BILSTM模型初始化
1.torch.nn.Embedding
self.embedding = nn.Embedding(vocab_size,embedding_size,padding_idx=pad_idx)
- num_embeddings:嵌入字典的大小(词的个数);
- embedding_dim:每个嵌入向量的大小;
- padding_idx:若给定,则每遇到 padding_idx 时,位于 padding_idx 的嵌入向量(即 padding_idx 映射所对应的向量)为0;
功能:将已经映射为数字的文本映射为embedding_dim维的向量,
输入:文本的 Long Tensor;
输出:输出 shape =(*,H),其中 * 为输入的 shape,H = embedding_dim(若输入 shape 为 N*M,则输出 shape 为 N*M*H);
torch.nn.Embedding 的权重为 num_embeddings * embedding_dim 的矩阵,例如输入10行,每行最多5个词,每个词用3为向量表示,则权重为10*5*3的矩阵;
import torch
from torch import nn
embedding = nn.Embedding(5, 4) # 假定字典中只有5个词,词向量维度为4
word = [[1, 2, 3],
[2, 3, 4]] # 每个数字代表一个词,例如 {'!':0,'how':1, 'are':2, 'you':3, 'ok':4}
#而且这些数字的范围只能在0~4之间,因为上面定义了只有5个词
embed = embedding(torch.LongTensor(word))
print(embed)
print(embed.size())
此外,我们也可以自己导入权重参数:
from_pretrained
介绍:
从给定的二维FloatTensor创建embedding实例。
参数:
embeddings - 包含嵌入权重的FloatTensor。
第一个维度作为num_embeddings(这里是2)传递给Embedding,第二个维度作为Embedding_dim(这里是3)传递给Embedding。
1.2.torch.nn.LSTM
先来看看RNN的数据流动情况
仔细看数据之间的一个传播过程可以很好地理解循环神经网络的运行过程。
以下部分是对于上图的解说,看得懂的可以直接跳到双向循环神经网络(BRNN)部分。
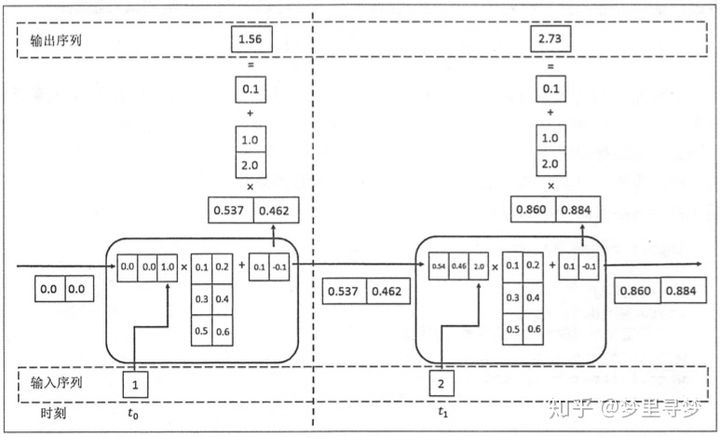
如上图所示,假设节点状态的维度为2,节点的输入和输出维度为1,那么在循环体的全连接层神经网络的输入维度为3,也就是将上一时刻的状态与当前时刻的输入拼接成一维向量作为循环体的全连接层神经网络的输入,在这里t0时刻的节点状态初始化为[0.0, 0.0],t0时刻的节点输入为[1.0],拼接之后循环体的全连接层神经网络的输入为[0.0, 0.0, 1.0],循环体中的全连接层的权重表示为二维矩阵[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]],偏置项为[0.1, -0.1],我们可以看到权重矩阵和偏置项在t0和t1时刻的循环体中是一样的,这也说明了RNN结构中的参数在不同时刻中也是共享的。经过循环体中的全连接层神经网络后节点的状态改变为tanh([0.6, 0.5]) = [0.537, 0.462],当前节点状态的输出作为下一个节点状态的输入。
为了将当前时刻的状态转变为节点的最终输出,RNN中还有另外一个全连接神经网络来计算节点输出,在图2中被表示为[0.537, 0.462] * [1.0, 2.0] + [0.1] = [1.56],用于输出的全连接层权重为[1.0, 2.0],偏置项为[0.1],1.56表示为t0时刻节点的最终输出。
得到RNN的前向传播结果之后,和其他神经网络类似,定义损失函数,使用反向传播算法和梯度下降算法训练模型,但RNN唯一的区别在于:由于它每个时刻的节点都有一个输出,所以RNN的总损失为所有时刻(或部分时刻)上的损失和。
BILSTM的输入:
self.encoder = nn.LSTM(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True)
输出:
packed_output, (hidden, cell) = self.encoder(packed_embedded)
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))假设我现在有个句子,有10个token,也就是10个timestep, 每个timestep对应的时刻上特征维度是100, 那么input_size就是100.。
而hidden_size就是下图黄色圆圈部分,可以自己定义,设其为300

再看看输出部分:输出分为三个部分,如下图,output的size是(句子长度,batch_size,hidden*2)看上图也知道有多少个hidden,output输出就有多少个,h的输出是(2,batch_size,hidden),

decoder部分:由于做情感分析,所以decoder部分直接现将输出的双向的H,按dim=1拼接在一起,然后通过全连接层(所谓全连接层,就是将输入拉成一条直线,)映射为二分类。
self.decoder = nn.Linear(2 * hidden_size,2)hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
outs = self.decoder(hidden)