优秀是一种习惯
- 知识点01:回顾
- 知识点02:目标
- 知识点03:流量案例:业务需求
- 知识点04:流量案例:需求1分析
- 知识点05:流量案例:需求1实现
- 知识点06:流量案例:需求2分析及实现
- 知识点07:流量案例:需求3分析及实现
- 知识点08:Shuffle:设计思想
- 知识点09:Shuffle:功能与过程划分
- 知识点10:Shuffle:Map端Shuffle过程
- 知识点11:Shuffle:Reduce端Shuffle过程
- 知识点12:Shuffle:流程图解析
- 知识点13:Shuffle:Combiner优化
- 知识点14:JobHistoryServer与日志聚集
- 知识点15:Shuffle:Compress优化
- 知识点16:Shuffle:分组设计及规则
- 知识点17:Shuffle:Top1的需求及实现分析
- 知识点18:Shuffle:Top1的实现
- 附录一:MapReduce编程依赖
知识点01:回顾
什么是分区机制?分区的规则是什么?
- 分区机制:指的多个Reduce场景下,如何决定Map输出的每一条数据K2V2最终会被哪个Reduce进行处理
- 本质:打标签
- 实现:调用分区器【Partitioner】的分区方法【getPartition】获取数据对应的分区编号
- 规则:默认HashPartitioner,对K2计算hash值取余Reduce分区的个数
- 优点:只要K2相同,就会进入同一个分区
- 缺点:数据分配不均衡
- 分区机制:指的多个Reduce场景下,如何决定Map输出的每一条数据K2V2最终会被哪个Reduce进行处理
自定义分区的规则是什么?
规则
- 开发一个分区器:继承Partitioner,重写getPartition(K2,V2,Reduce个数)
配置
job.setPartitionerClass(Userpartition); job.setNumReduceTask(N)
MapReduce如何实现自定义数据类型?
- 本质:构建一个JavaBean
- 定义属性
- 构造
- get and set
- toString
- 要求:必须支持Hadoop的序列化
- 实现:JavaBean implements Writable
- write:序列化
- readFields:反序列化
- 本质:构建一个JavaBean
如何实现自定义数据类型并实现比较器接口?
- 问题:当使用自定义的类型作为五大阶段的K2
- 类的类型转换异常
- 原因:K2需要做排序和分组,会强转为比较器的对象来实现,但由于只实现序列化接口,没有比较器接口,转换失败
- 解决:自定义数据类型实现比较器接口
- JavaBean implements WritableComparable
- 方法:compareTo(T)
- 问题:当使用自定义的类型作为五大阶段的K2
为什么要做排序?排序的规则是什么?
设计目的:为了加快分组的效率
应用:利用MapReduce自带的排序实现排序的需求
例如:二次排序问题
a 4 b 0 a 3 c 6 a 8 b 7 b 5 c 3方案一:封装一个JavaBean作为K2,V2为NullWritable
Java extends WritableComparable compreTo(other){ int comp = this.first.compareTo(other.first); if(comp == 0){ return -this.second - o.second } return comp; }方案二:用Text作为K2【字母】,Int作为V2【数字】
Shuffle a <4,3,8> b <0,7,5> c <6,3> reduce reduce(K2,Iter values){ List list = new List[int] for(value:values){ list.add(value.get) } Collection.sort(list,new Comparetor{ compare(int a,int b){ return b-a } }) for(v:list){ context(K2,v) } }
排序规则
- step1:先查找排序器,如果有,调用排序器的compare方法
- step2:如果没有排序器,调用K2自带的compareTo
如何实现自定义排序比较器?
规则:开发一个比较器类,继承WritableComparator,重写compare
配置
job.setSortComparatorClass()
知识点02:目标
- 流量分析案例
- 自定义数据类型
- 分区
- 排序
- |
如何分析一个MapReduce代码应该怎么写
- Shuffle
- 为什么需要shuffle这个东西?
- Shuffle的功能:分区、排序、分组、Combiner
- Shuffle实现过程?
- Shuffle优化
- Combiner
- Compress
- 分组的规则和自定义分组
知识点03:流量案例:业务需求
目标:了解流量分析案例的数据集业务需求
实施
- 数据内容
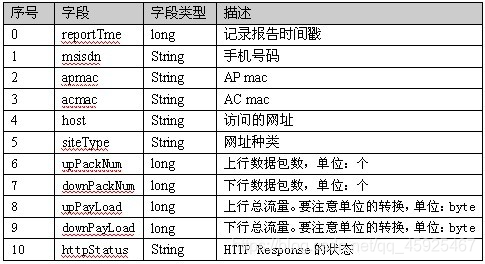
需求
需求一:统计每个手机号所有上网记录的上行总信息和下行总信息
手机号 上行总包 下行总包 上行总流量 下行总流量- 自定义数据类型
需求二:基于需求1的结果:按照上行总流量将结果降序排序
- 排序
需求三:基于需求1的结果:将134开头的写入1个分区,135开头的写入另外一个分区,其他的写入另外一个分区
- 分区
小结
- 基于数据内容,了解需求通过MapReduce实现开发
知识点04:流量案例:需求1分析
目标:分析需求一的程序实现过程
路径:统计每个手机号所有上网记录的上行总信息和下行总信息
实施
step1:结果长什么样?
手机号 上行总包 下行总包 上行总流量 下行总流量- 肯定要实现自定义数据类型
step2:K2是谁?
- 有没有分组?:各个、每个、不同、每……
- 有:手机号
- 有没有排序?
- 没有
- K2:手机号
- 有没有分组?:各个、每个、不同、每……
step3:V2是谁?
- 结果中除了K2,还有谁,在数据中有没有?
- 有
- 如果没有:找到需要计算能得到的列,作为V2
- V2:上行包、下行包、上行流量、下行流量:自定义数据类型
- 结果中除了K2,还有谁,在数据中有没有?
step4:验证结果
Input
- K1:行的偏移量
- V1:行的内容
Map
map方法
String[] items = value.toString.split(" ") this.outputKey.set(items[1]) this.outputValue.set(itemsp[6],items[7],items[8],items[9])K2:手机号
V2:JavaBean
Shuffle
- 分组:按照K2
- 相同手机号对应所有上网的信息的Javabean放入一个迭代器中
Reduce
for(javebean:value){ sumUpPack += javebean.getUpPack; …… }Output
小结
- 掌握分析的过程
知识点05:流量案例:需求1实现
目标:实现需求1的代码开发
实施
代码
自定义数据类型
package bigdata.itcast.cn.hadoop.mr.flow; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @ClassName FlowBean1 * @Description TODO 自定义数据类型,用于封装上行和下行信息 * @Date 2021/4/28 10:15 * @Create By Frank */ public class FlowBean1 implements Writable { private long upPack; private long downPack; private long upFlow; private long downFlow; public void setAll(long upPack,long downPack,long upFlow,long downFlow){ this.setUpPack(upPack); this.setDownPack(downPack); this.setUpFlow(upFlow); this.setDownFlow(downFlow); } public long getUpPack() { return upPack; } public void setUpPack(long upPack) { this.upPack = upPack; } public long getDownPack() { return downPack; } public void setDownPack(long downPack) { this.downPack = downPack; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } @Override public String toString() { return this.upPack+"\t"+this.downPack+"\t"+this.upFlow+"\t"+this.downFlow; } public void write(DataOutput out) throws IOException { out.writeLong(this.upPack); out.writeLong(this.downPack); out.writeLong(this.upFlow); out.writeLong(this.downFlow); } public void readFields(DataInput in) throws IOException { this.upPack = in.readLong(); this.downPack = in.readLong(); this.upFlow = in.readLong(); this.downFlow = in.readLong(); } }代码
package bigdata.itcast.cn.hadoop.mr.flow; import bigdata.itcast.cn.hadoop.mr.mode.MRMapperMode; import bigdata.itcast.cn.hadoop.mr.mode.MRReducerMode; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRDriverMode * @Description TODO 统计每个手机号所有上网记录的上行总信息和下行总信息 * @Date 2021/4/26 14:31 * @Create By Frank */ public class MRFlow1 extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"flow1"); //指定允许jar包运行的类 job.setJarByClass(MRFlow1.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源 Path inputPath = new Path("datas/flow/data_flow.dat");//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(FlowMapper.class); //设置调用的Mapper类 job.setMapOutputKeyClass(Text.class); //设置K2的类型 job.setMapOutputValueClass(FlowBean1.class); //设置V2的类型 //Shuffle:配置Shuffle // job.setPartitionerClass(null); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 // job.setGroupingComparatorClass(null); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(FlowReducer.class); //设置调用reduce的类 job.setOutputKeyClass(Text.class); //设置K3的类型 job.setOutputValueClass(FlowBean1.class); //设置V3的类型 // job.setNumReduceTasks(1); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path("datas/output/flow/flow1"); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new MRFlow1(), args); //退出程序 System.exit(status); } public static class FlowMapper extends Mapper<LongWritable,Text,Text,FlowBean1>{ //K2 Text outputKey = new Text(); //V2 FlowBean1 outputValue = new FlowBean1(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //切分每一行的内容 String[] items = value.toString().split("\\s+"); //非法性过滤:如果长度不为11,这条数据就不处理 if(items.length != 11){ return; } //给K2赋值 this.outputKey.set(items[1]); //给V2赋值 this.outputValue.setAll(Long.parseLong(items[6]),Long.parseLong(items[7]),Long.parseLong(items[8]),Long.parseLong(items[9])); //直接输出 context.write(this.outputKey,this.outputValue); } } public static class FlowReducer extends Reducer<Text,FlowBean1,Text,FlowBean1>{ //V 3 FlowBean1 outputValue = new FlowBean1(); @Override protected void reduce(Text key, Iterable<FlowBean1> values, Context context) throws IOException, InterruptedException { long sumUpPack = 0; long sumDownPack = 0; long sumUpFlow = 0; long sumDownFlow = 0; for (FlowBean1 value : values) { sumUpPack += value.getUpPack(); sumDownPack += value.getDownPack(); sumUpFlow += value.getUpFlow(); sumDownFlow += value.getDownFlow(); } //给K3赋值 this.outputValue.setAll(sumUpPack,sumDownPack,sumUpFlow,sumDownFlow); //输出 context.write(key,this.outputValue); } } }
结果
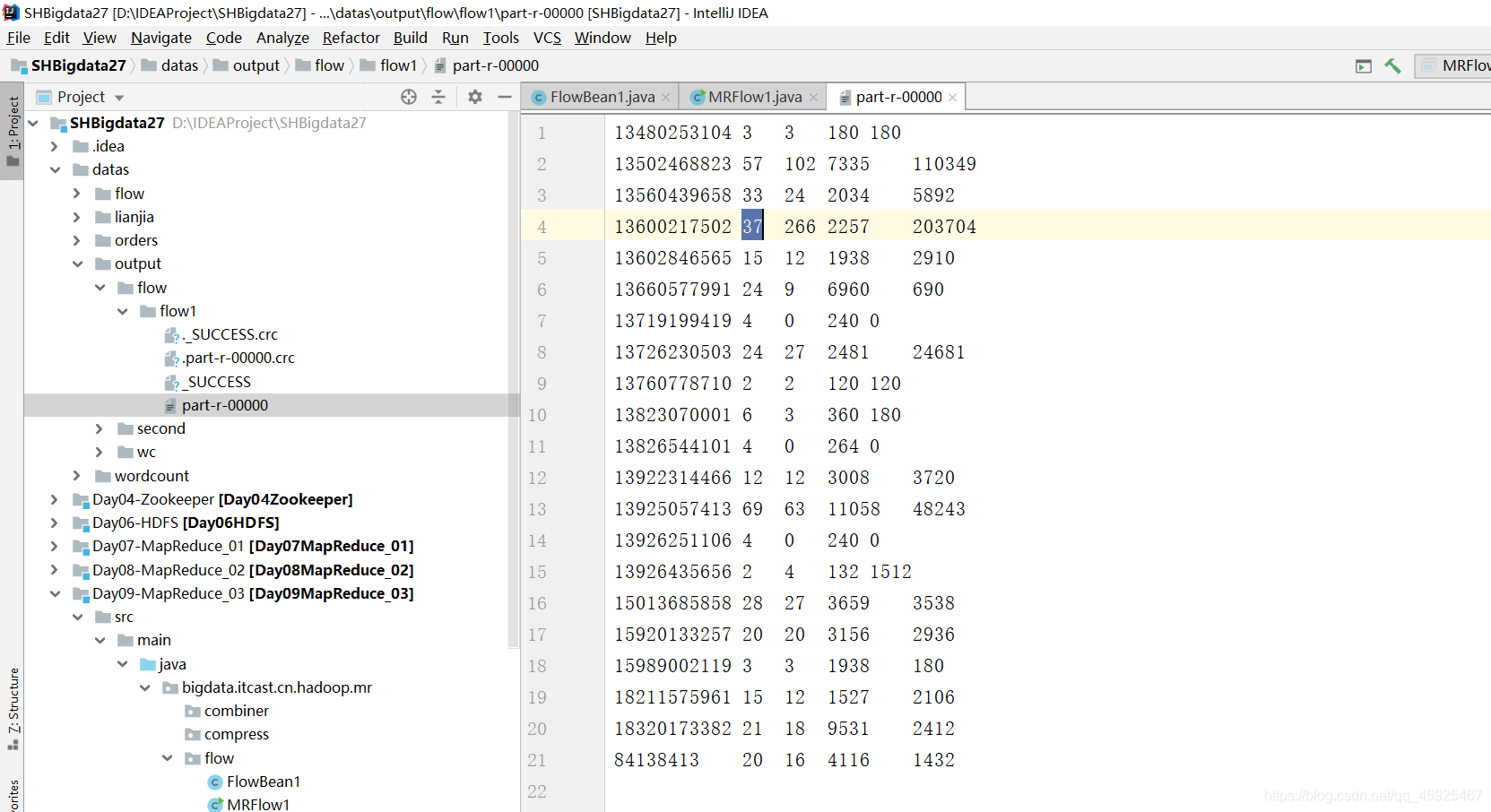
小结
- 实现代码即可
知识点06:流量案例:需求2分析及实现
目标:实现需求2的分析及代码开发
路径:基于需求1的结果:按照上行总流量将结果降序排序
实施
分析
结果
手机号 上行总包 下行总包 上行总流量 下行总流量- 按照上行总流量降序排序
K2
- 没有分组
- 有排序:按照上行总流量排序
- K2:将五列封装JavaBean
- 重写compareTo:按照上行总流量降序排序
V2
- Null
代码
自定义数据类型
package bigdata.itcast.cn.hadoop.mr.flow; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @ClassName FlowBean1 * @Description TODO 自定义数据类型,用于封装上行和下行信息 * @Date 2021/4/28 10:15 * @Create By Frank */ public class FlowBean2 implements WritableComparable<FlowBean2> { private String phone; private long upPack; private long downPack; private long upFlow; private long downFlow; public void setAll(String phone,long upPack,long downPack,long upFlow,long downFlow){ this.setPhone(phone); this.setUpPack(upPack); this.setDownPack(downPack); this.setUpFlow(upFlow); this.setDownFlow(downFlow); } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public long getUpPack() { return upPack; } public void setUpPack(long upPack) { this.upPack = upPack; } public long getDownPack() { return downPack; } public void setDownPack(long downPack) { this.downPack = downPack; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } @Override public String toString() { return this.phone+"\t"+this.upPack+"\t"+this.downPack+"\t"+this.upFlow+"\t"+this.downFlow; } public void write(DataOutput out) throws IOException { out.writeUTF(this.phone); out.writeLong(this.upPack); out.writeLong(this.downPack); out.writeLong(this.upFlow); out.writeLong(this.downFlow); } public void readFields(DataInput in) throws IOException { this.phone = in.readUTF(); this.upPack = in.readLong(); this.downPack = in.readLong(); this.upFlow = in.readLong(); this.downFlow = in.readLong(); } //按照上行总流量降序排序 public int compareTo(FlowBean2 o) { return -Long.valueOf(this.getUpFlow()).compareTo(Long.valueOf(o.getUpFlow())); } }代码实现
package bigdata.itcast.cn.hadoop.mr.flow; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRDriverMode * @Description TODO 统计每个手机号所有上网记录的上行总信息和下行总信息 * @Date 2021/4/26 14:31 * @Create By Frank */ public class MRFlow2 extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"flow2"); //指定允许jar包运行的类 job.setJarByClass(MRFlow2.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源:如果输入路径是目录,将目录下所有文件作为输入,注意,目录下不能包含子目录 Path inputPath = new Path("datas/output/flow/flow1");//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(FlowMapper.class); //设置调用的Mapper类 job.setMapOutputKeyClass(FlowBean2.class); //设置K2的类型 job.setMapOutputValueClass(NullWritable.class); //设置V2的类型 //Shuffle:配置Shuffle // job.setPartitionerClass(null); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 // job.setGroupingComparatorClass(null); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(FlowReducer.class); //设置调用reduce的类 job.setOutputKeyClass(FlowBean2.class); //设置K3的类型 job.setOutputValueClass(NullWritable.class); //设置V3的类型 // job.setNumReduceTasks(1); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path("datas/output/flow/flow2"); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new MRFlow2(), args); //退出程序 System.exit(status); } public static class FlowMapper extends Mapper<LongWritable,Text,FlowBean2, NullWritable>{ //K2 FlowBean2 outputKey = new FlowBean2(); //V2 NullWritable outputValue = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //切分每一行的内容 String[] items = value.toString().split("\\s+"); this.outputKey.setAll(items[0],Long.parseLong(items[1]),Long.parseLong(items[2]),Long.parseLong(items[3]),Long.parseLong(items[4])); //直接输出 context.write(this.outputKey,this.outputValue); } } public static class FlowReducer extends Reducer<FlowBean2, NullWritable,FlowBean2, NullWritable>{ @Override protected void reduce(FlowBean2 key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //直接输出 for (NullWritable value : values) { context.write(key,value); } } } }
结果
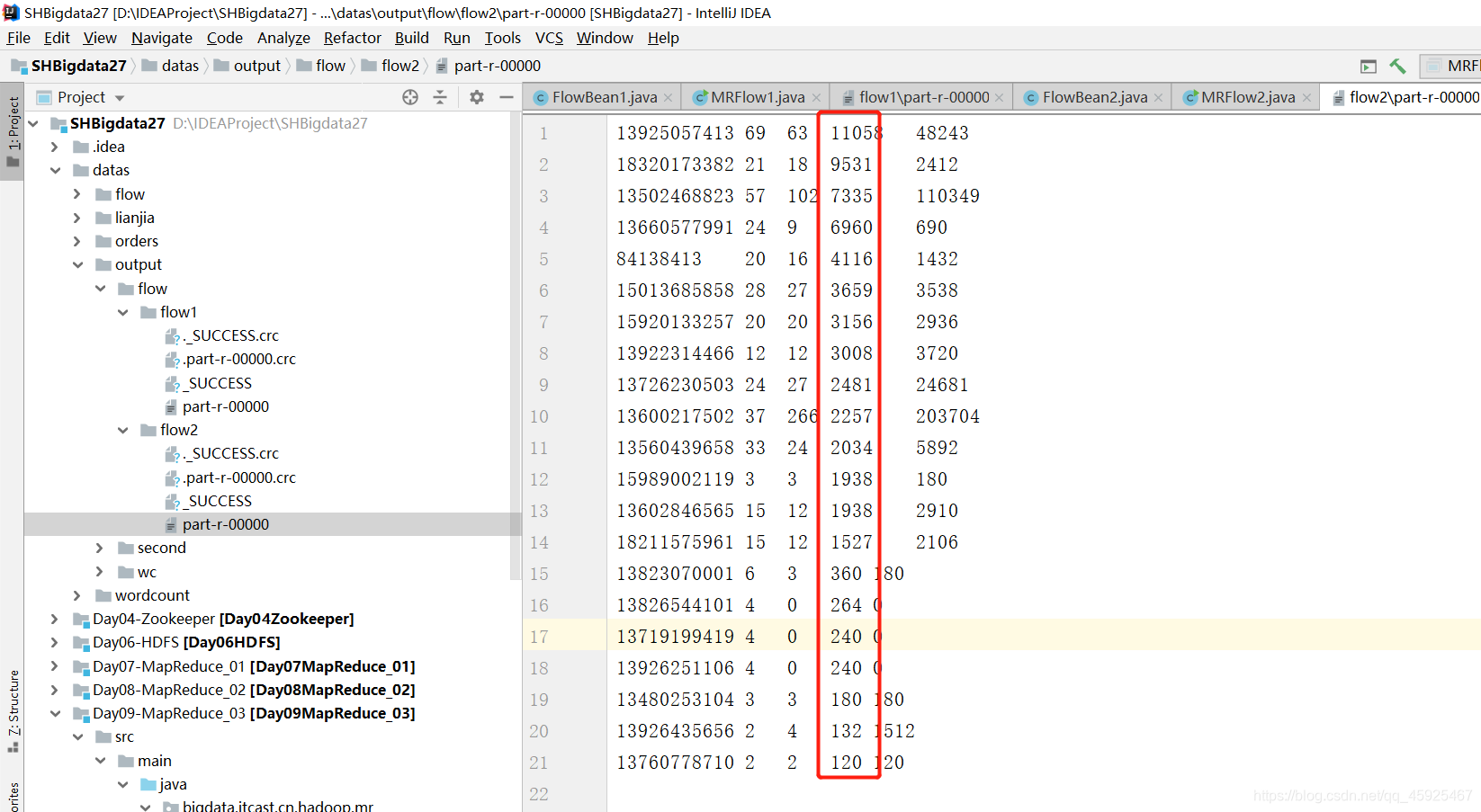
小结
- 实现代码即可
知识点07:流量案例:需求3分析及实现
目标:实现需求3的分析及代码开发
路径:基于需求1的结果:将134开头的写入1个分区,135开头的写入另外一个分区,其他的写入另外一个分区
实施
代码
自定义分区
package bigdata.itcast.cn.hadoop.mr.flow; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Partitioner; /** * @ClassName FlowPartition * @Description TODO * @Date 2021/4/28 10:58 * @Create By Frank */ public class FlowPartition extends Partitioner<FlowBean2, NullWritable> { //根据手机号码的开头来决定分区:0,1,2 public int getPartition(FlowBean2 key, NullWritable value, int numPartitions) { //获取手机号码 String phone = key.getPhone(); if(phone.startsWith("134")){ return 0; }else if(phone.startsWith("135")){ return 1; }else{ return 2; } } }代码
package bigdata.itcast.cn.hadoop.mr.flow; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRDriverMode * @Description TODO 统计每个手机号所有上网记录的上行总信息和下行总信息 * @Date 2021/4/26 14:31 * @Create By Frank */ public class MRFlow3 extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"flow3"); //指定允许jar包运行的类 job.setJarByClass(MRFlow3.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源:如果输入路径是目录,将目录下所有文件作为输入,注意,目录下不能包含子目录 Path inputPath = new Path("datas/output/flow/flow1");//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(FlowMapper.class); //设置调用的Mapper类 job.setMapOutputKeyClass(FlowBean2.class); //设置K2的类型 job.setMapOutputValueClass(NullWritable.class); //设置V2的类型 //Shuffle:配置Shuffle job.setPartitionerClass(FlowPartition.class); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 // job.setGroupingComparatorClass(null); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(FlowReducer.class); //设置调用reduce的类 job.setOutputKeyClass(FlowBean2.class); //设置K3的类型 job.setOutputValueClass(NullWritable.class); //设置V3的类型 job.setNumReduceTasks(3); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path("datas/output/flow/flow3"); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new MRFlow3(), args); //退出程序 System.exit(status); } public static class FlowMapper extends Mapper<LongWritable,Text,FlowBean2, NullWritable>{ //K2 FlowBean2 outputKey = new FlowBean2(); //V2 NullWritable outputValue = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //切分每一行的内容 String[] items = value.toString().split("\\s+"); this.outputKey.setAll(items[0],Long.parseLong(items[1]),Long.parseLong(items[2]),Long.parseLong(items[3]),Long.parseLong(items[4])); //直接输出 context.write(this.outputKey,this.outputValue); } } public static class FlowReducer extends Reducer<FlowBean2, NullWritable,FlowBean2, NullWritable>{ @Override protected void reduce(FlowBean2 key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //直接输出 for (NullWritable value : values) { context.write(key,value); } } } }
结果
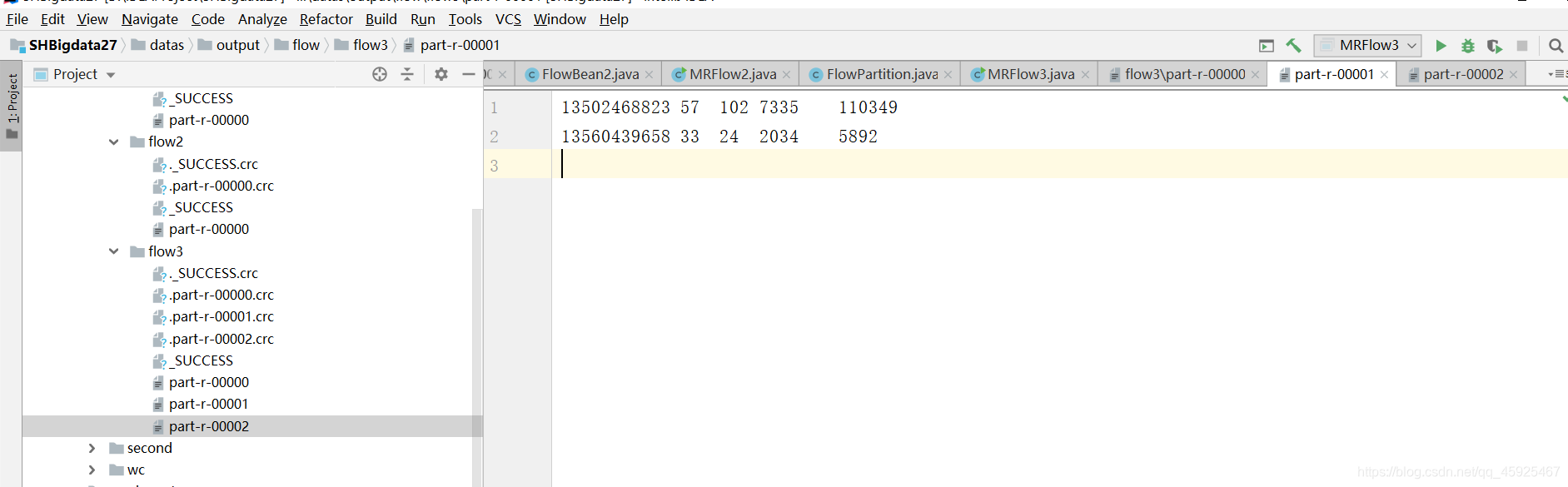
小结
- 实现代码即可
知识点08:Shuffle:设计思想
引入:为什么写程序一定要经过shuffle过程呢?
目标:掌握Shuffle的设计思想
- 为什么要设计Shuffle?
- Shuffle如何解决全局分组的问题的?
路径
- step1:分布式的问题
- step2:Shuffle的设计
- step3:Shuffle的实现
实施
分布式的问题
分布式计算过程中,如何实现全局分组或者全局排序?
举个栗子1:当前有一份数据:8 5 7 4 2 6 1 3,需要实现全局排序
- 结果:1 2 3 4 5 6 7 8
- 计算:分布式做了Task划分
- Task1:8 5 7 4
- 4 5 7 8
- Task2:2 6 1 3
- 1 2 3 6
- Task1:8 5 7 4
- 问题:无法实现
举个栗子2:当前MapTask输出的结果如下,统计每个单词出现的次数,需要全局分组
MapTask1:node1
hadoop 1 hive 1 hive 1MapTask2:node2
hadoop 1 hive 1结果
hadoop 1,1 hive 1,1,1问题:无法实现
Shuffle的设计
- 为了解决分布式中全局排序和全局分组的问题
Shuffle的实现
- 所有Map的结果会全部写入磁盘
- 在分布式磁盘中通过特殊的排序机制来实现全局排序
- 再由Reduce读取全局排序后的数据进行处理
- 特点:必须经过磁盘,只要经过shuffle,性能就比较差
小结
- 为什么要设计Shuffle?
- 全局分组和全局排序
- group by 和 order by
- Shuffle如何解决全局分组的问题的?
- 将所有数据写入磁盘
- 通过局部排序加快分组的性能
- 读取数据进行分组
- 为什么要设计Shuffle?
知识点09:Shuffle:功能与过程划分
- 目标:掌握Shuffle的功能与实现过程
- 路径
- step1:Shuffle的功能
- step2:Shuffle的过程划分
- 实施
- Shuffle的功能
- 分区:默认按照K2进行Hash分区,对Map输出的数据进行标记
- 排序:按照K2进行排序
- 分组:按照K2进行分组,相同K2的所有V2放在一起
- Shuffle的过程划分
- Map端Shuffle
- Input
- Map
- Map端的Shuffle
- Reduce端Shuffle
- Reduce端的Shuffle
- Reduce
- Output
- Map端Shuffle
- Shuffle的功能
- 小结
- Shuffle的功能是什么?
- 分区、排序、分组
- Shuffle的过程怎么划分的?
- Map端Shuffle
- Reduce端Shuffle
- 注意:Map端Shuffle实现由MapTask来运行实现,Reduce端Shuffle实现由ReduceTask来执行
- Shuffle的功能是什么?
知识点10:Shuffle:Map端Shuffle过程
目标:掌握Map端的Shuffle过程
实施
Input阶段
读取文件
hadoop hive spark hbase hadoop hadoop spark hive hbase hadoop spark hadoop hive spark hbase hadoop hadoop spark hive hbase hadoop spark划分分片
Split1
hadoop hive spark hbase hadoop hadoop spark hive hbase hadoop spark hadoop hive sparkSplit2
hbase hadoop hadoop spark hive hbase hadoop spark
转换KV
Split1
K1 V1 0 hadoop hive spark 100 hbase hadoop hadoop 200 spark hive 300 hbase hadoop spark 400 hadoop hive sparkSplit2
K1 V1 0 hbase hadoop hadoop 100 spark hive 200 hbase hadoop spark
Map阶段
构建MapTask
MapTask1
K1 V1 0 hadoop hive spark 100 hbase hadoop hadoop 200 spark hive 300 hbase hadoop spark 400 hadoop hive sparkMapTask2
K1 V1 0 hbase hadoop hadoop 100 spark hive 200 hbase hadoop spark
调用map方法
MapTask1
K2 V2 hadoop 1 hive 1 spark 1 hbase 1 hadoop 1 hadoop 1 spark 1 hive 1 hbase 1 hadoop 1 spark 1 hadoop 1 hive 1 spark 1MapTask2
K2 V2 hbase 1 hadoop 1 hadoop 1 spark 1 hive 1 hbase 1 hadoop 1 spark 1
Map端的Shuffle阶段
分区:假设有两个reduce,编号分别为0和1
MapTask1
K2 V2 Partition hadoop 1 0 hive 1 1 spark 1 0 hbase 1 0 hadoop 1 0 hadoop 1 0 spark 1 0 hive 1 1 hbase 1 0 hadoop 1 0 spark 1 0 hadoop 1 0 hive 1 1 spark 1 0MapTask2
K2 V2 Partition hbase 1 0 hadoop 1 0 hadoop 1 0 spark 1 0 hive 1 1 hbase 1 0 hadoop 1 0 spark 1 0
Spill:将每个Task处理的所有数据进行局部排序,生成多个有序的小文件
以MapTask1为例
MapTask1会将当前处理分区好的数据和对应的索引信息写入一个环形缓冲区【内存:100M】
直到达到存储阈值:80%,达到80M【数据+索引】,触发Spill
hadoop 1 0 hive 1 1 spark 1 0 hbase 1 0hadoop 1 0 hadoop 1 0 spark 1 0 hive 1 1 hbase 1 0hadoop 1 0 spark 1 0 hadoop 1 0 hive 1 1 spark 1 0
Spill:
step1:将当前缓冲区中的数据进行排序
排序规则:相同分区的数据放在一起,分区内部按照K2进行排序
排序算法:内存、快排
hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1hadoop 1 0 hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1hadoop 1 0 hadoop 1 0 spark 1 0 spark 1 0 hive 1 1
step2:将排序好的数据写入磁盘,变成一个有序的小文件
写入磁盘,释放80M内存,另外20%持续写入,又会达到阈值,继续触发spill
file1
hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1file2
hadoop 1 0 hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1file3
hadoop 1 0 hadoop 1 0 spark 1 0 spark 1 0 hive 1 1
结果:会有很多有序的小文件
Merge:每个MapTask都会将自己的所有小文件合并为一个大文件合并过程中会进行排序
合并
hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1 hadoop 1 0 hadoop 1 0 hbase 1 0 spark 1 0 hive 1 1 hadoop 1 0 hadoop 1 0 spark 1 0 spark 1 0 hive 1 1排序
- 规则:先按照分区排序,分区内部按照K2排序
- 算法:磁盘,插入排序:基于有序小文件的合并排序
file
MapTask1
hadoop 1 0 hadoop 1 0 hadoop 1 0 hadoop 1 0 hadoop 1 0 hbase 1 0 hbase 1 0 spark 1 0 spark 1 0 spark 1 0 spark 1 0 hive 1 1 hive 1 1 hive 1 1MaPTask2
K2 V2 Partition hadoop 1 0 hadoop 1 0 hadoop 1 0 hbase 1 0 hbase 1 0 spark 1 0 spark 1 0 hive 1 1
当MapTask生成大文件以后,会通知程序管理者,当前MapTask已经结束,生成文件,程序管理者收到Map的通知。会通知ReduceTask到每个MapTask的大文件中取属于自己的数据
小结
- Map端的Shuffle阶段如何实现?
- Spill:将MapTask的每个小的部分的数据进行排序,生成多个有序的小文件
- 为Merge构建全局有序做准备的
- 排序:内存,快排
- Merge:将整个MapTask所有数据构建全局有序
- 排序:磁盘,插入排序
- Spill:将MapTask的每个小的部分的数据进行排序,生成多个有序的小文件
- Map端的Shuffle阶段如何实现?
知识点11:Shuffle:Reduce端Shuffle过程
目标:掌握Reduce端的Shuffle过程
实施
Reduce端的Shuffle阶段
每个ReduceTask收到程序管理者的通知,会到每个MapTask的结果文件中取属于自己的数据
reduceTask0
MapTask1
hadoop 1 0
hadoop 1 0
hadoop 1 0
hadoop 1 0
hadoop 1 0
hbase 1 0
hbase 1 0
spark 1 0
spark 1 0
spark 1 0
spark 1 0- MapTask2hadoop 1 0
hadoop 1 0
hadoop 1 0
hbase 1 0
hbase 1 0
spark 1 0
spark 1 0reduceTask1
MapTask1
hive 1 1
hive 1 1
hive 1 1- MapTask2hive 1 1
Merge:每个ReduceTask会将属于自己的所有MapTask的数据进行合并并排序
合并
ReduceTask0
hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hbase 1 hbase 1 spark 1 spark 1 spark 1 spark 1 hadoop 1 hadoop 1 hadoop 1 hbase 1 hbase 1 spark 1 spark 1ReduceTask1
hive 1 1 hive 1 1 hive 1 1 hive 1 1
排序
算法:磁盘,插入排序
ReduceTask0
hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hbase 1 hbase 1 hbase 1 hbase 1 spark 1 spark 1 spark 1 spark 1 spark 1 spark 1ReduceTask1
hive 1 1 hive 1 1 hive 1 1 hive 1 1
Reduce阶段
分组
reduceTask0
hadoop <1,1,1,1,1,1,1,1> hbase <1,1,1,1> spark <1,1,1,1,1,1>reduceTask1
hive <1,1,1,1>
调用reduce方法
reduceTask0
hadoop 8 hbase 4 spark 6reduceTask1
hive 4
Output阶段
保存为结果文件
part-r-00000
part-r-00001
小结
- Reduce端的Shuffle阶段如何实现?
- 拉取数据:每个Reduce到每个Map的结果中拉取属于自己的数据
- Merge:每个ReduceTask将所有MapTask中属于自己的数据进行合并排序
- Reduce端的Shuffle阶段如何实现?
知识点12:Shuffle:流程图解析
目标:实现Shuffle过程流程图
实施

小结
- 整个Shuffle实现的过程?
- Map端Shuffle
- Spill
- Merge
- Reduce端Shuffle
- Merge
知识点13:Shuffle:Combiner优化
- 目标:掌握Shuffle过程中Combiner的优化
- 路径
- step1:Combiner的功能
- step2:Combiner的实现
- 实施
Combiner的功能
功能:Map端的聚合,利用MapTask的分布式提前在Map端Shuffle过程中实现Reduce的聚合逻辑
发生
- Map端的shuffle中,每次排序以后会做判断 ,判断是否开启了Combiner
- 如果开启了Combiner,就会调用Combiner的类做分组聚合
设计:通过MapTask的个数一般远大于ReduceTask的个数,让每个MapTask对自己处理的数据先做部分聚合,最后由reduce来做所有MapTask的最终聚合,降低了Reduce的负载,提高了Reduce的性能
优点
- 降低了Reduce负载
- 解决数据倾斜的问题
举例
- 官方的WordCount
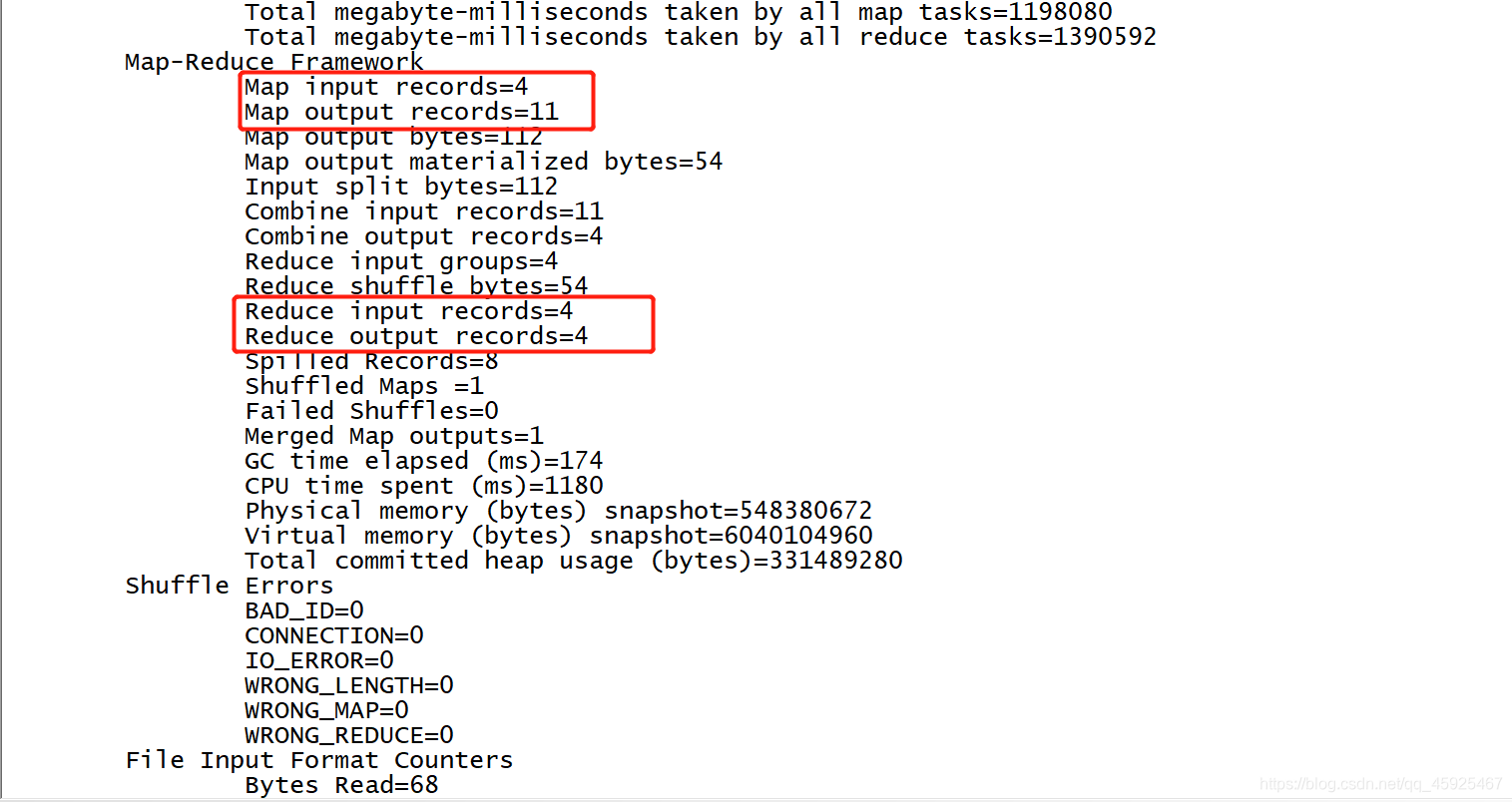
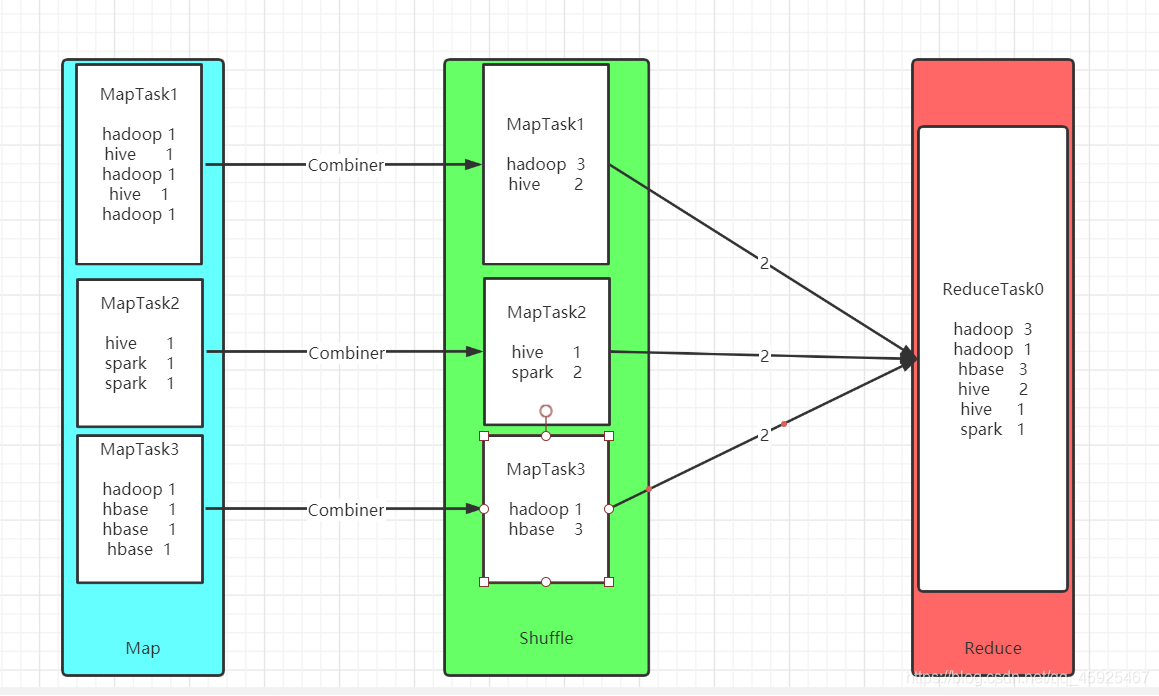
- 自己的WordCount
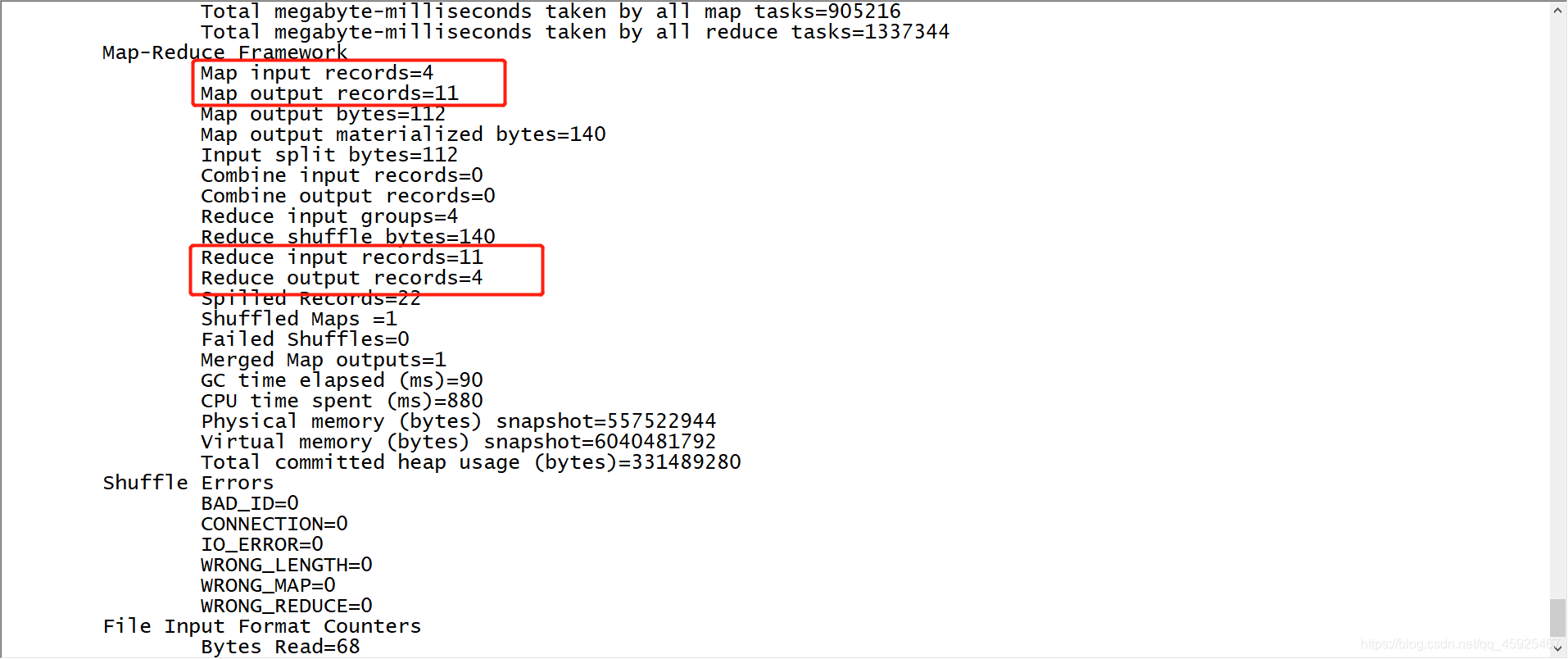
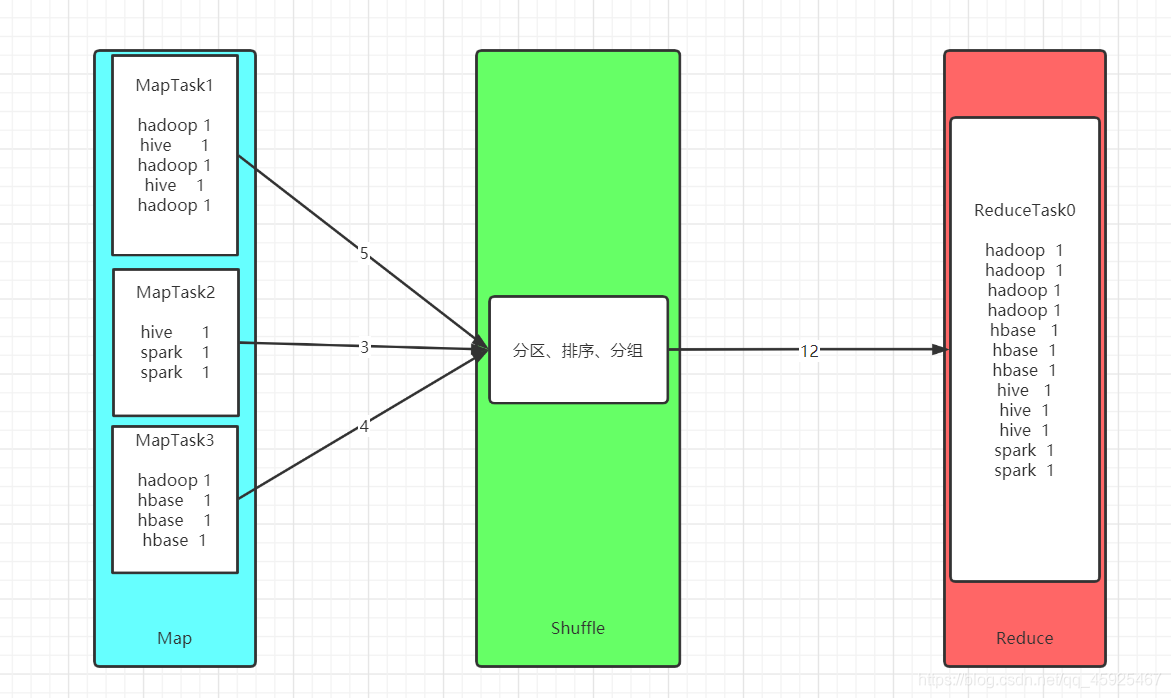
Combiner的实现
Combiner处理的逻辑:就是Reduce的处理逻辑
Combiner的类就是Reduce的类
实现
代码
job.setCombinerClass(WCReducer.class);//处理逻辑与Reduce的逻辑是一致的结果
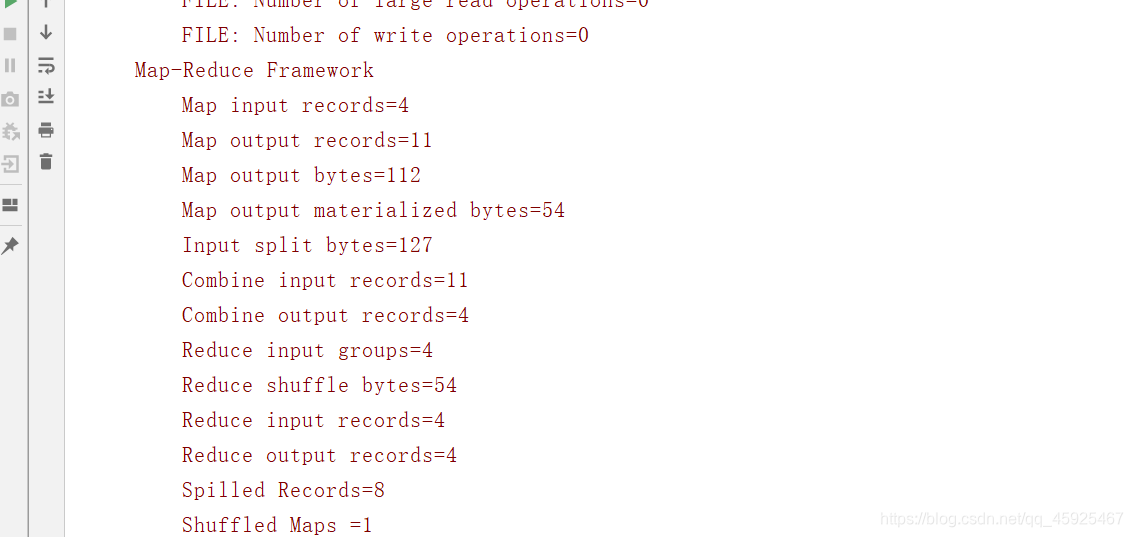
- 应用:Combiner不是所有程序都能用的,工作中一般所有的程序都能用
- 要求:必须符合分配率:a*(b+c) = a*b + ac
- 中位数:1 2 3 4 5 6 7 => 4
- Task1:1 2 3 => 2
- Task2:4 5 6 7 => 5.5
- |
- 2 , 5,5
- 小结
Combiner的功能是什么?
- 在Map端Shuffle中由每个MapTask实现聚合,减少进入Reduce数据量
- 发生在什么阶段:Map端的shuffle
- 每次排序之后会进行Combiner
- Spill:会在内存中排序后,判断是否开启Combiner,如果开启了,在内存中进行分组聚合
- Merge:合并排序时,也会判断是否执行Combiner
如何实现Combiner?
job.setCombinerClass(ReduceClass);
知识点14:JobHistoryServer与日志聚集
引入:如何查看之前在YARN上运行过的程序的信息?
目标:了解JobHistoryServer及日志聚集的功能
路径
- step1:JobHistoryServer与日志聚集的功能
- step2:JobHistoryServer与日志聚集的配置
- step3:JobHistoryServer的启动及管理
实施
JobHistoryServer的功能
- MapReduce的一个历史服务监控进程,记录在YARN中运行过的所有MapReduce的程序的信息
- 必须搭配日志聚集来使用
日志聚集的功能
- YARN的一个功能,用于记录所有程序运行的信息,将所有的信息记录在HDFS中
JobHistoryServer的配置‘
<property> <name>mapreduce.jobhistory.address</name> <value>node2:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node2:19888</value> </property>日志聚集的配置
<property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>JobHistoryServer的启动及管理
在第二台机器启动HistoryServer进程
mr-jobhistory-daemon.sh start historyserver查看
- jps

- web界面:19888 小结
- JobHistoryServer的功能是什么?
- 用于记录之前运行过的所有MapReduce程序的信息
- 日志聚集的功能是什么?
- 将运行过的程序的信息记录在HDFS上
- JobHistoryServer的功能是什么?
知识点15:Shuffle:Compress优化
目标:掌握MapReduce中的压缩优化
路径
- step1:压缩的设计
- step2:压缩的配置
- step3:压缩的实现
实施
压缩的设计
- 通过牺牲CPU的压缩和解压的性能,来提高对磁盘以及网络IO的性能的提升
- 优点
- 减小文件存储所占空间
- 加快文件传输效率,从而提高系统的处理速度
- 降低IO读写的次数
- 缺点
- 使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
- 举个栗子:1s/100M
- MapTask -> 10GB <- ReduceTask
- 不做压缩需要200s
- MapTask -> 压缩【20s】 -> 4GB <- ReduceTask ->解压【20s】
- 做了压缩:120s
- MapTask -> 10GB <- ReduceTask
Hadoop支持的压缩
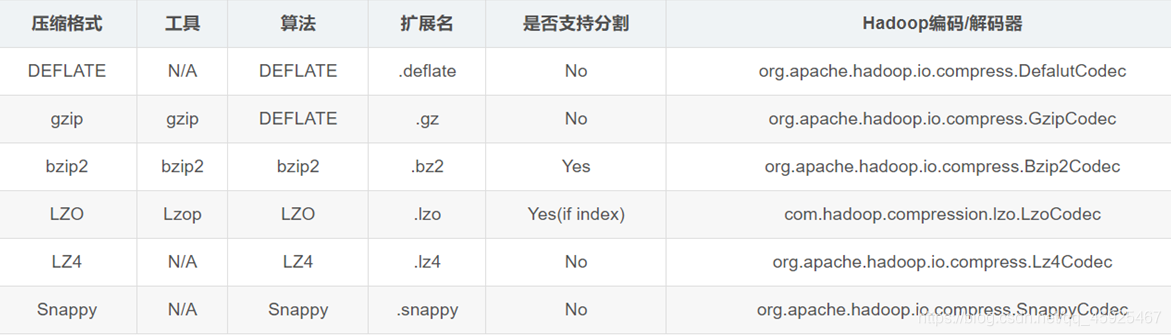
- 常用的类型:Snappy、Lzo、Lz4
- 查看当前Hadoop支持的压缩
```
hadoop checknative
```
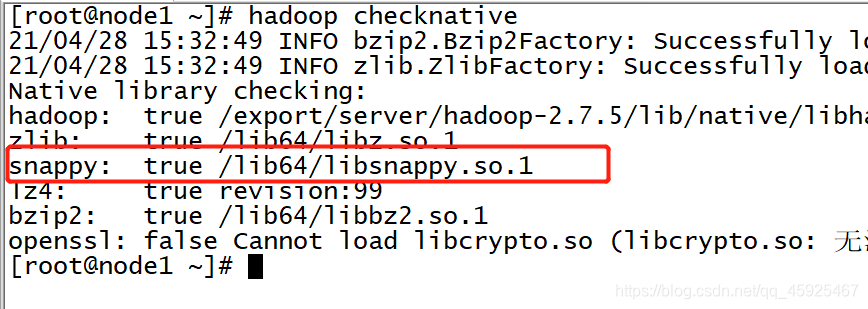
- 压缩的配置
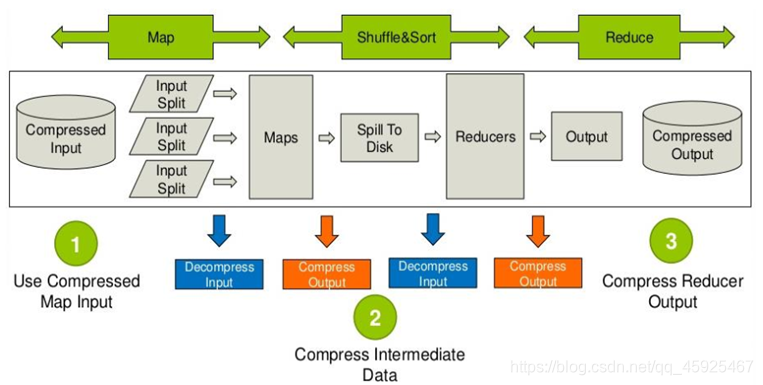
- **Input**:MapReduce输入通过对**文件后缀名**的判断,自动识别读取压缩类型,不需要做任何配置
- **Map Output**:配置以下参数
```properties
#开启Map输出结果压缩,默认为false不开启
mapreduce.map.output.compress=true
#配置Map输出结果的压缩类型
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
```
- 一般都配置这个部分,提高Shuffle性能
- **Reduce Output**:配置以下参数
```properties
#开启Reduce输出结果压缩,默认为false
mapreduce.output.fileoutputformat.compress=true
#配置Reduce输出结果的压缩类型
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
```
- 一般不配置,除非当前程序的结果要作为下一个程序的输入
压缩的实现
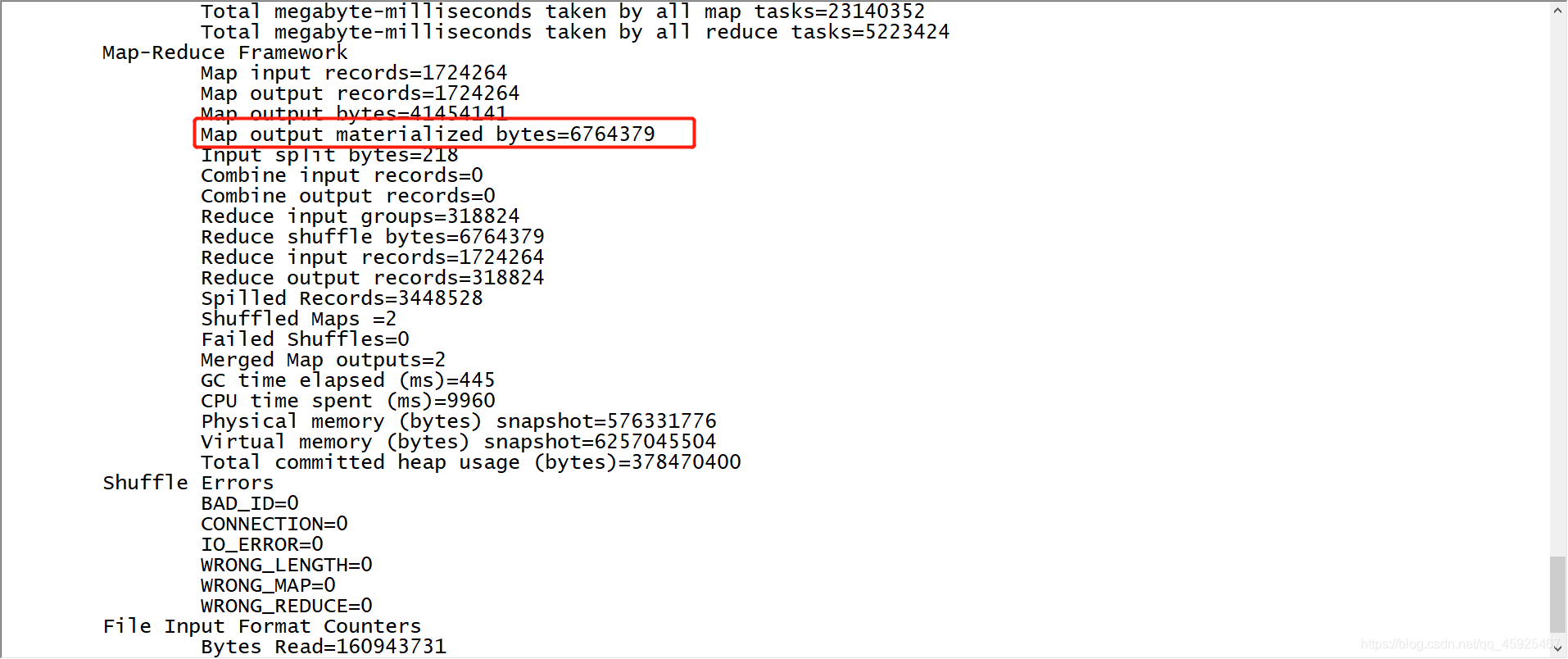
不做压缩测试
运行
yarn jar compress.jar bigdata.itcast.cn.hadoop.mr.compress.SogouCountNoCompress /sogou/input /sogou/output1结果
- 配置压缩测试
- 配置方式
- 方式一:在配置文件中进行配置:mapred-site.xml
- 所有的程序都做了压缩
- 方式二:在代码中配置:conf.set
- 灵活的管理压缩配置
- 方式三:提交程序的时候指定配置
```
yarn jar xxx.jar -Dkey=value mainclass
```
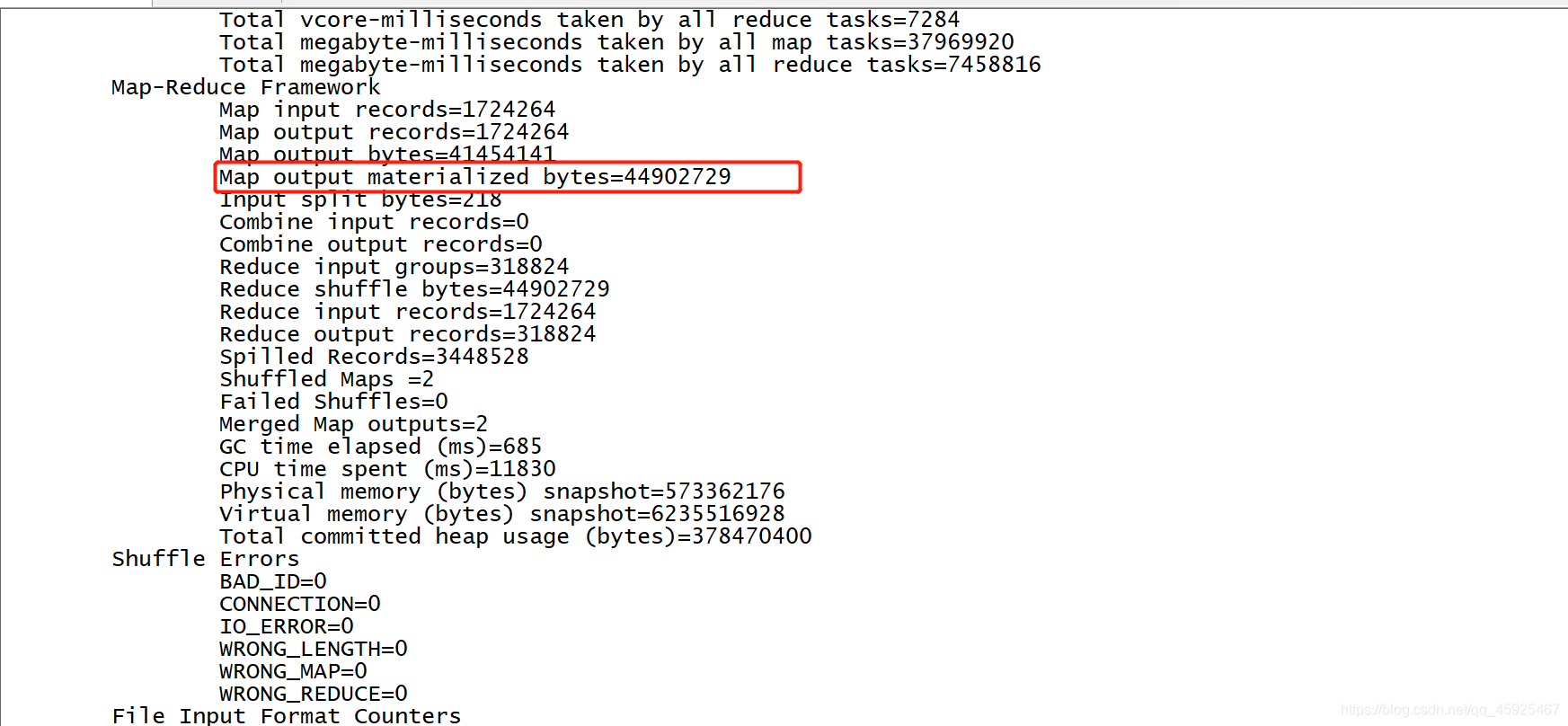
- 运行
```shell
yarn jar compress.jar bigdata.itcast.cn.hadoop.mr.compress.SogouCountCompress /sogou/input /sogou/output2
```
- 结果
小结
- 压缩的好处是什么?
- 降低了数据的存储大小,提高了IO性能
- 常见的压缩类型有哪些?
- snappy、Lzo、Lz4
- MapReduce如何配置压缩?
- 输入压缩:不用配
- Map输出压缩
- 结果输出压缩
- 压缩的好处是什么?
知识点16:Shuffle:分组设计及规则
- 目标:掌握Shuffle中分组的设计及规则
- 路径
- step1:分组设计
- step2:分组规则
- 实施
- 分组设计
- 目的:实现分布式的全局数据分组
- 分组规则
- step1:优先调用分组比较器进行分组比较,判断K2是否为同一组
- step2:如果没有分组比较器,调用K2自带的compareTo方法实现比较,判断K2是否为同一组
- 分组设计
- 小结
- 分组的规则?
- 先判断是否有分组比较器,如果有,就调用分组比较器的比较方法来做分组
- 如果没有,就调用K2自带comparaTo方法来实现比较分组
- 排序比较
- 大于、等于、小于
- 分组比较
- 等于、不等于
- 分组的规则?
知识点17:Shuffle:Top1的需求及实现分析
目标:了解Top1案例的需求及实现分析
路径
- step1:Top1的需求
- step2:实现分析
实施
Top1的需求
数据:订单id、商品id、商品价格
Order_0000001 Pdt_01 222.8 Order_0000001 Pdt_05 25.8 Order_0000002 Pdt_03 522.8 Order_0000002 Pdt_04 122.4 Order_0000002 Pdt_05 722.4 Order_0000003 Pdt_01 222.8 Order_0000003 Pdt_02 1000.8 Order_0000003 Pdt_03 999.8需求
- 统计每个订单价格最高的那个商品的信息
结果
Order_0000001 Pdt_01 222.8 Order_0000002 Pdt_05 722.4 Order_0000003 Pdt_02 1000.8 Order_0000001 Pdt_01 222.8 Order_0000002 Pdt_05 722.4 Order_0000003 Pdt_02 1000.8
实现分析
- step1:结果
- 原来的数据,只要每个订单中商品价格最高的那条
- step2:K2
- 分组:订单
- 排序:价格
- K2:三列封装JavaBean
- 排序:compareTo
- 先比较订单,如果订单一致,再比较价格,将同一个订单的价格降序排序
- 分组:自定义分组比较器
- 按照订单分组
- 排序:compareTo
- V2:Null
- step1:结果
小结
- 了解需求及实现分析
知识点18:Shuffle:Top1的实现
目标:实现Top1的代码开发
实施
step1:自定义数据类型:用于排序
step2:自定义分组比较器
- 规则:开发一个类,继承WritableComparator,重写compare方法
- 实现
step3:代码实现
自定义数据类型
package bigdata.itcast.cn.hadoop.mr.top; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @ClassName OrderBean * @Description TODO * @Date 2021/4/28 16:09 * @Create By Frank */ public class OrderBean implements WritableComparable<OrderBean> { private String orderId; private String pid; private double price; public void setAll(String orderId,String pid,double price){ this.setOrderId(orderId); this.setPid(pid); this.setPrice(price); } public String getOrderId() { return orderId; } public void setOrderId(String orderId) { this.orderId = orderId; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } @Override public String toString() { return this.orderId+"\t"+this.pid+"\t"+this.price; } //只用来做排序 public int compareTo(OrderBean o) { //先比较订单是否一致 int comp = this.getOrderId().compareTo(o.getOrderId()); //如果相等,价格降序排序 if(comp == 0){ return -Double.valueOf(this.getPrice()).compareTo(Double.valueOf(o.getPrice())); } return comp; } public void write(DataOutput out) throws IOException { out.writeUTF(this.orderId); out.writeUTF(this.pid); out.writeDouble(this.price); } public void readFields(DataInput in) throws IOException { this.orderId = in.readUTF(); this.pid = in.readUTF(); this.price = in.readDouble(); } }自定义分组比较器
package bigdata.itcast.cn.hadoop.mr.top; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * @ClassName UserGroup * @Description TODO 自定义分组比较器 * @Date 2021/4/28 16:17 * @Create By Frank */ public class UserGroup extends WritableComparator { public UserGroup(){ super(OrderBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean o1 = (OrderBean) a; OrderBean o2 = (OrderBean) b; //订单相同就是同一组 return o1.getOrderId().compareTo(o2.getOrderId()); } }代码实现
package bigdata.itcast.cn.hadoop.mr.top; import bigdata.itcast.cn.hadoop.mr.mode.MRMapperMode; import bigdata.itcast.cn.hadoop.mr.mode.MRReducerMode; import org.apache.commons.lang.ObjectUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRDriverMode * @Description TODO MapReduce编程模板,Driver类 * @Date 2021/4/26 14:31 * @Create By Frank */ public class OrderTopMR extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"orderTop"); //指定允许jar包运行的类 job.setJarByClass(OrderTopMR.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源 Path inputPath = new Path("datas/orders/orders.txt");//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(OrderMapper.class); //设置调用的Mapper类 job.setMapOutputKeyClass(OrderBean.class); //设置K2的类型 job.setMapOutputValueClass(NullWritable.class); //设置V2的类型 //Shuffle:配置Shuffle // job.setPartitionerClass(null); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 job.setGroupingComparatorClass(UserGroup.class); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(OrderReducer.class); //设置调用reduce的类 job.setOutputKeyClass(OrderBean.class); //设置K3的类型 job.setOutputValueClass(NullWritable.class); //设置V3的类型 // job.setNumReduceTasks(1); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path("datas/output/order/order2"); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new OrderTopMR(), args); //退出程序 System.exit(status); } public static class OrderMapper extends Mapper<LongWritable,Text,OrderBean, NullWritable>{ //K2 OrderBean outputKey = new OrderBean(); //V2 NullWritable outputValue = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] items = value.toString().split("\\s+"); this.outputKey.setAll(items[0],items[1],Double.parseDouble(items[2])); //输出 context.write(this.outputKey,this.outputValue); } } public static class OrderReducer extends Reducer<OrderBean, NullWritable,OrderBean, NullWritable>{ @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //输出每个订单价格最高的那一条 // context.write(key,NullWritable.get()); for (NullWritable value : values) { context.write(key,value); } } } }
统计每个地区二手房的个数、平均单价、最高单价、最低单价
- K2:地区
- V2:单价
reduce(K2,Iter<V2> values){ List[IntWritable] lists = new List for(value:values){ lists.add(value) } } | reduce(K2,Iter<V2> values){ List[int] lists = new List for(value:values){ lists.add(value.get) } } reduce(K2,Iter<V2> values){ List[IntWritable] lists = new List for(value:values){ bean = new Intwritable bean = value lists.add(bean) } }
小结
- 如何实现自定义分组?
- 与排序比较器基本一致
- 如何实现自定义分组?
附录一:MapReduce编程依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>
String[] items = value.toString().split("\s+");
this.outputKey.setAll(items[0],items[1],Double.parseDouble(items[2]));
//输出
context.write(this.outputKey,this.outputValue);
}
}
public static class OrderReducer extends Reducer<OrderBean, NullWritable,OrderBean, NullWritable>{
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//输出每个订单价格最高的那一条
context.write(key,NullWritable.get());
// for (NullWritable value : values) {
// context.write(key,value);
// }
}
}
}
```
统计每个地区二手房的个数、平均单价、最高单价、最低单价
- K2:地区
- V2:单价
reduce(K2,Iter<V2> values){ List[IntWritable] lists = new List for(value:values){ lists.add(value) } } | reduce(K2,Iter<V2> values){ List[int] lists = new List for(value:values){ lists.add(value.get) } } reduce(K2,Iter<V2> values){ List[IntWritable] lists = new List for(value:values){ bean = new Intwritable bean = value lists.add(bean) } }小结
- 如何实现自定义分组?
- 与排序比较器基本一致
- 如何实现自定义分组?