一、例子1

首先用make_regression建一个有3个自变量的数据集,但是其秩为2,因此3个自变量中有两个自变量存在相关性。
from sklearn.datasets import make_regression
import numpy as np
reg_data, reg_target = make_regression(n_samples=100, n_features=2, effective_rank=1, noise=10)
#n_features:特征数(自变量个数);n_samples=100样本数;effective_rank=秩为1
from sklearn.linear_model import RidgeCV #岭回归交叉验证
rcv = RidgeCV(alphas=np.array([.1, .2, .3, .4]))#参考《优化岭回归参数(Optimizing the ridge regression parameter)》
rcv.fit(reg_data, reg_target)#训练
rcv.alpha_#训练完后,得到最好的alpha
下面得出最佳alpha
进一步我们想要0.1得到附近的alpha
rcv2 = RidgeCV(alphas=np.array([.08, .09, .1, .11, .12]))
rcv2.fit(reg_data, reg_target)
rcv2.alpha_
我们强行是RidgeCV对象来储存交叉验证值,也即store_cv_values=True,这对我们后面的可视化很有用。
alphas_to_test = np.linspace(0.01, 1)#现在我们有50个test用的点
rcv3 = RidgeCV(alphas=alphas_to_test, store_cv_values=True)
rcv3.fit(reg_data, reg_target)
rcv3.cv_values_.shape#查看形状

下面来找似的alpha最小的参数
smallest_idx = rcv3.cv_values_.mean(axis=0).argmin()
alphas_to_test[smallest_idx]
rcv3.alpha_
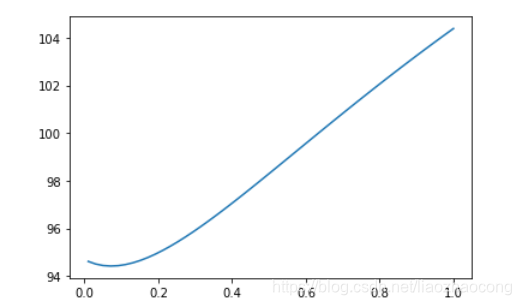
画出最小参数alphas_to_test[smallest_idx]
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(alphas_to_test, rcv3.cv_values_.mean(axis=0))
二、例子2

from sklearn.metrics import mean_absolute_error
from sklearn.metrics import make_scorer
MAD_scorer = make_scorer(mean_absolute_error, greater_is_better=False)
rcv4 = RidgeCV(alphas=alphas_to_test, store_cv_values=True, scoring=MAD_scorer)#将MAD_scorer作为参数传入
rcv4.fit(reg_data, reg_target)
smallest_idx = rcv4.cv_values_.mean(axis=0).argmin()
rcv4.cv_values_.mean(axis=0)[smallest_idx]
alphas_to_test[smallest_idx]
版权声明:本文为liaozhaocong原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。