mysql应用性能优化拓展
通用性能优化口诀:
缓存(三级缓存),异步(异步同步数据),批处理(写操作)。
写操作:批量insert,批量update,避免for循环。
读操作:索引(数据库层面只有一个)
mysql批量写:
for each{insert into table value(1)} -> Excute once insert into table values (1),(2),(3),(4)...
mysql批量写优势:
1.Sql编译N次和1次的时间与空间复杂度。
2.网络消耗的时间复杂度。
3.磁盘寻址的复杂度。
mysql查询索引:
1.主键查询 千万条记录:1-10ms
2.唯一索引 千万条记录:10-100ms
3.非唯一索引 千万条记录:100-1000ms
4.无索引 百万条记录 1000ms+
mysql单机配置型性能优化拓展:
注:mysql会有WAL(写前记录日志机制undo/redo)
mysql执行流程图:
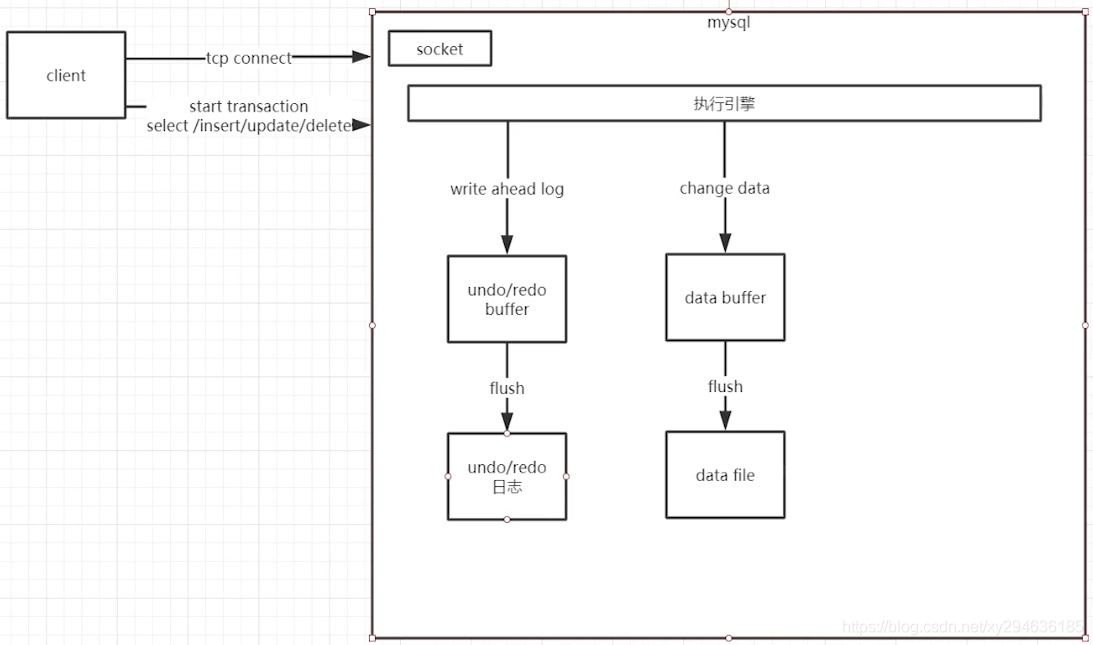
修改配置参数:
max_connection=1000
innodb_file_per_table=1(使用innodb并且database里面每一个table做为一张表)
innodb_buffer_pool_size=1G(占这台服务器内存的60%-80%,一般读的主键会在buffer_pool_size内)
innodb_log_file_size=256M(根据机器属性设置,在日志记录满了后会切换日志文件时候记录临时日志用的缓冲大小)
innodb_log_buffer_size=16M
innodb_flush_log_at_trx_commit=2(需要放在[mysqld_safe]节点下)每次事务提交立即刷入磁盘
innodb_data_file_path=ibdata1:1G;ibdata2:1G;ibdata3:1G:autoextend(mysql文件分区)当记录data文件大到1G时存到ibdata1中,在到1G放在ibdata2中。
mysql分布式配置性能优化拓展:
主从分布式扩展:
1.开启bin_log:所有的操作记录在bin_log中,配置slave从库,做读写分离,所有写操作记录在主库,读操作在从库,从库只需要同步主库bin_log,但是读操作存在主从同步时间的延迟。
2.设置主从同步账号,配置主从同步
搜索功能:
模糊查询:where name like '%xx%'(会做全表扫描,非常慢)
搜索引擎:详见es搜索引擎
多主多从:
数据分片:hash+mode先确定分片键:对这个id做hash取后两位做分片键,再用mode方式均匀分布到不同的数据库上。读的时候先根据id做mode的hash+mode的操作,路由到对应属于的集群节点的slave上。
分片维度:
固定路由位:选取用户id作为路由位,取后两位做hash,mode数据库的数量就可以保证用户可以以用户id为维度路由到唯一的数据库上一次性查询到所有的数据。
时间自增分片:对于时间自增长的数据我们可以把每隔一段时间段中所有的数据放在一个数据库内,这样也可以保证在时间维度上命中同一个数据库。
分片冗余一致性保障:RocetMQ
无迁移扩展:分库策略发生变化时,mode位的hash也会发生变化,势必造成数据迁移。解决方案:
1.mod位数据迁移
2.弹性自增
一致性原理:
1.最强一致:ACID事务要么全部成功,要么全部失败。
2.弱一致性:两个数据库存储的信息在网络延迟或丢包下发生数据不一致
3.最终一致性:RocketMQ等消息中间件达到最终一致性
所以在互联网分布式理论下不追求事务ACID完全一致,而追求CAP理论,只可得两者,不可得三者,p必须得得到保障,C,A须牺牲一个,所以又衍生是出BASE理论。
CAP:
C:一致性(只需保证最终一致性,牺牲)
A:可用性
P:分片性(必须)
BASE:
Basic available:基本可用
S:软状态
E:最终一致性
要保证主库master通过异步binlog写入到从库slave中的强一致性,需要二阶段提交: