摘要
深度学习方法使用多个处理层来学习数据的层次表示,并在许多领域产生了最先进的结果。近年来,在自然语言处理(NLP)的背景下,各种模型设计和方法得到了蓬勃发展。在这篇综述中,我们回顾了许多NLP任务中所使用的重要的深度学习相关模型和方法。在综述中,我们提到了序列生成方法,神经机器翻译,对话系统的模型,并叙述了它们的发展过程。与此我们还对各种模型进行了总结、比较和对比,并对NLP中深度学习的过去、现在和未来进行了详细的了解。同时,我们也深入探讨了现在主流的几种算法。
关键词:深度学习,自然语言处理,序列生成技术,机器翻译,对话系统
1.研究背景及意义
深度学习体系结构和算法在计算机视觉和模式识别等领域已经取得了令人瞩目的进展。随着这一趋势,近年来的关于NLP研究越来越多地使用新的深度学习方法。针对NLP问题的机器学习方法是基于浅层模型的(例SVM和逻辑回归),大多数的语言信息用稀疏表示(高维特征)表示,这导致诸如维数灾难之类的问题。近年来,基于密集向量表示的神经网络在各种NLP任务中取得了较好的效果。这一趋势是由词嵌入和深度学习方法的成功引发的。深度学习可以实现多层次的自动特征表示学习。相比之下,传统的基于机器学习的NLP系统在很大程度上依赖于手工构建的特征。这种手工构建的特征常耗大量的时间和成本,并且不同任务所需要的特征又是不同的。
自然语言处理(NLP)是一种基于理论的计算技术,用于人类语言的自动分析和表达。NLP的研究已经从打卡和批处理的时代(一个句子的分析时间可以长达7分钟)发展过来,到现在可以在不到一秒的时间内可以处理数百万个网页。NLP使计算机能够在所有级别上执行广泛的自然语言相关任务,从解析和词性标记到机器翻译和对话系统。
自然语言处理(NLP)通过计算技术学习、理解然后产生人类语言。NLP中有许多有意义的研究方向。其中包括序列生成,机器翻译,对话系统。NLP还有一些其他的主题。计算机视觉与NLP的集成,如视觉字幕、视觉对话、视觉关系和属性检测。
在过去的几年中,深度学习(DL)架构和算法在图像识别和语音处理等领域取得了令人瞩目的进步。它们在自然语言处理(NLP)中的应用起初并不那么令人印象深刻,但现在已经证明可以做出重大贡献,为一些常见的NLP任务提供最先进的结果。命名实体识别(NER),词性(POS)标记或情感分析是神经网络模型优于传统方法的一些问题。机器翻译的进步可能是最引人注目的。
R. Collobert 等人[1],证实了一个简单的深度学习框架在几个NLP任务(如命名实体识别(NER)、语义角色标注(SRL)和词性标注(POS),具体分析见附录)方面的性能优于最先进的方法。此后,针对复杂的NLP任务,提出了大量基于深度学习的复杂算法。这其中包括应用于自然语言任务的主要深度学习相关模型和方法,如卷积神经网络(CNNs)、循环神经网络(RNNs)和递归神经网络。还包括增强记忆策略、注意力机制以及无监督模型、强化学习方法以及最近的深度生成模型是如何应用于与语言相关任务的。
2.当前研究现状
在过去几年中,深度学习改变了整个景观。每天,有更多的应用程序依赖于医疗保健,金融,人力资源,零售,地震检测和自动驾驶汽车等领域的深度学习技术。至于现有的应用,结果一直在稳步提高。
在学术层面,机器学习领域变得如此重要,以至于每20分钟就会出现一篇新的科学文章。
而且,深度学习已经渗透到NLP的许多子领域,并帮助取得重大进展。对于深度学习算法和非深度学习算法,以及基于无领域知识的方法和基于语言学知识的方法,NLP似乎仍然是一个关于协同而不是竞争的领域。一些非深度学习算法是有效且表现良好的,如word2vec 和fastText等。
在2018年,深度学习也取得了一些主要进展。但最受关注的是Google AI语言团队发表了一篇BERT语言模型论文[1]。在自然语言处理(NLP)中,语言模型是可以估计一组语言单元(通常是单词序列)的概率分布的模型。这些是有趣的模型,因为它们可以以很低的成本构建,并且显著改进了几个NLP任务,例如机器翻译,语音识别和解析。之前,最著名的方法是马尔可夫模型和n-gram模型。随着深度学习的出现,出现了一些基于长短期记忆网络(LSTM)的更强大的模型。虽然高效,但现有模型通常是单向的,这意味着只有单词的左(或右)的有序序列才会被考虑。但在18年10月份,Google AI语言团队提出的深度双向变换器模型,不仅解决了单向模型的问题。而且该模型可实现11种NLP任务的最先进性能,包括斯坦福问答(SQUAD)数据集。
强化学习也在自然语言处理上取得了巨大的进步,因为目前的自然语言处理大多都是一个离散空间的自然语言处理、生成或者是序列决策,这时,我们很天然地可以利用到强化学习去拟合和运作。强化学习下的几种分类在自然语言处理的任务中,也都取得了非常优异的成果。例如value-based RL(基于价值函数),policy-based RL(基于策略的函数),model-based RL(基于模型的函数)。
2018年,在各种领域被搜索的最多的词条是自然语言处理(NLP)和生成对抗网络。在Github上最流行的生成对抗网络方法包括:vid2vid, DeOldify, CycleGAN and faceswaps。最流行的NLP方法包括:BERT, HanLP, jieba, AllenNLP and fastText。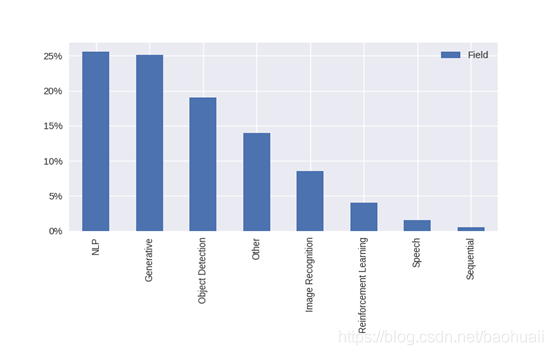
3.基本理论分析
3.1 序列生成技术
序列可以采用文本、音乐、分子等形式。序列生成技术可以应用于多个领域,包括与音乐旋律有关的实验和计算分子生成[4]。本节主要研究文本生成问题,因为文本生成是会话响应生成、机器翻译、抽象摘要等许多NLP问题的基础。
最开始,文本生成模型通常基于n-gram、前馈神经网络或递归神经网络,训练它们根据前面的基础真词作为输入,预测下一个单词,生成的模型用于整个序列;然后在测试中,使用训练的模型逐字生成序列,并将生成的单词作为输入。再对这些模型进行词级损失的训练,如交叉熵,使下一个词的概率最大化。不过这些模型在用于生成文本时存在两个主要缺陷。首先,他们被训练预测下一个单词时,给定之前的基础真词作为输入。但是,在测试时,通过每次预测一个单词,并在下一次步骤中将生成的单词作为输入返回,生成的模型用于生成整个序列。这个过程非常脆弱,因为模型是在不同的输入分布上进行训练的,即从数据分布中提取的单词,而不是从模型分布中提取的单词。因此,在此过程中所犯的错误将迅速累积。我们把这种差异称为暴露偏差,即一个模型只暴露于训练数据的分配,而不是它自己的预测。其次,用于训练这些模型的损失函数是字级的。一个流行的选择是交叉熵损失,用来最大化下一个正确单词的概率。然而,这些模型的性能通常使用离散的度量来评估。
针对这一问题,现在有一种新的序列级训练算法[5],为混合增量交叉熵增强(MIXER),因为它结合了XENT和增强,还有增量学习。第一个关键思想是改变增强的初始策略,以确保模型能够有效地处理文本生成的巨大操作空间。而不是从一个糟糕的随机策略开始训练模型收敛到最优策略,作者从最优策略开始,然后慢慢偏离它,让模型去探索和利用它自己的预测。第二个关键思想为在退火过程中引入模型预测,以逐步教会模型生成稳定的序列。
这种方法可以直接优化测试时使用的度量,如BLEU或ROUGE。在三个不同的任务上,方法优于贪婪生成的几个强大基线。当这些基线使用波束搜索时,这种方法也很有竞争力,而且速度要快几倍。
Bahdanau et al.(2017)提出了一种序列预测的actor-critic算法[6],以改进序列级训练算法[5]。作者利用一个评估网络来预测一个token的值,即,序列预测策略下的期望得分,由行动者网络定义,通过训练来预测tokens的值。采用了一些技术来提高性能:用SARSA而不是蒙特卡罗方法来减少估计值函数的方差;稳定的目标网络;这种训练神经网络的方法是使用来自强化学习的 actor-critic 方法来生成序列。结果显示,这种方法提升了在合成任务(synthetic task)以及德英机器翻译任务上的表现。作者的分析为这样的方法在自然语言生成任务上的应用铺平了道路,比如机器翻译、图片描述生成、对话模型。
Bahdanau提出的论文有两个重要的贡献,首先它描述了强化学习中像 actor-critic 方法这样的方法能被应用于带有结构化输出的监督学习问题上,然后调查了新方法在合成任务以及机器翻译这样的真实世界任务上的表现与行为,展示了由 actor- critic 带来的在最大似然方法以及 REINFORCE 方法上的改进。
生成对抗网(GAN)是一种新的生成模型训练方法,它利用判别模型来指导生成模型的训练,在生成实际数据方面取得了很大的成功。GAN 网络在计算机视觉上已经得到了很好的应用,然而,其在自然语言处理上并不是很有效,最初的 GAN 仅仅定义在实数领域,GAN 通过训练出的生成器来产生合成数据,然后在合成数据上运行判别器,判别器的输出梯度将会告诉你,如何通过略微改变合成数据而使其更加现实。然而,当目标是生成离散tokens序列时,它有局限性。主要原因是生成模型的离散输出使得判别模型的梯度更新难以传递到生成模型。另外,判别模型只能对一个完整的序列进行评估,而对于一个部分生成的序列,一旦生成了整个序列,要平衡其当前的分数和未来的分数是很重要的。
例如,如果你输出了一张图片,其像素值是1.0,那么接下来你可以将这个值改为1.0001。如果输出了一个单词“penguin”,那么接下来就不能将其改变为“penguin + .001”,因为没有“penguin +.001”这个单词。 因为所有的自然语言处理(NLP)的基础都是离散值,如“单词”、“字母”或者“音节”,NLP 中应用 GANs 是非常困难的。
随后,Yu等人也提出了SeqGAN,解决了上述问题。即具有策略梯度的序列生成式对抗网络[7],来解决这些问题,将数据生成器建模为强化学习(RL)中的随机策略,SeqGAN通过直接执行梯度策略更新来绕过生成器的微分问题。RL激励信号来自基于完整序列判断的GAN 鉴别器,并通过蒙特卡罗搜索返回到中间状态动作步骤。在合成数据和真实任务上的大量实验表明,与强大的基线相比,它们有了显著的改进。SeqGAN的结构图,如图3.1所示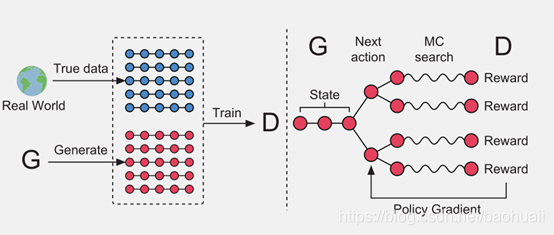
右:D是训练完毕真实数据和G是生成的数据。左:G是受过训练根据提供最终激励信号的政策梯度,并通过它传递回中间操作值蒙特卡罗搜索。
参考文献
[1].R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa, “Natural language processing (almost)from scratch,” Journal of Machine Learning Research, vol. 12, no. Aug, pp. 2493–2537, 2011.
[2]. Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3]Young T, Hazarika D, Poria S, et al. Recent trends in deep learning based natural language processing[J]. ieee Computational intelligenCe magazine, 2018, 13(3): 55-75.
[4]Jaques N, Gu S, Bahdanau D, et al. Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control[J]. arXiv preprint arXiv:1611.02796, 2016.
[5] Ranzato M A, Chopra S, Auli M, et al. Sequence level training with recurrent neural networks[J]. arXiv preprint arXiv:1511.06732, 2015.
[6] Bahdanau D, Brakel P, Xu K, et al. An actor-critic algorithm for sequence prediction[J]. arXiv preprint arXiv:1607.07086, 2016
[7] Yu L, Zhang W, Wang J, et al. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient[C]//AAAI. 2017: 2852-2858.