n元语法模型
1) 马尔可夫假设:当过程t时刻状态已知,过程t+1时刻所处状态的概率特性仅与t时刻所处状态相关。它是一个具有无后效性的假设。
结合马尔可夫假设,得到n元语法模型的定义:假设当前词出现的概率仅依赖于前n-1个词
P(wi|w1,w2,…wi-1) =P(wi|wi-(n-1),…,wi)
2)评价指标
交叉熵
p表示样本x的真实分布,q表示对其建模得到的分布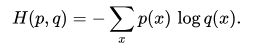
困惑度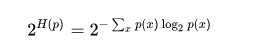
显然,困惑度也是越小越好
NNLM
神经网络语言模型是学习单词序列分布的统计模型,而不是句子中单个词语
实际上,RNN、LSTM、BERT等都属于神经网络语言模型的一种。
word2vec
word2vec分为CBOW(连续词袋)、Skip-gram(跳字模型)
1)CBOW
是通过上下文单词对中间词的词向量进行预测的一种方式
该方法忽略了约接近中心词的词语与中心词的相关性应该越高的原则。
2)Skip-gram
与CBOW模型相反,通过中心词对上下文进行预测
word2vec模型解决了one-hot向量高位、稀疏的缺陷,将之转换成低维、稠密的向量。随之而来的问题是,当vocab很大时,输出层的softmax在计算各个词出现的概率时计算量很大,需要对其进行优化。
3)优化方法
Hierarchical Softmax。借鉴哈夫曼树,哈夫曼树是一种最优二叉树,其带权路径最短。就是将word2vec输出层中的softmax替换成哈夫曼树的优化方法。
Negative Sampling。将中心词视为正例,词表中其他词是为反例。
参考:负采样理解,负采样
Glove
Glove使用了全局语义信息。在Glove出现之前,学习词向量的方法主要分类两类:全局矩阵分解(如LSA)和局部上下文窗口法(如word2vec)。word2vec虽然在词汇类比方面具有很好的效果,但由于其局部上下文窗口方式,不能有效利用全局的词汇共现信息。
实现步骤如下:
1)构建共现矩阵X。共现矩阵参考:共现矩阵
2)构建词向量与贡献矩阵关系。
3)构造损失函数
备注:word2vec、fastText、Glove属于静态词向量。Bert、GPT、Elmo属于动态词向量
参考:词向量总结