MapReduce的简介:
MapReduce是一个软件框架,客房部件的编写应用程序,一并行的方式在数千商用硬件组成的集群节点中处理TB级的数据,并且提供了可靠性和容错的能力。
MapReduce的范式:
MapReduce处理模型包括两个独立的步骤:
A. 第一步是并行Map阶段,输入数据被分割成离散块以便可以单独处理
B. Shuffle阶段
C. 第二步是Reduce阶段,汇总Map阶段的输出生成预期的结果。
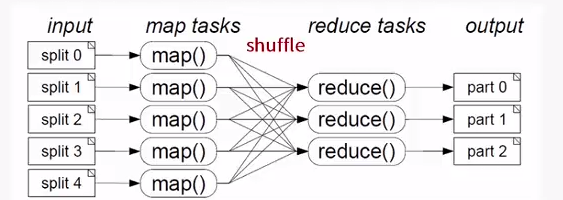
MapReduce的缺陷:
A. 可扩展性:
a) JobTracker内存中保存用户作业的信息
b) JobTracker使用的是粗粒度的锁
B. 可靠性和可用性:
a) JobTracker失效会多事集群中所有的运行作业,用户需手动重新提交和恢复工作流
C. 对不同编程模型的支持
a) HadoopV1以MapReduce为中心的设计虽然能支持广泛的用例,但是并不适合所有大型计算
版权声明:本文为s646575997原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。