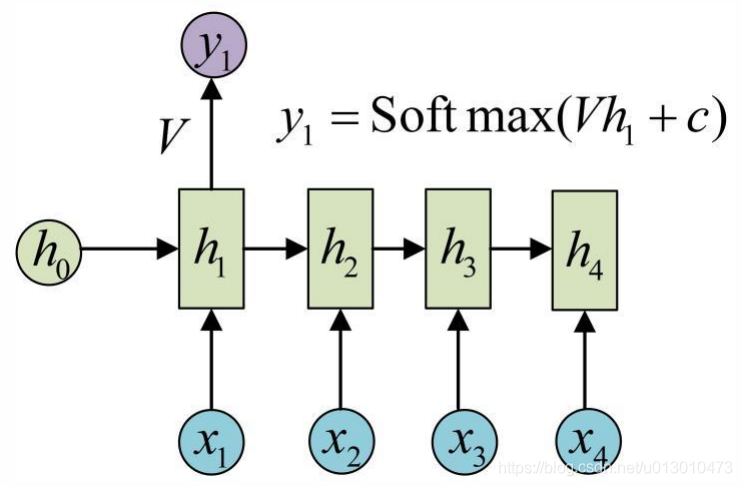
剩下的输出y2,y3,y4类似进行计算(使用和y1同样的参数V和c):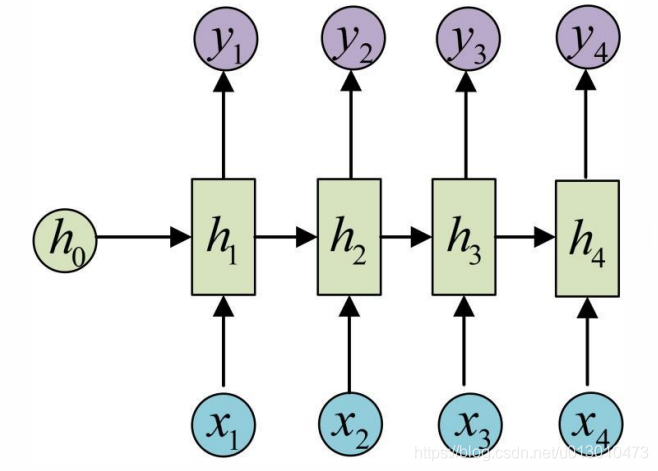
至此,经典的RNN结构就搭建好了,它的输入是x1,x2,……,xn,输出是y1,y2,……,yn,也就是说,输入和输出序列必须是等长的。由于存在这个限制,经典RNN的适用范围比较小,但也有一些特定的问题适合用经典的RNN结构建模,如:
1)计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
2)输入为字符,输出为下一个字符的概率。
RNN变体(N vs 1)
有时需要处理的问题输入是一个序列,输出是一个单独的值而非序列,此时只在最后一个h上进行输出变换就可以了。这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。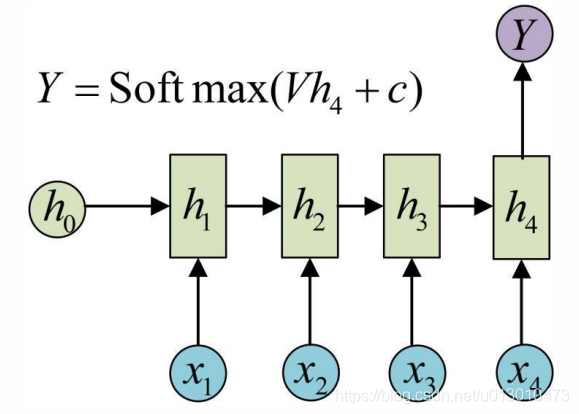
RNN变体(1 vs N)
输入不是序列而输出为序列的情况只需在序列开始进行输入计算。这种1 vs N的结构可以处理的问题有:
1)从图像生成文字(image caption),此时输入的x就是图像的特征,而输出的y序列就是一段句子;
2)从类别生成语音或者音乐等。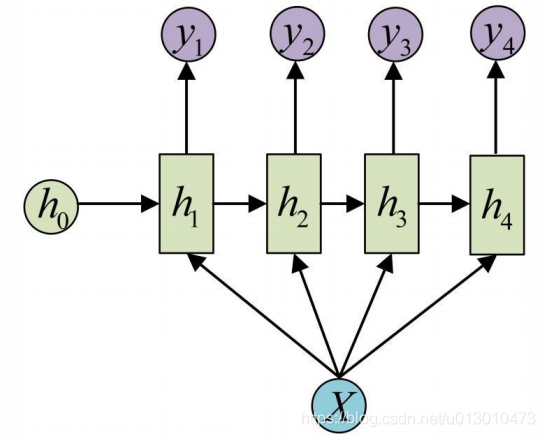
序列到序列(Sequence to Sequence,Seq2Seq)
原始的N vs N RNN要求序列等长,然后我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。RNN的另一种重要的变种:N vs M,这种结构又叫Encoder-Decoder模型,也可以称为Seq2Seq模型。Seq2Seq模型先通过Encoder将输入数据编码成一个上下文向量c,得到c之后,再用Decoder对其进行解码。
一种做法是将c当做之前的初始状态h0输入到Decoder中: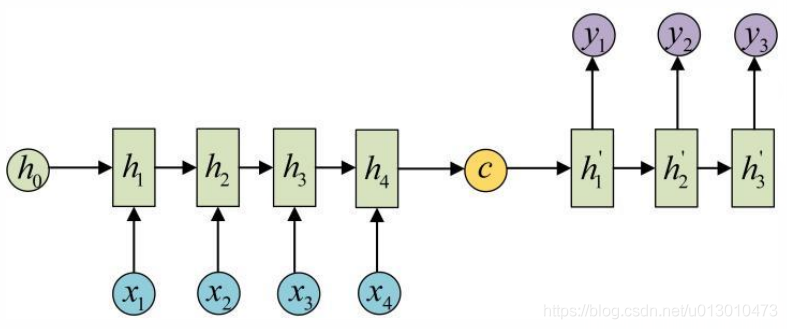
另一种做法是将c当做每一步的输入: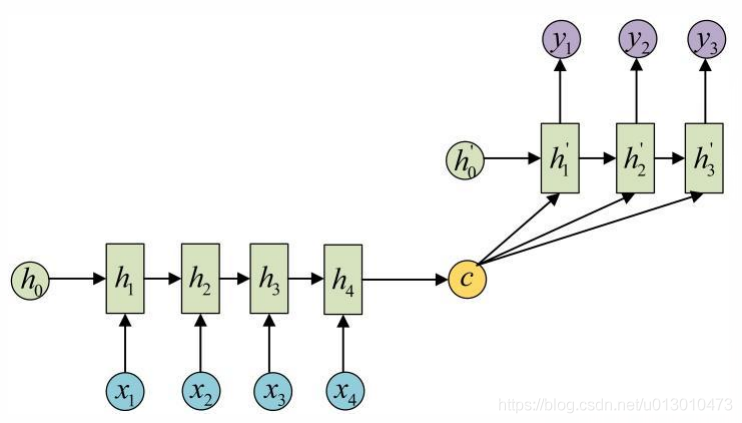
由于这种Encoder-Decoder(Seq2Seq)结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
1)机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出来的。
2)文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
3)阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
4)语音识别。输入是语音序列,输出是文字序列。
注意力机制(Attention)
在Encoder-Decoder(Seq2Seq)结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此,c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder: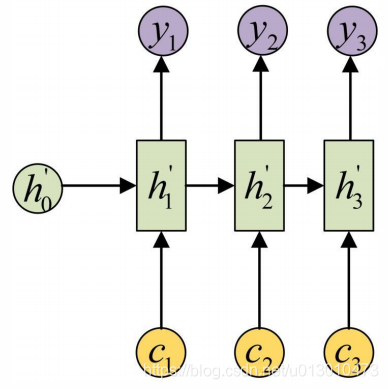
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用aij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息ci就来自于所有hj对aij的加权和。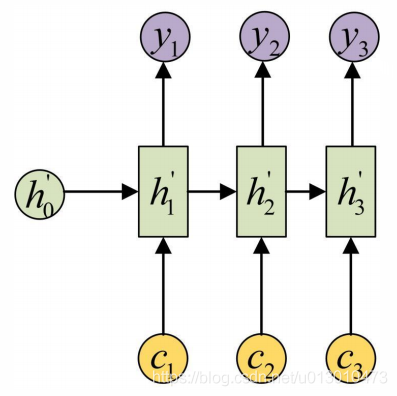
以机器翻译为例:输入的序列是“我爱中国”,因此,Encoder中的h1,h2,h3,h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的a11就比较大,而相应的a12、a13、a14就比较小。c2应该和“爱”最相关,因此对应的a22就比较大。最后的c3和h3、h4最相关,因此a33、a34的值就比较大。其中的aij是从模型中学到的,它实际和Decoder的第i-1阶段的隐状态、Encoder第j个阶段的隐状态有关。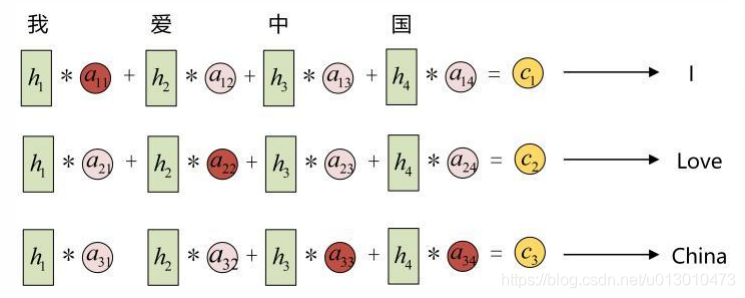
a1j的计算如下图(箭头就表示对h’和hj同时做变换):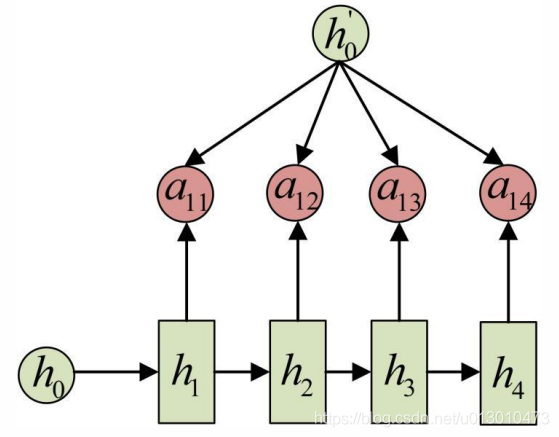
a2j的计算如下图(箭头就表示对h’和hj同时做变换):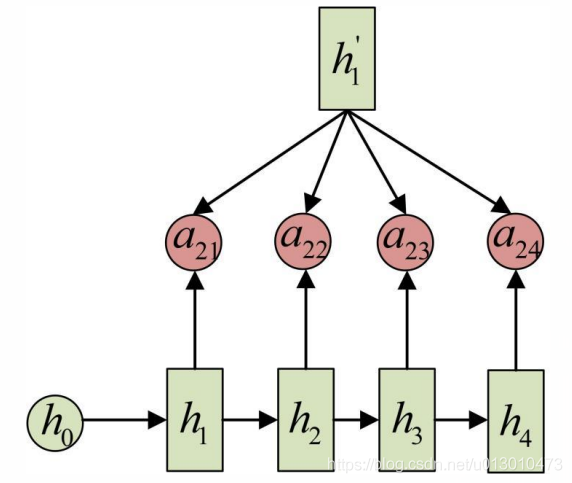
a3j的计算如下图(箭头就表示对h’和hj同时做变换):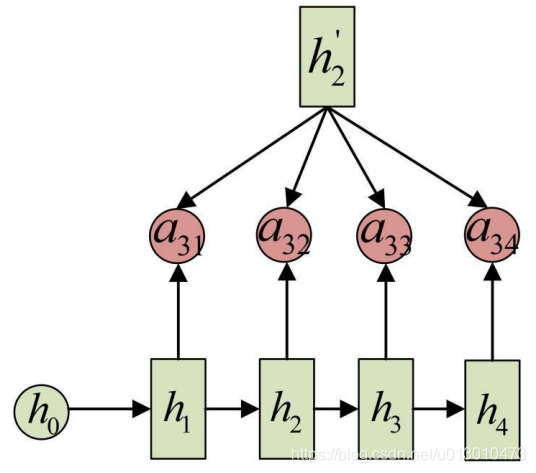
以上就是带有Attention的Encoder-Decoder模型计算的全过程。
Attention 的优点
1)在机器翻译时,让生词不只是关注全局的语义向量c,增加了“注意力范围”。表示接下来输出的词要重点关注输入序列种的哪些部分。根据关注的区域来产生下一个输出。
2)不要求编码器将所有信息全输入在一个固定长度的向量中。
3)将输入编码成一个向量的序列,解码时,每一步选择性的从序列中挑一个子集进行处理。
4)在每一个输出时,能够充分利用输入携带的信息,每个语义向量Ci不一样,注意力焦点不一样。
Attention 的缺点
1)需要为每个输入输出组合分别计算attention。50个单词的输出输出序列需要计算2500个attention。
2)attention在决定专注于某个方面之前需要遍历一遍记忆再决定下一个输出是以什么。
Attention的另一种替代方法是强化学习,来预测关注点的大概位置。但强化学习不能用反向传播算法端到端的训练。
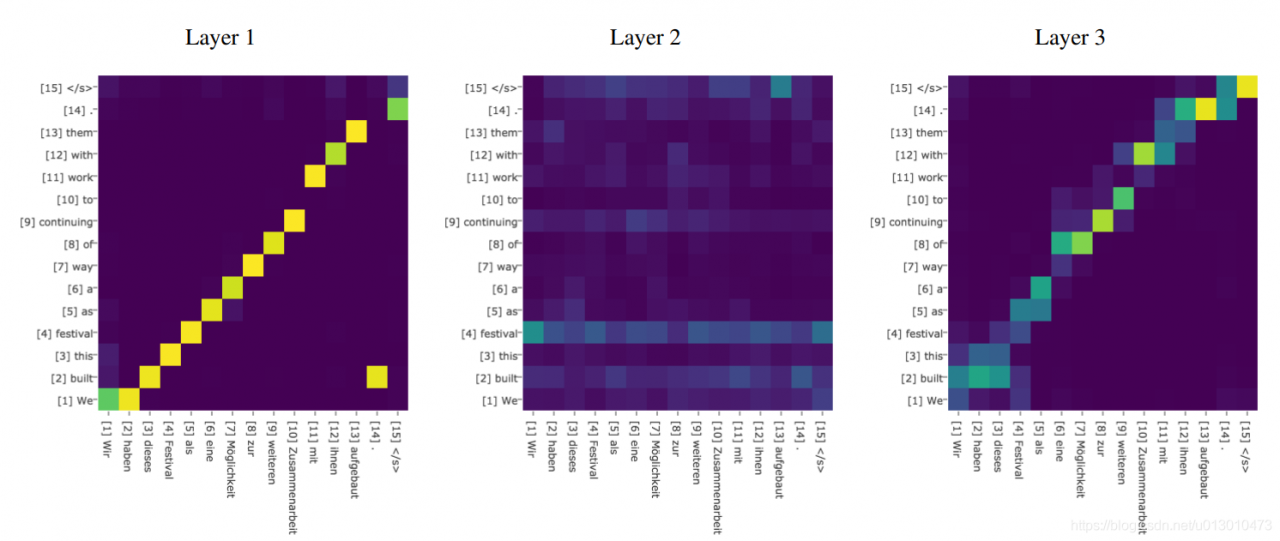
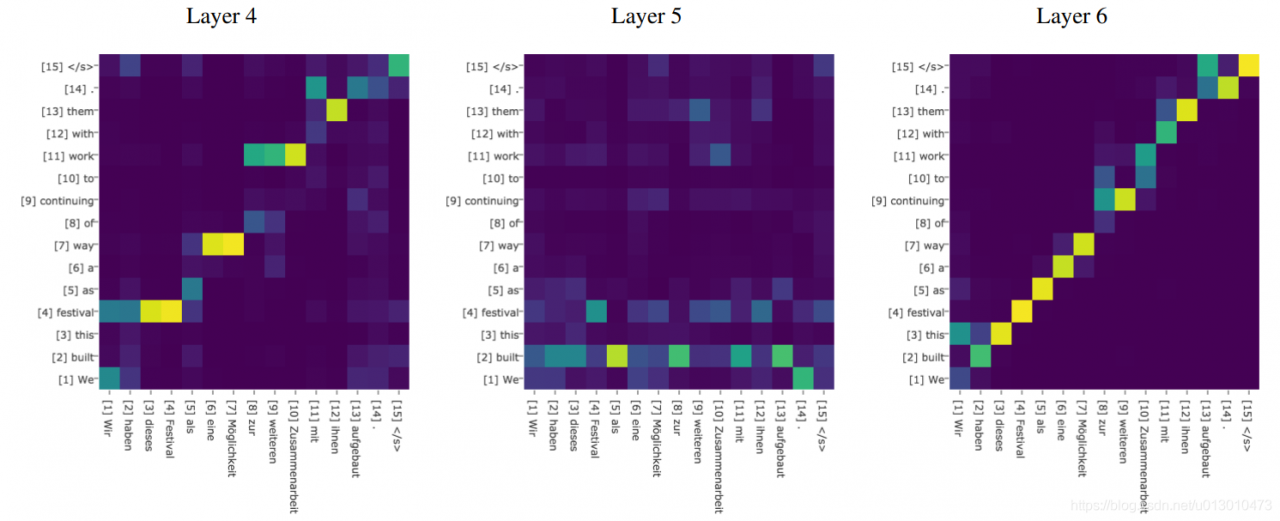
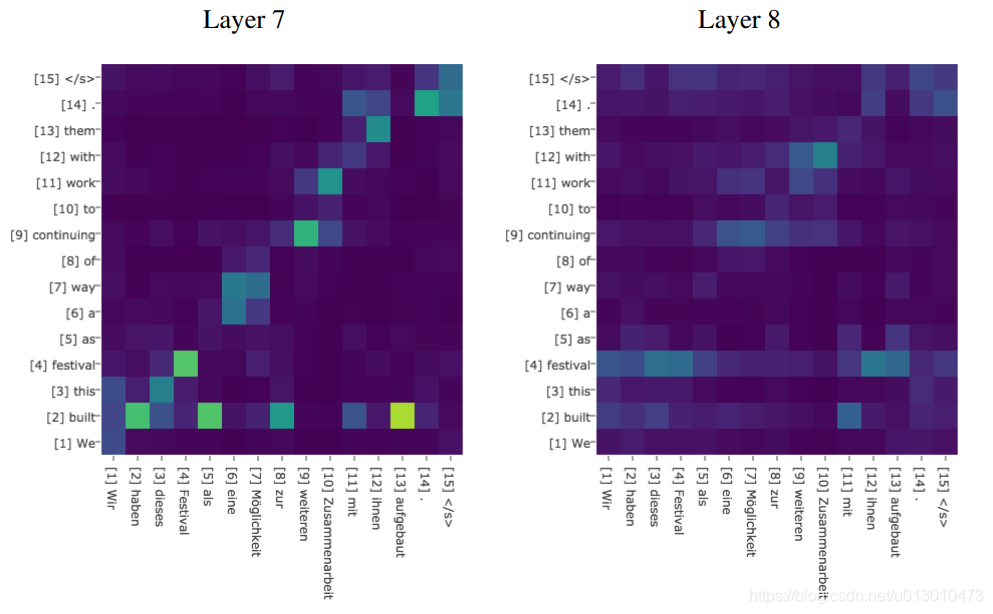
Attention可视化
下图是句子的单词之间的attention联系,颜色深浅表示大小。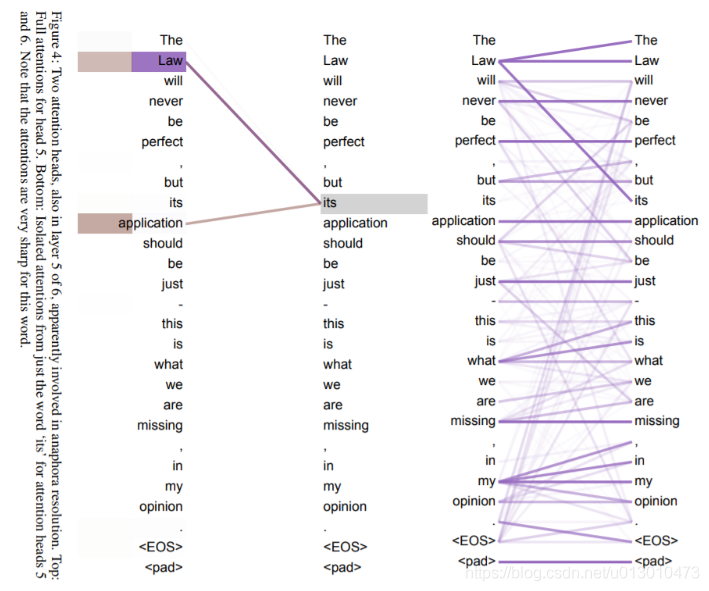
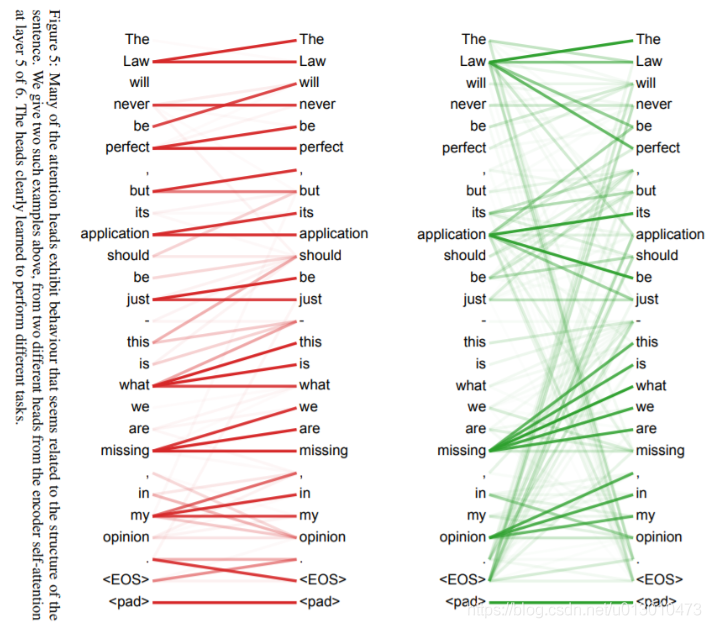
机器翻译中attention矩阵的可视化,一般是随着顺序强相关的。