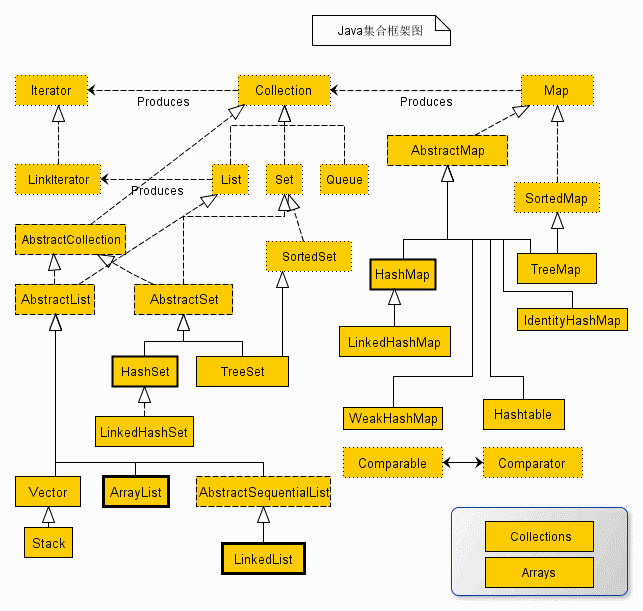
目录
常问:LinkedList和ArrayList的相同之处和区别?
并发包下的那些并发容器类(Concurrent Collections)和java.util包中的容器类的区别
Java中常见的数据结构
栈、队列、数组和列表
栈:操作受限的线性表:后进先出;入栈和出栈只能在栈顶进行
队列:同样是操作受限的线性表,只允许在表尾插入、表头删除
数组:一组相同数据类型元素的有序集合
链表:由若干个结点链接而成;单链表中,每个结点包含两个域:用来存储数据的数据域和用来链接下一个结点的指针域
Java中容器类的用途
Java中容器类的用途主要是用来存储元素
常问:Set和List的区别?
存放的元素:Set接口实例存放的是无序的不能重复的数据;而List接口存放有序的可以重复的元素
Set检索效率低下,插入和删除效率高,插入和删除不会引起元素位置的改变;List有随机访问效率高的实现类(ArrayList和Vector)
List允许多个重复的null,Set最多只能容纳一个null(TreeSet甚至不允许null)
Set只能用Iterator接口进行遍历,List不仅可以使用Iterator还可以使用ListIterator进行遍历
List中的元素有序,遍历元素时的顺序即插入元素时的顺序;而Set中除了HashSet无序,TreeSet和LinkedHashSet元素有序
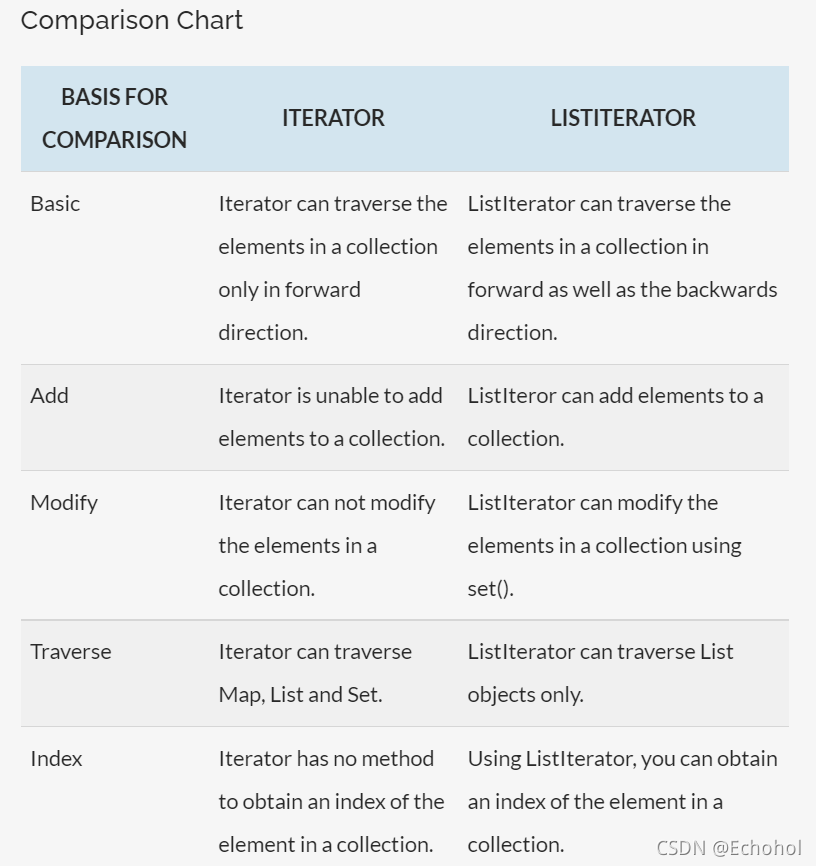
Iterator和ListIterator的区别
Iterator可以在所有集合中使用,而ListIterator只能用于List
listiterator和iterator都有hasnext和next方法可以顺序遍历元素, 但是listiterator有hasprevious和previous方法,可以逆向遍历元素
ListIterator能对集合中的元素进行增、改(使用set( )方法),还能获取特定元素的下标;而Iterator不能
(ListIterator和Iterator的对比表格)

(ListIterator的方法)

(Iterator的方法)
关于fail-fast和fail-safe类型迭代器的区别
fail-fast直接在容器上进行,在遍历过程中,一旦发现容器中的数据被修改,除了使用iterator自带的remove方法(except through the iterator's own
removemethod),就会立刻抛出 ConcurrentModificationException异常从而导致遍历失败。常见的使用fail-fast方式的容器有 HashMap和ArrayList等。fail-safe这种遍历基于容器的一个克隆。因此对容器中的内容修改不影响遍历。常见的使用fail-safe 方式遍历的容器有ConcurrentHashMap和CopyOnWriteArrayList。
关于HashSet:
HashSet实现了Set接口,但是其实际上(底层)是由HashMap实现的
元素无序;遍历时也是,而且遍历时的时间开销不仅需要考虑size还要顾虑到capacity;(在遍历方面完全不如LinkedHashSet)
允许空值 (HashMap也允许null values和null key,但是HashMap只能有一个null的键(key);但是继承了Map接口的其他类比如说HashTable, ConcurrentHashMap和TreeMap都不允许键(key)为null!!!)
线程不安全

关于TreeSet
继承了SortedSet接口,其中的元素有序,依靠compareTo( )或者compare( )方法比较元素大小进行排序
依靠TreeMap实现,底层数据结构为红黑树(一种自平衡的排序二叉树)
拥有的迭代器iterator,不仅元素会进行有序遍历,而且每次遍历结果都一致;(相比之下,ArrayList的元素遍历无序,HashMap甚至每次遍历的结果都不一样)
与其他常用的容器类一样(ArrayList, HashMap等)遍历的类型都是fail-fast的;
查询、插入和删除操作的时间复杂度都为log(n)(由红黑树结构决定)
不允许null

关于LinkedHashSet
继承自 HashSet,实现了Set接口;是哈希表和双向链表的组合,底层依靠LinkedHashMap实现;
允许null值
与HashMap一样:遍历数据的顺序即数据被插入时的顺序
经常用于copy一个Set,因为原来Set中的元素的顺序不会被改变
与HashSet相比性能稍微差点,因为它的链表结构带来的额外开销
但是遍历使用LinkedHashSet要好点,因为HashSet的遍历不仅要考虑元素个数(size)还要考虑容量(capacity)而LinkedHashSet只需考虑size无需考虑capacity
线程不安全

关于HashMap:
基于哈希表的Map实现;底层是数组+链表(JDK1.8以前)或者数组 + 链表/红黑树(JDK1.8以后)
在HashMap存储对象的时候,根据其key值用哈希算法计算其散列值然后将其放在Node[ ] table数组上,成为链表上的一个结点(底层实现为Node,Node即实现了Map.Entry接口的一个内部类,实际上可视为一个键值对);如果发生了哈希冲突,就会放在与其相同的hash值得链表之后;在JDK8以前,一直用链表处理hash冲突;JDK8以后,链表太长了会影响查找和增加等操作得效率,故长度超过了8之后,会变成一个红黑树;
Node中的hash, key, value ,next 分别表示哈希值,key值, value值和 指向的下一个结点
还需要明确一点的是,HashMap是存在扩容(resize)机制的;但是因为其table的数组结构是无法改变长度的,所以只能采取“用一个新的容量大的数组取替代原来的容量小的数组”的策略
(更多详情见Java 8系列之重新认识HashMap)
继承了Map接口,Map不允许键(key)重复,允许设置key和value为null(只能有一个null键);
元素无序
默认(load factor)加载因素为0.75
线程不安全

关于TreeMap
底层利用红黑树实现的Map结构(红黑树是一种自平衡的排序二叉树)
SortedMap的唯一实现类,根据建的自然顺序或者创建时提供的Comparator 进行排序(取决于comparator() 方法的返回值 )
增删查、get操作的时间复杂度都为O(log(n)),性能上低于HashMap
HashMap无法进行键值对的有效输出,TreeMap能根据键的值大小进行有序的输出
线程不安全
fail-fast
唯一带有subMap()方法的Map,可以返回一个子树
不允许key为null,但是允许值为null

关于LinkedHashMap
遍历时元素的顺序即被插入时的顺序
经常被用于复制一个Map,因为原来Map中的元素顺序不会被改变
允许空值null
性能比HashMap差点(考虑到其要维持链表结构的额外开销)
但是遍历使用LinkedHashMap要好点,因为HashMap的遍历不仅要考虑元素个数(size)还要考虑容量(capacity)而LinkedHashMap只需考虑size无需考虑capacity
fail-fast

关于ArrayList
实现了List接口,能存放重复元素,并允许null值
可将其视为长度可变的数组:底层用数组实现,随机访问快,增删慢;
拥有自己的容量(capacity),可以扩容:每次扩容成为原来的1.5倍;默认容量(default capacity)为10;且与HashMap一样拥有默认的load factor,为0.75

线程不安全(与Vector几乎一样,只是Vector是线程安全的,所有可将其视为线程不安全版的Vector)
迭代器不仅能使用iterator还能使用ListIterator遍历其中的元素;遍历类型为fail-fast
遍历时的元素顺序即插入时的顺序

关于LinkedList
底层实现结构为双向链表,增删快,随机访问慢
实现了List接口,能允许null,以及重复元素的存在
实现了Deque接口,可将其视为列表(双向列表);
线程不安全
fail-fast

常问:LinkedList和ArrayList的相同之处和区别?
同:
都是属于实现了List接口的集合类
都是线程不安全的List;(另外有一个线程安全的List是Vector)
iterator皆为fail-fast类型
异:
实现方式:
ArrayList底层使用数组实现的,而LinkedList使用双向链表实现;
使用情形:
简单记忆:插入或者删除多的情形使用LinkedList,其他情况使用ArrayList(比如说设置和查询获取某个元素)
内存占用:LinkedList由于其一个节点存储了两个引用,故更占内存
实现的接口:LinkedList还实现了一个Deque接口,故其可当成队列使用;
keySet还是entrySet?
遍历Map类集合的键值对(KV)时使用entrySet而不是KeySet

(图截自阿里开发手册)
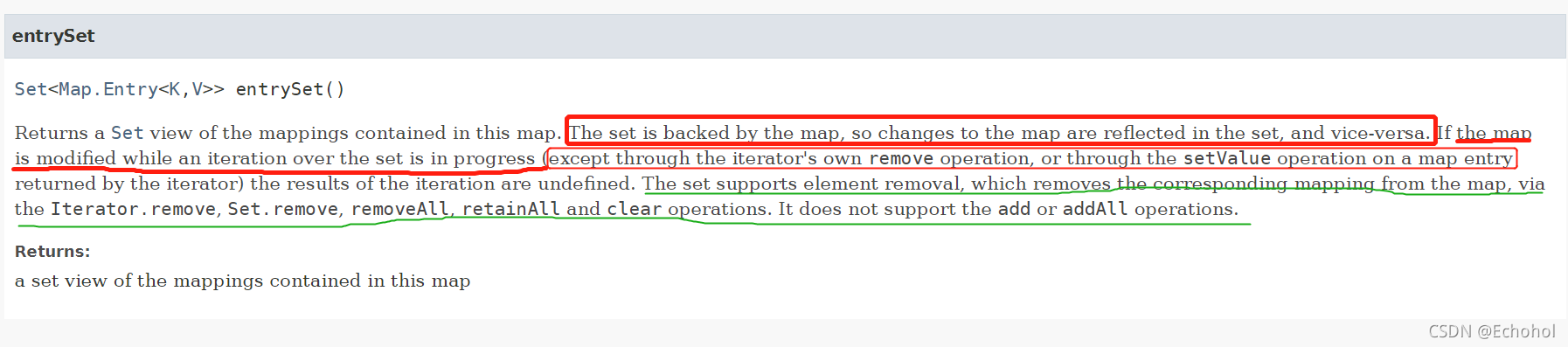
关于entrySet
entrySet是基于Map实现的,对Map的修改会反映到entrySet上,反过来对entrySet的修改也会反映到Map上
当Map在遍历entrySet的时候被修改了(除了iterator的remove方法),遍历的结果就不明确了
支持remove方法,无论是Iterator.remove(),Set.remove(),removeAll,retainAll 和 clear等操作;
不支持add以及addAll等操作
并发包下的那些并发容器类(Concurrent Collections)和java.util包中的容器类的区别

大多数的并发包容器类的遍历(包括大多数的队列)和寻常的util包中的不一样,它们使用Iterators和SplitIterators中的方法,提供了弱一致型(weakly consistent)的而不是fail-fast型的遍历
它们可以和其他操作并发进行
不会抛出ConcurrentModificationException 异常