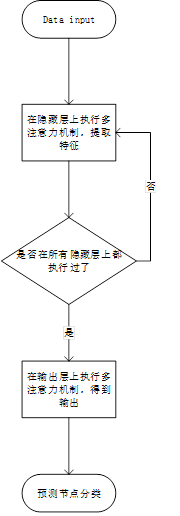
论文里面实现的GAT网络是多注意力机制的,直接理解起来很困难,这里我们就先从单注意力机制的GAT网络说起。
一、单注意力机制
先来看看单注意力下,GAT网络的工作流程(以代码中的demo为例):
上述流程图也可以简化为: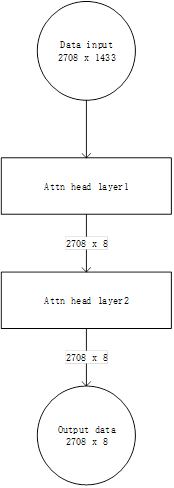
这里将特征提取层、attention layer与hidden layer(output layer)合并为了一个attn head layer,论文中也明确指出GAT仅仅attn head layer组成。
接下来我们将attn head layer视为一层,来介绍其中每个子层的作用:
1、 特征提取层
这里给出几个符号定义:
(1) F1:表示输入attn head layer的特征向量长度
(2) F2:表示attn head layer输出的特征向量长度
(3) nodes:表示图的顶点个数
(4) Feature_in:输入特征向量矩阵,大小为:(nodes,F1)
(5) Feature_out:输出特征向量矩阵,大小为:(nodes,F2)
(6) W1:表示该层的权重矩阵,大小为:(F2,1,F1)。
(7) W1_1:表示W1的第一个卷积核,大小为(1,F1)。
算法流程:
(1)将W1_1从上往下滑动与Feature_in矩阵进行卷积,可以得到一个大小为(nodes,1)的新的特征向量。
(2)其余的卷积核也依次进行该项操作,则可以得到F2个大小为(nodes,1)的向量,将其拼接起来得到Feature_out。
到此为止,特征提取操作结束
2、 Attention layer
同样的,给出几个符号定义,方便快速理解:
(1) A:表示该层的权重,大小为:(1,2 × F2)
(2) A1:A的前半部分,大小为:(1,F2)
(3) A2:A的后半部分,大小为:(1,F2)
(4) Feature_out:特征提取层输出的特征向量,大小:(nodes,F2)
这里给出算法流程:
(1)用A1对Feature_out进行一维卷积操作,得到大小为:(nodes,1)的向量C
(2)用A2对Feature_out进行一维卷积操作,得到大小为:(nodes,1)的向量D
(3)将D进行转置,得到大小为:(1,nodes)的行向量D1
(4)利用TensorFlow的广播机制,将C与D1相加,得到矩阵E,大小:(nodes,nodes)
这里对应论文: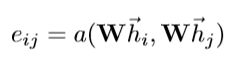
(5)对E矩阵的每一行做activate操作与softmax操作,得到一个大小为(nodes,nodes)的系数矩阵:Coef
这里对应论文公式: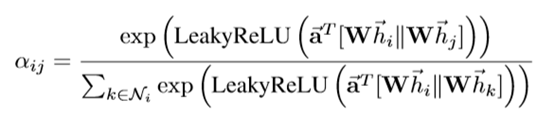
(6)输出系数矩阵Coef
Attention layer层的工作完成
3、 Hidden layer
Hidden layer接收到从特征提取层传来的特征向量Feature_out(大小:(nodes,F2))和attention layer(大小:(nodes,nodes))的系数矩阵Coef,两者做矩阵乘法运算。
对应论文公式: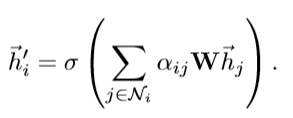
4、 Output layer
功能与hidden layer一致
二、多注意力机制
多注意力机制,采用多个单注意力机制对图中的每个顶点进行计算,最后取平均值。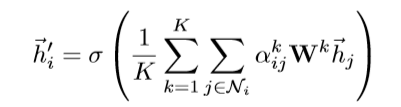
代码推理流程图: