阅读提示
为了更好理解这篇文章,你可能需要了解:
- 两因素方差分析
- 平方和的分解
- 方差分析模型
- 虚拟变量
推荐先阅读
- 用回归来理解方差分析(一):单因素方差分析
- 用回归来理解方差分析(二):两因素方差分析
文中涉及到的代码只是为了验算,如果不熟悉代码的同学可以忽略,直接看结果就行。也可以自己动手尝试用SPSS验算。
1 先来回顾一下平方和
平方和(Sum of Squares)指:对离均差的平方求和。平方和体现了数据总体的变异性。用平方和除以自由度,得到了数据平均的变异性,也就是我们熟悉的方差。
计算平方和是进行方差分析的重要步骤,毕竟方差就是要通过平方和得出。以一个
其中
- 总平方和:各观测值
与总均值
- 组间平方和:组均值
- 组内平方和:各组的观测值
可以发现此时的总平方和刚好等于组内平方和与组间平方和之和。
不过还没有分解完,对于多因素设计来说,组间平方和还可以进一步分解为主效应和交互作用。
- 主效应平方和:此时单独考虑某个自变量带来的效应。例如计算
此时由于
同理,只考虑
- 交互作用平方和NO!NO!NO!,如果这样做的话你发现计算出来的交互作用平方和与组间平方和一模一样。交互作用是指总平均叠加上A的主效应和B的主效应之后,额外多出来的那一部分。以
至此,平方和全都分解完毕,可以看到组间平方和
是不是所有的平方和都是这么分解呢?NO!NO!NO!当然不是,刚才的这种分解方法仅限于等组设计,如果各处理的观测值数量(样本量)不相等时,刚才这种方法就不可行了。
2 不等组设计的平方和
让我们对之前的数据动动小手术,改为:
尝试一下传统的平方和分解
按照之前的方法,先计算总平方和:
组内平方和:
组间平方和(此时由于各组样本量不同,所以
这三个都没有问题,但是。
重头戏来了,组间平方和,该怎么进一步分解呢?
以
万万不可!!!!
因为此时
本来的目的是:忽略掉
此时再想通过平方和分解这条路走下去实在是太困难了,让我们换一个思路。
线性模型登场,利用模型比较计算平方和
关于线性模型,可以先参考用回归来理解方差分析(二):两因素方差分析这篇文章
两因素方差分析的线性模型可表示为:
具体到本文的例子,则
可以把模型2.1叫做全模型,因为其包含了所有因素的影响
如果对模型2.1进行回归分析,可以计算出残差平方和:
其中
现在去掉全模型中的
此时的模型2.2只包含了
此时的
此时,便可以按照常规的方差分析,计算自由度,计算方差,计算
让我们换一个角度理解。一个模型的残差越大,说明这个模型未解释的变异越多,此时
同理,将
计算模型2.3的残差平方和
那么
将交互作用从全模型中去掉:
模型2.4的残差平方和:
交互作用平方和为:
好了,计算的思路有了,上面的公式都很简单,关键是计算预测值。不过我当然不会蠢到用笔算,接下来就是动键盘开算了。
数据实例计算
还是利用本章一开始的例子,引入虚拟变量进行回归分析。(关于两因素设计的虚拟变量可以参考用回归来理解方差分析(二):两因素方差分析这篇文章)
接下来是代码:
from statsmodels.formula.api import ols #拟合线性模型的包
from statsmodels.stats.anova import anova_lm#进行方差分析的包
import pandas as pd
import numpy as np
data={
'XA1': [1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,-1,-1,-1,-1,-1,-1,-1],
'XA2': [0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1],
'XB1': [1,1,1,-1,-1,-1,-1,-1,1,1,1,1,-1,-1,-1,-1,-1,1,1,1,-1,-1,-1,-1],
'XAB11':[1,1,1,-1,-1,-1,-1,-1, 0,0,0,0, 0,0,0,0,0,-1,-1,-1,1,1,1,1],
'XAB21':[0,0,0, 0,0,0,0,0,1,1,1,1, -1,-1,-1,-1,-1,-1,-1,-1,1,1,1,1],
'Y':[6,3,3,6,3,5,5,2,7,6,7,5, 8,7,8,9,8, 9,7,5,10,12,11,7],
'A':[1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3],
'B':[1,1,1,2,2,2,2,2,1,1,1,1,2,2,2,2,2,1,1,1,2,2,2,2]
}#其中前5行是虚拟变量,Y是观测值,A,B是分类变量
df=pd.DataFrame(data)
model_full=ols('Y~XA1+XA2+XB1+XAB11+XAB21',data=df).fit()#全模型回归
model_A=ols('Y~XB1+XAB11+XAB21',data=df).fit()#去掉A因素主效应
model_B=ols('Y~XA1+XA2+XAB11+XAB21',data=df).fit()#去掉B因素主效应
model_R=ols('Y~XA1+XA2+XB1',data=df).fit()#去掉交互作用
model_anova=ols('Y~C(A,Sum)*C(B,Sum)',data=df).fit()#用分类变量进行方差分析
anova_Result=anova_lm(model_anova,typ=3)
SSE=model_full.mse_resid*model_full.df_resid#全模型残差
SSEA=model_A.mse_resid*model_A.df_resid#去A模型残差
SSEB=model_B.mse_resid*model_B.df_resid#去B模型残差
SSER=model_R.mse_resid*model_R.df_resid#去交互模型残差
print(SSEA-SSE,SSEB-SSE,SSER-SSE)
#依次打印A主效应平方和,B主效应平方和,交互作用平方和
74.03142710822807 15.639893617021286 7.082980539433265
print(anova_Result)#打印方差分析结果
sum_sq df F PR(>F)
Intercept 993.384574 1.0 410.583751 7.687336e-14
C(A, Sum) 74.031427 2.0 15.299262 1.311731e-04
C(B, Sum) 15.639894 1.0 6.464250 2.041777e-02
C(A, Sum):C(B, Sum) 7.082981 2.0 1.463762 2.576274e-01
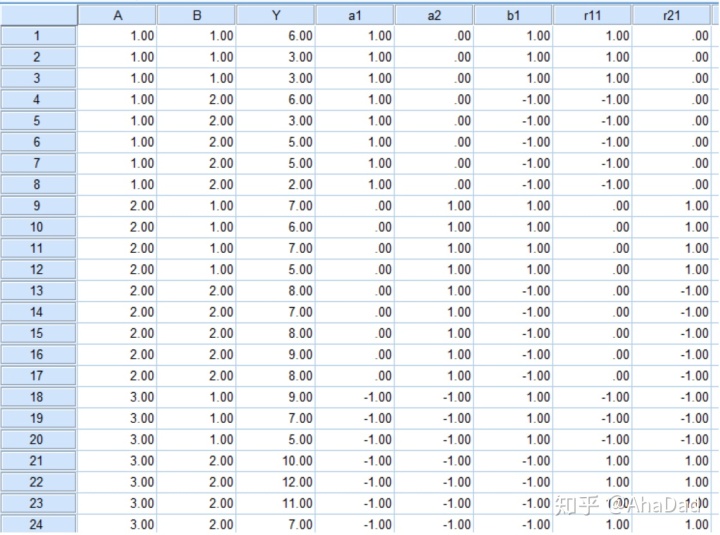
Residual 43.550000 18.0 NaN NaN可以看到,方差分析计算的结果与回归计算的结果相同。对代码不太熟悉的小伙伴也可以自己动手用SPSS的回归(regression)来做,结果是一样的。贴一张SPSS的数据图:
3 Ⅲ型平方和与Ⅰ型平方和
Ⅲ型平方和
啰嗦了这么半天,终于说到主题了!
实际上,刚才已经解释了什么叫做Ⅲ型平方和:在多因素不等组设计中,各效应的Ⅲ型平方和等于缺少该效应模型的残差减去全模型的残差。
细心的小伙伴肯定发现了,刚才计算的主效应平方和与交互作用平方和加起来不等于组间平方和(保留两位小数):
这是由于数据的不等组,导致了各效应不正交,从而导致组间平方和不能完全分解。
从这里也可以看到,如果我们非要使用常规的平方和分解方法,把不等组设计的组间平方和完全分解,那么计算出来的主效应平方和实际上混杂了其他效应的影响。
Ⅰ型平方和
Ⅰ型平方和的提出,实际上就是为了针对主效应和交互作用不能完全瓜分组间平方和的情况。
Ⅰ型平方和也叫做“顺序”(sequential,翻译可能不是很好,呵呵)平方和。顾名思义,计算Ⅰ型平方和时需要考虑因素的“入场顺序”。注意:只是考虑主效应的入场顺序
例如,在上例中,一开始先假定没有任何因素的影响,将模型写为:
之后,
此时模型3.1与模型3.2的残差之差,就是
接下来,
此时3.2与3.3的残差之差,就是
最后,交互作用入场,也就是全模型了
此时模型3.3与3.4的残差之差,就是交互作用效应。
当然,此时我们可以将
Ⅰ型平方和实例计算
接下来通过之前的例子计算一下Ⅰ型平方和。
代码如下(同样,对代码不熟悉的小伙伴也可以用SPSS验算,虽然稍微麻烦一点)
- 首先定义模型 注意到此时把所有可能的模型都写出来了
from statsmodels.formula.api import ols #拟合线性模型的包
from statsmodels.stats.anova import anova_lm#进行方差分析的包
import pandas as pd
import numpy as np
data={
'XA1': [1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,-1,-1,-1,-1,-1,-1,-1],
'XA2': [0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1],
'XB1': [1,1,1,-1,-1,-1,-1,-1,1,1,1,1,-1,-1,-1,-1,-1,1,1,1,-1,-1,-1,-1],
'XAB11':[1,1,1,-1,-1,-1,-1,-1, 0,0,0,0, 0,0,0,0,0,-1,-1,-1,1,1,1,1],
'XAB21':[0,0,0, 0,0,0,0,0,1,1,1,1, -1,-1,-1,-1,-1,-1,-1,-1,1,1,1,1],
'Y':[6,3,3,6,3,5,5,2,7,6,7,5,8,7,8,9,8,9,7,5,10,12,11,7],
'A':[1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3],
'B':[1,1,1,2,2,2,2,2,1,1,1,1,2,2,2,2,2,1,1,1,2,2,2,2]
}#其中前5行是虚拟变量,Y是观测值,A,B是分类变量
df=pd.DataFrame(data)
model_none=ols('Y~1',data=df).fit()#零模型,即没有任何效应
#-----------------首先进场的三种情况-----------------
model_A=ols('Y~XA1+XA2',data=df).fit()#只有A因素,即A先入场
model_B=ols('Y~XB1',data=df).fit()#只有B因素,即B先入场
#------------------其次进场的情况----------------------
model_AB=ols('Y~XA1+XA2+XB1',data=df).fit()#A,B主效应同时存在
#------------------最后进场,全模型-------------------------
model_full=ols('Y~XA1+XA2+XB1+XAB11+XAB21',data=df).fit()#全模型
#------------------以下为方差分析结果---------------------
model_anova_ABR=ols('Y~C(A,Sum)+C(B,Sum)+C(A,Sum):C(B,Sum)',data=df).fit()
#用分类变量进行方差分析,进场顺序为ABR
anova_Result_ABR=anova_lm(model_anova_ABR,typ=1)#此时选择Ⅰ型平方和
model_anova_BAR=ols('Y~C(B,Sum)+C(A,Sum)+C(A,Sum):C(B,Sum)',data=df).fit()
#用分类变量进行方差分析,进场顺序为BAR
anova_Result_BAR=anova_lm(model_anova_BAR,typ=1)#此时选择Ⅰ型平方和
- 先来计算进场顺序依次为A主效应,B主效应,AB交互作用的Ⅰ型平方和。看看结果如何
#以下计算进场顺序A-B-R的Ⅰ型平方和
SSEN=model_none.mse_resid*model_none.df_resid#零模型残差
SSEA=model_A.mse_resid*model_A.df_resid#A先进场模型残差
SSEAB=model_AB.mse_resid*model_AB.df_resid#AB模型残差,此时B第二个进场
SSEF=model_full.mse_resid*model_full.df_resid#全模型残差
SSA=SSEN-SSEA#A主效应
SSB=SSEA-SSEAB#B主效应
SSR=SSEAB-SSEF#交互作用效应
print('用回归计算的Ⅰ型平方和输出结果为:'
'nSSA:%.3f,nSSB:%.3f,nSSR:%.3f'%(SSA,SSB,SSR))
#依次打印A主效应平方和,B主效应平方和,交互作用平方和
用回归计算的Ⅰ型平方和输出结果为:
SSA:83.766,
SSB:15.226,
SSR:7.083
print('Ⅰ型平方和方差分析输出结果为:n',anova_Result_ABR)#打印方差分析结果
Ⅰ型平方和方差分析输出结果为:
df sum_sq mean_sq F PR(>F)
C(A, Sum) 2.0 83.765873 41.882937 17.310973 0.000064
C(B, Sum) 1.0 15.226146 15.226146 6.293241 0.021911
C(A, Sum):C(B, Sum) 2.0 7.082981 3.541490 1.463762 0.257627
Residual 18.0 43.550000 2.419444 NaN NaN
print('各主效应与交互作用平方和之和为:%.3f'%(np.sum(anova_Result_ABR.sum_sq[0:3])))
各主效应与交互作用平方和之和为:106.075可见,此时用回归模型计算的结果与用方差分析计算的结果相同,注意此时的方差分析使用的是Ⅰ型平方和。而且Ⅰ型平方和的主效应与交互作用之和刚好等于组间平方和106.075
- 接下来再计算进场顺序为B主效应,A主效应,AB交互作用的Ⅰ型平方和看看
#以下计算进场顺序B-A-R的Ⅰ型平方和
SSEN=model_none.mse_resid*model_none.df_resid#零模型残差
SSEB=model_B.mse_resid*model_B.df_resid#B先进场模型残差
SSEAB=model_AB.mse_resid*model_AB.df_resid#AB模型残差,此时A第二个进场
SSEF=model_full.mse_resid*model_full.df_resid#全模型残差
SSA=SSEN-SSEB#A主效应
SSB=SSEB-SSEAB#B主效应
SSR=SSEAB-SSEF#交互作用效应
print('用回归计算的Ⅰ型平方和输出结果为:'
'nSSA:%.3f,nSSB:%.3f,nSSR:%.3f'%(SSA,SSB,SSR))
#依次打印A主效应平方和,B主效应平方和,交互作用平方和
用回归计算的Ⅰ型平方和输出结果为:
SSA:11.668,
SSB:87.324,
SSR:7.083
print('Ⅰ型平方和方差分析输出结果为:n',anova_Result_BAR)#打印方差分析结果
Ⅰ型平方和方差分析输出结果为:
df sum_sq mean_sq F PR(>F)
C(B, Sum) 1.0 11.667857 11.667857 4.822536 0.041435
C(A, Sum) 2.0 87.324162 43.662081 18.046325 0.000050
C(A, Sum):C(B, Sum) 2.0 7.082981 3.541490 1.463762 0.257627
Residual 18.0 43.550000 2.419444 NaN NaN
print('各主效应与交互作用平方和之和为:%.3f'%(np.sum(anova_Result_BAR.sum_sq[0:3])))
各主效应与交互作用平方和之和为:106.075可见,此时各效应的总和依然等于组间平方和
这是必须的。因为二者的计算公式是一样的。
实际上,细心的小伙伴也已经发现了,先进场的因素主效应平方和,其实跟常规的平方和分解计算结果相同。例如,再A-B-R顺序中,A主效应的平方和
可见,虽然Ⅰ型平方和保证了组间平方和完全的分解,但是其计算结果“不纯净”,所以在分析不等组设计时,建议使用Ⅲ型平方和。
当然,如果是分析等组设计的话,那么Ⅰ型平方和与Ⅲ型平方和的结果一模一样,没有区别。因为此时各效应是完全正交的,没有相互干扰
4 小结
- 通过回归模型比较,可以更好理解Ⅰ型平方和与Ⅲ型平方和
- Ⅰ型平方和的模型是“从无到有”。逐步增加的。Ⅲ型平方和都是用全模型与缺少某效应的模型比较。
- 针对不等组设计,Ⅰ型平方和根据主效应进场顺序的不同,计算结果也不同。Ⅲ型平方和与进场顺序无关
- Ⅰ型平方和虽然能完全分解组间平方和,但是计算结果“不纯净”。Ⅲ型平方和虽然没有完全分解组间平方和,但其排除了其他效应的干扰,结果更“纯净”
- 交互作用的结果在两种平方和中的计算结果是相同的。
- 等组设计中,Ⅰ型平方和与Ⅲ型平方和等价
- 单因素方差分析不涉及各种平方和
如果代码不熟悉的同学,可以用SPSS进行检验,有问题或者建议欢迎留言讨论。
另外,除了Ⅰ型平方和与Ⅲ型平方和,还有Ⅱ型和Ⅳ型。不过后面这两兄弟不常用,就不详细介绍了。