可分离卷积分为:空间可分离卷积与深度可分离卷积
MobileNet用的是深度可分离卷积
深度可分离卷积:
深度可分离卷积=深度卷积(depthwise convolution)+逐点卷积(pointwise convolution)
一、MobileNet V1
详解
1.
设输入特征图是M维,卷积核是Dk * Dk,输出特征图是N维,大小是Dg * Dg
普通卷积: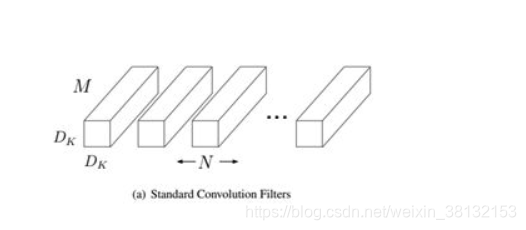
计算量:Dk * Dk * M * N * Dg * Dg
计算量:5 * 5 * 3 * 256 * 8 * 8 ≈ 123W
深度卷积:
计算量:Dk * Dk * M * Dg * Dg
计算量:5 * 5 * 3 * 8 * 8 = 4800
逐点卷积:
计算量:1 * 1 * M * N * Dg * Dg
计算量:1 * 1 * 3 * 256 * 8 * 8 = 49152
深度可分离卷积总计算量:49152+4800≈5.3w<<123w
计算量减少:
当为3 * 3的卷积核,计算量大约是原来的1/9
2、普通卷积层与MobileNet卷积层:
ReLU6:x值大于6的时候,y取6,即给ReLU一个上限6
3、网络结构:
4、MobileNet瘦身:
(1)宽度乘数: α,减少通道数
α取值范围为(0,1],那么输入与输出通道数将变成αM和αN
(2)分辨率乘数: ρ ,减少表达能力
分辨率乘数 ρ ,比如原来输入特征图是224x224, ρ 为6/7,分辨率可以减少为192x192。分辨率乘数用来改变输入数据层的分辨率,同样也能减少参数。ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128}
二、MobileNet V2
V2在V1的基础上,引入了Inverted Residuals和Linear Bottlenecks。
epthwise部分的卷积核容易费掉,即卷积核大部分为零。参考直达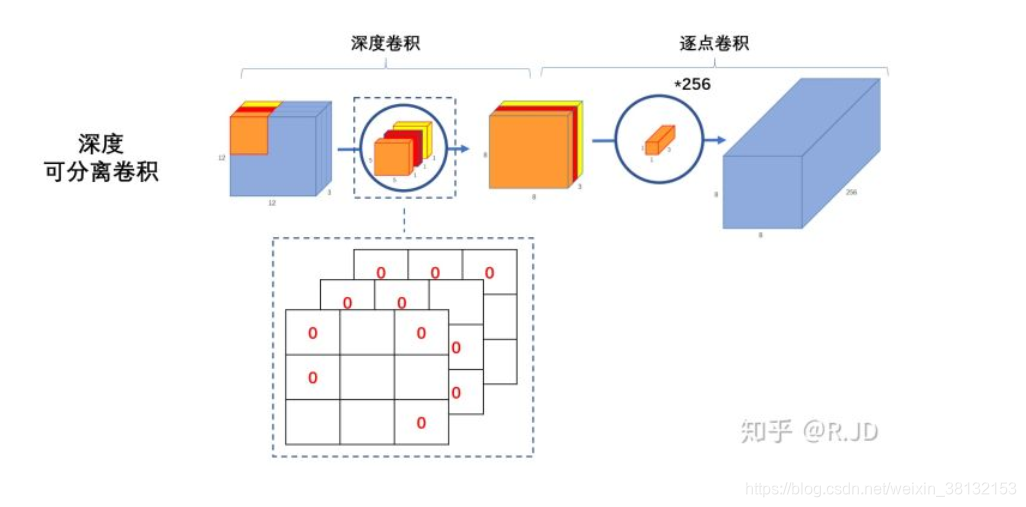

二维空间的input映射到dim=2,dim=3中,很多信息都丢失了,所以在低维度进行ReLU会丢失很多信息,在高维度ReLU丢失的信息较少。
将ReLU替换成线性激活函数。
1、Linear Bottlenecks
把最后的那个ReLU6换成Linear
深度卷积在低维效果并不是很好,所以我们要先用逐点卷积对其升维,再经过一个深度卷积,最后通过一个逐点卷积对其降维
2、Inverted residuals
当stride=1时,输入首先经过11的卷积进行通道数的扩张,此时激活函数为ReLU6;然后经过33的depthwise卷积,激活函数是ReLU6;接着经过1*1的pointwise卷积,将通道数压缩回去,激活函数是linear;最后使用shortcut,将两者进行相加。而当stride=2时,由于input和output的特征图的尺寸不一致,所以就没有shortcut了。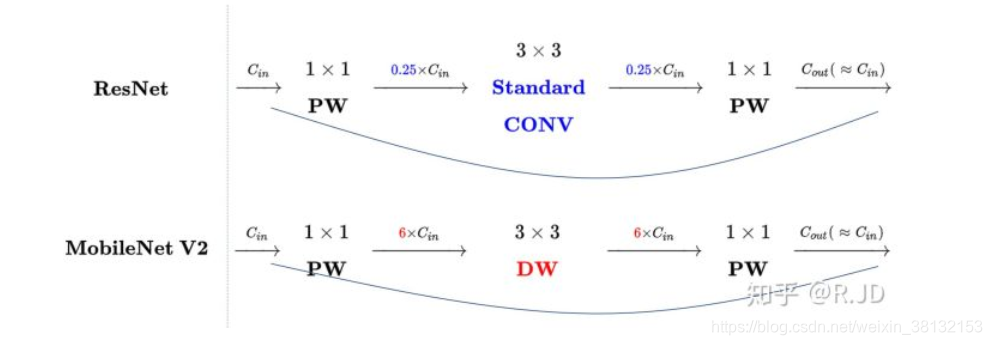
可以发现,都采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,以及都使用Shortcut结构。但是不同点呢:
(1)resnet中是使用1×1卷积将通道数降低,再经过3×3卷积,最后再用1×1将通道数复原。
(2)mobilenet v2是在dw convolution前使用1×1卷积将通道数上升,再使用3×3的dw conv,最后再用1×1conv降低通道数,这样做的好处是可以让dw conv获取到更多的特征。
刚好V2的block刚好与Resnet的block相反,作者将其命名为Inverted residuals。
3、V1 V2对比
4、网络结构:
三、MobileNet V3
1、h-swish激活函数
swish激活函数:f(x) = x * sigmoid(βx),其中β是一个常数或者可训练的参数。
但是sigmoid对于移动设备的计算量太大了,而且ReLU6又是一个及其简单的函数,所以可以用ReLU6来近似逼近sigmoid(βx),所以提出了
h-swish:

2、对V2最后阶段的修改
作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将平均池化层提前了。在使用1×1卷积进行扩张后,就紧接池化层-激活函数,最后使用1×1的卷积进行输出。
3、V3的block
SE模块: 学习了channel之间的相关性,筛选出了针对通道的注意力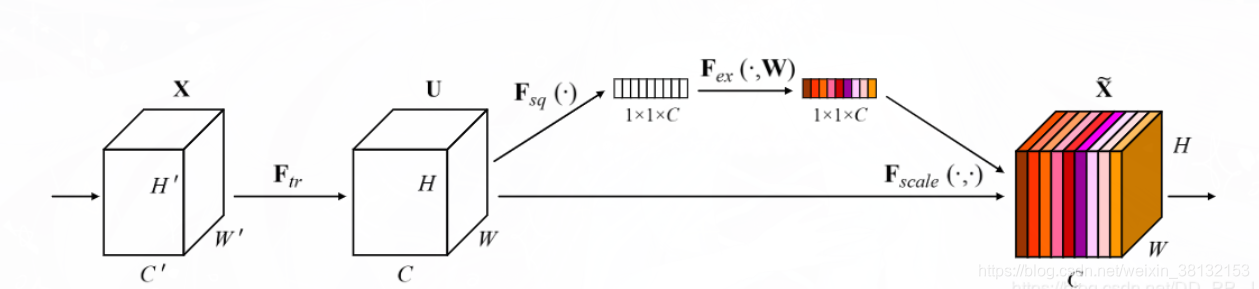

class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
(1)Sequeeze 对C×H×W 进行global average pooling,得到 1×1×C 大小的特征图,这个特征图可以理解为具有全局感受野。
(2)Excitation :使用一个全连接神经网络,对Sequeeze之后的结果做一个非线性变换。
(3)特征重标定:使用Excitation 得到的结果作为权重,乘到输入特征上。
在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。
4、网络结构:
参考:https://zhuanlan.zhihu.com/p/70703846
https://www.cnblogs.com/dengshunge/p/11334640.html
https://www.cnblogs.com/pprp/p/12128520.html