本次吃瓜教程是Datawhale组织的组队学习 。
学习资料由开源学习组织Datawhale提供。
开源贡献:李嘉骐、牛志康、刘洋、陈安东、陈玉立、刘兴、郭棉昇、乔彬、邝俊伟
笔记部分内容来源于网络检索,如有侵权联系可删
本次学习针对的对象:
具备高数、线代、概率论基础,有一定的机器学习和深度学习基础,熟悉常见概念,会使用Python。
内容说明:PyTorch理论与实践结合,由基础知识到项目实战。
学习周期:14天
教程链接:https://datawhalechina.github.io/thorough-pytorch/index.html
B站视频:BV1L44y1472Z
学习者手册:https://mp.weixin.qq.com/s/pwWg0w1DL2C1i_Hs3SZedg
第五章 PyTorch模型定义
5.1PyTorch模型定义的方式
- Module 类是 torch.nn 模块里提供的一个模型构造类 (nn.Module),是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型;
- PyTorch模型定义应包括两个主要部分:各个部分的初始化(init);数据流向定义(forward)
基于nn.Module,我们可以通过Sequential,ModuleList和ModuleDict三种方式定义PyTorch模型。
Sequential
对应模块为nn.Sequential()。
当模型的前向计算为简单串联各个层的计算时, Sequential 类可以通过更加简单的方式定义模型。它可以接收一个子模块的有序字典(OrderedDict) 或者一系列子模块作为参数来逐一添加 Module 的实例,⽽模型的前向计算就是将这些实例按添加的顺序逐⼀计算。
使用Sequential来定义模型,根据层名的不同,排列的时候有两种方式:
- 直接排列
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
Sequential(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
)
- 使用OrderedDict:
OrderedDict:是python中模块collections里面自带了的一个子类OrderedDict,实现了对字典对象中元素的排序。
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)
Sequential(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
ModuleList
ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,然后也可以类似List那样进行append和extend操作。同时,子模块或层的权重也会自动添加到网络中来。
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10)) # # 类似List的append操作
print(net[-1]) # 类似List的索引访问
print(net)
Linear(in_features=256, out_features=10, bias=True)
ModuleList(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
)
注意:nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。 ModuleList中元素的先后顺序并不代表其在网络中的真实位置顺序,需要经过forward函数指定各个层的先后顺序后才算完成了模型的定义。具体实现时用for循环即可完成:
class model(nn.Module):
def __init__(self, ...):
super().__init__()
self.modulelist =
def forward(self, x):
for layer in self.modulelist:
x = layer(x)
return x
ModuleDict
ModuleDict和ModuleList的作用类似,只是ModuleDict能够更方便地为神经网络的层添加名称。
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)
Linear(in_features=784, out_features=256, bias=True)
Linear(in_features=256, out_features=10, bias=True)
ModuleDict(
(act): ReLU()
(linear): Linear(in_features=784, out_features=256, bias=True)
(output): Linear(in_features=256, out_features=10, bias=True)
)
小结
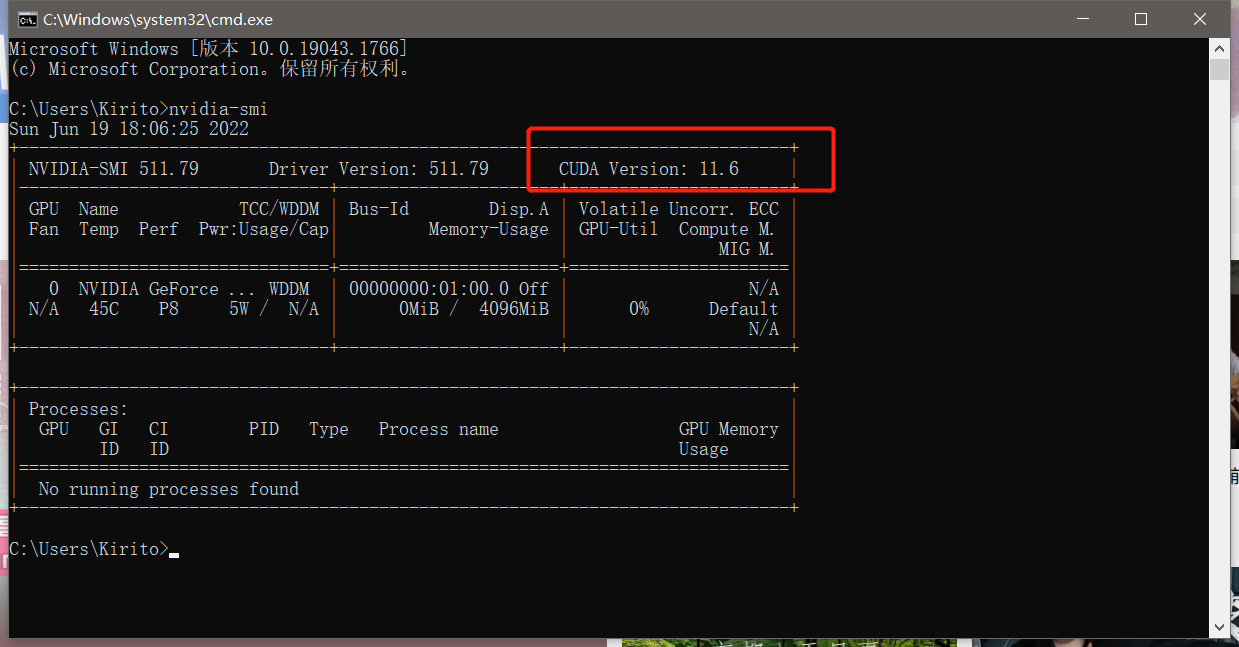
这次的task3打卡我写的内容主要是针对我第五章中学到的些基础,我觉得重要的第一节内容,在群里看了大佬发言和纠错后,我用命令行来查看了Cuda支持的最高版本,在后续对第六章最后的实战训练完成后会在更新一次task3。
nvidia-smi