es
是一种搜索引擎软件
搜索就是查询
和关系型数据库对比
如goods 商品表
id title sell_point
1001 华为p30手机黑色 4.5英寸
select * from goods where title like "%华为%"
1、假如 我们给 title 加上索引 但是like 左边加上 通配符后 索引会失效。意味着 全表扫描 如果有一亿个商品 那么效率很低。
模糊查询可能造成全表扫描
2、select * from goods where title like "%华为手机%" 这样是查询不出来的,必须要 华为和手机分开查。
但是es就能实现。
关系型数据库功能弱。
那么es是如何解决刚才的 两个问题的 :性能低 功能弱。
1、倒排索引:就是将文本内容进行分词形成词条 然后记录词条和数据的唯一标识的对应关系。
首先将一段文本按照一定的规则拆分成不同的词条term。
如:床前明月光 拆分为 :床前 明月 光
反向倒排索引
key (词条term)=>value(存储内容)
床=》床前明月光
前=》床前明月光
床前=》床前明月光
明=》床前明月光
月=》床前明月光
明月=》床前明月光
光=》床前明月光
月光=》床前明月光
上面的value(存储内容)数据量很大其实只需要放 id就行了
es 存储数据和搜索原理:
索引库:index 它其实就相当于关系型数据库中的 数据库。
数据叫做文档:document 他就相当于我们关系型数据库中的 表里面的一行一行的数据。
在es中文档的数据结构其实就是json的数据格式
如:{
“id”:"1",
"title":"华为p30手机",
“price”:3980.00
}
{
“id”:"2",
"title":"三星GNX手机",
“price”:3980.00
}
{
“id”:"3",
"title":"红米4g手机",
“price”:3980.00
}
如果 我们需要对 title 进行分词:具体分词规则是什么 是由es来完成的。
形成的倒排索引如下:
key value
华为 1
p30 1
手机 1,2,3
手 1,2,3
机 1,2,3
三星 2
GNX 2
红米 3
4g 3
index 索引库存储了 文档和 文档分词后的 倒排索引库。
es 搜索:
它是通过 倒排索引 来搜索
如:我们要搜索“手机"这个词
第一步 es会拿着这个 “手机这个词” 去倒排索引中去匹配。
匹配到了 就会根据 对应的id去把文档找到 返回给用户
假设:词条数据量很大 恰好要查询的词条再最后面 怎样处理?查询数据岂不是依然很慢。
es帮我们解决了 那就是 对词条进行排序 形成一个树形的数据结构(请自行补 数据结构算法知识),这样提升词条的 速度。
1、这样 关系型数据中 的查询性能低的问题 es给我们解决了。
2、假如要查询 "华为手机" 这样一个词条呢 这样没有词条匹配 岂不是查询不出来吗?
es的解决方案是 先分词 再查询:如将分为:"华为","手机" :es自动去分的不用去干预
通过华为 找到文档1 ,通过手机找到 1,2,3.
然后对结果集求交集 不就查出来了吗。
ElasticSerch 的概念
ElasticSerch 是一个基于Lucenne (撸神)的搜索服务器
Lucenne 是什么:他是一套基于搜索的API,如果我们要基于Lucenne来写搜索也是可以的 但是实现起来很麻烦,需要对搜索的细节都要了解 如分词要自己写。
Lucenne :实现了它的两个比较好的应用 就是 ElasticSerch 和Solr(出来的时间比es早),但是ElasticSerch 性能比他高。
Elasticserch是一个分布式,高扩展 实时的搜索与数据分析引擎,基于RESTful web接口的,我们可以通过http请求就可以操作它。
ElasticSerch是用Java语言开发的 ,并且作为Apache许可条款下的开放源代码发布,是一种流行的企业级搜索引擎。
ElasticSerch:应用场景:
1、海量数据的搜索
2、日志数据分析
3、数据实时分析
mysql 和ElasticSerch区别
1、事务:mysql是有事务的 而ElasticSerch是没有事务的,所以删除数据是无法恢复 的。
2、数据一致性:mysql有物理外键这个特性,而ElasticSerch 没有,如果你的数据强一致性要求比较高还是建议慎用。
3、分工不同:mysql是存数据,ElasticSerch 是分担了mysql的查询数据功能。
es核心概念:
1、索引库:index 数据库
2、映射:mappings。 它就相当于mysql中的表结构 它定义了每个字段的类型 以及所使用的分词器。
{
"mappings" {
"propertises"{
"id":{"type":"integer"}
"title":{"type":"text"}
"price":{"type":"double"}
}
}
}
3、数据叫做文档:document 他就相当于我们关系型数据库中的 表里面的一行一行的数据。它也是json格式。他是es中最小的数据存储单元。
如:{
“id”:"1",
"title":"华为p30手机",
“price”:3980.00
}
{
“id”:"2",
"title":"三星GNX手机",
“price”:3980.00
}
{
“id”:"3",
"title":"红米4g手机",
“price”:3980.00
}
4、倒排索引:es自己去处理。
一个倒排索引由文档中所有不重复的词列表构成,对于其中的每一个词,对应包含他的文档id列表。
5、type 就像一类表:Elasticsearch 官网提出的近期版本对 type 概念的演变情况如下:
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index 下只能存在一个 type;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type
ElasticSerch 操作:
1、http:脚本操作
RESTful:定义接口的一种规范:
要求:1、基于http协议
2、可以使用xml或者json格式来定义:参数和返回值。现在一般使用json
3、每一个uri代表一种资源
4、客户端使用GET,POST,PUT,DELETE这4种表示操作方式的的动词对服务资源进行操作:
如:/uesr/1
GET, /uesr/1 表示查询id为1的用户
POST,/uesr/ 表示新增用户
PUT,/uesr/1 表示修改id为1的用户
DELETE:/uesr/1 表示删除id为1的用户
索引操作:GET(获取), POST(更新), PUT(创建), HEAD, DELETE(删除)
添加
查询
修改
删除
打开
关闭
1、
get http://localhost:9200/
{
"name": "pDKafZ_",
"cluster_name": "elasticsearch",
"cluster_uuid": "yn-afXGiTVy2Wq6iWpzbiA",
"version": {
"number": "6.2.2",
"build_hash": "10b1edd",
"build_date": "2018-02-16T19:01:30.685723Z",
"build_snapshot": false,
"lucene_version": "7.2.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
2、添加索引 index01
put http://localhost:9200/index01
返回:{
"acknowledged": true,
"shards_acknowledged": true,
"index": "index01"
}
3、查询索引
get http://localhost:9200/index01
{
"index01": { //索引名称
"aliases": {}, //别名
"mappings": {}, //mappings 也就是相当于表结构
"settings": {//配置信息
"index": {
"creation_date": "1636205484555",//创建时间
"number_of_shards": "5",//分片数量
"number_of_replicas": "1",//备份数量
"uuid": "4Ayvc1xaT_WYxQJxPjRKhA",//uuid随机生成
"version": {//版本
"created": "6020299"
},
"provided_name": "index01"//名字
}
}
}
}
也可以同时查询多个 以逗号分隔
http://localhost:9200/index01,index02
查询所有_all 下划线开头的指令都是es内置的一些指令 可以直接使用
http://localhost:9200/_all
4、删除索引
delete http://localhost:9200/index02
{
"acknowledged": true
}
5、关掉索引 关闭掉了可以查 不可以往里面插入数据
post http://localhost:9200/index01/_close
{
"acknowledged": true
}
6、打开索引
post http://localhost:9200/index01/_open
{
"acknowledged": true,
"shards_acknowledged": true
}
映射操作:添加映射 ,查询映射,添加字段。 可以使用kibana工具进行操作
映射不支持 删除和修改。
mappings 相当于表结构
{
"mappings" {
"propertises"{//属性
"id":{//id 字段
"type":"integer"//id 的数据类型
}
"title":{"type":"text"}//属性
"price":{"type":"double"}//属性
}
}
}
数据类型:
1、简单数据类型:
字符串:text:会分词 不支持聚合
keyword:不会分词 将全部内容作为一个词条 支持聚合
聚合:相当于关系型数据库里面的聚合函数 如求和等
分词:将文本分为不同的关键词 如:”华为手机“ 分为 华为 手机。
不会分词就是将 华为手机 作为一个词条来存储。
数值:
long
integer
short
等...自己去查询
布尔:boolean
二进制:binary
范围型:最大值 最小值
integer_range
...自己查
日期:
date
2、复杂数据类型:
数组:[] es里面不用显示的定义他是数据类型,多个值就用中括号括起来就可以
对象:{}
添加映射 ,
查询映射,
添加字段

文档的操作
 添加文档不指定id他会默认添加
添加文档不指定id他会默认添加
es默认类型_doc




这里的_id是用于倒排索引的id
es分词器


默认分词器对英文很友好

我们要安装中文分词器 ik分词器


粗粒度分词器
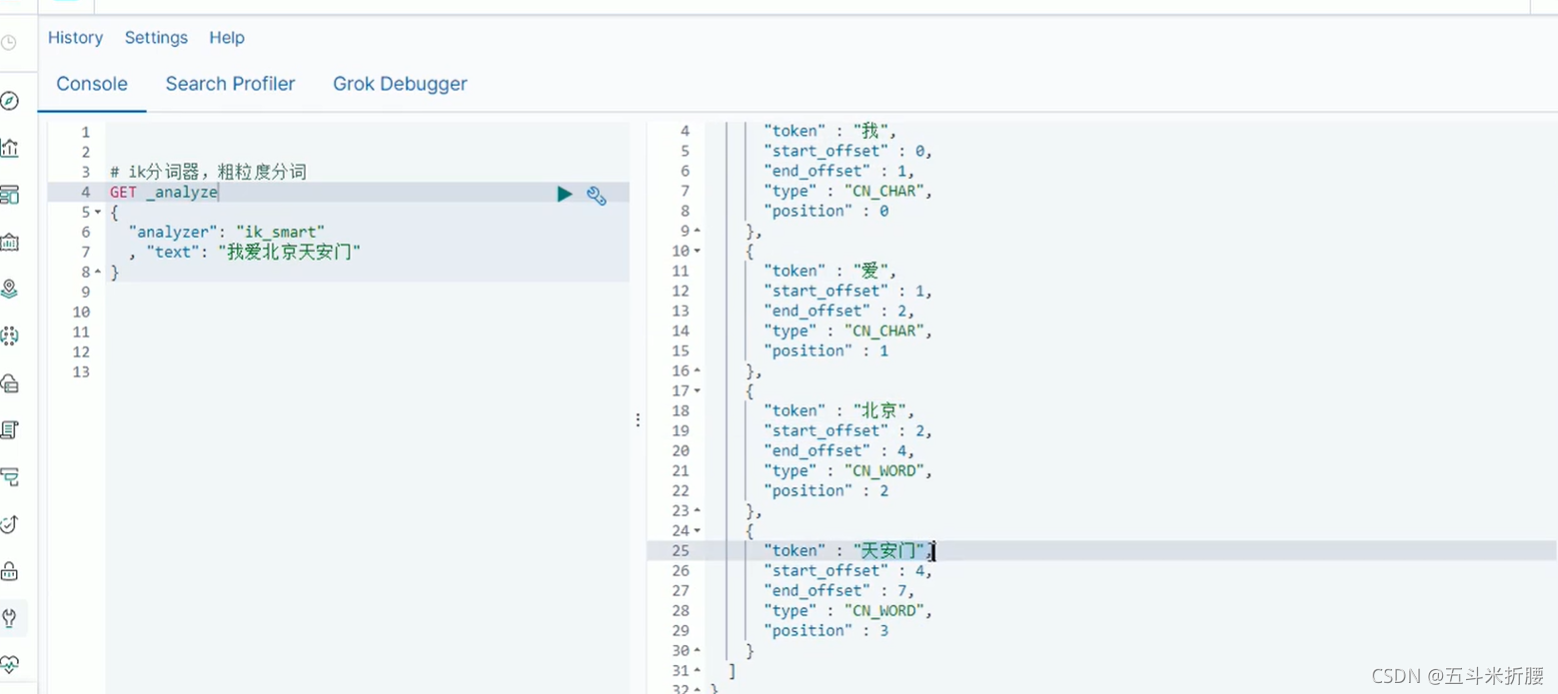
细粒度

文档查询:


创建索引mapping的时候如果没有指定分词器他会 使用es的默认分词器
所以我们在创建的时候就要 指定分词器

