1 目的和思想
fastbert 模型的目的:用小模型替代大模型
fastbert 的整体思想:自蒸馏、自适应推理
模型出自论文: FastBERT: a Self-distilling BERT with Adaptive Inference Time
2 模型原理
模型训练:
- pre-training 与 bert 预训练一样( T 和 S 分类器都 freeze)
- fine-tuning (T 分类器进行训练)
- self-distillation(S 分类器进行训练)
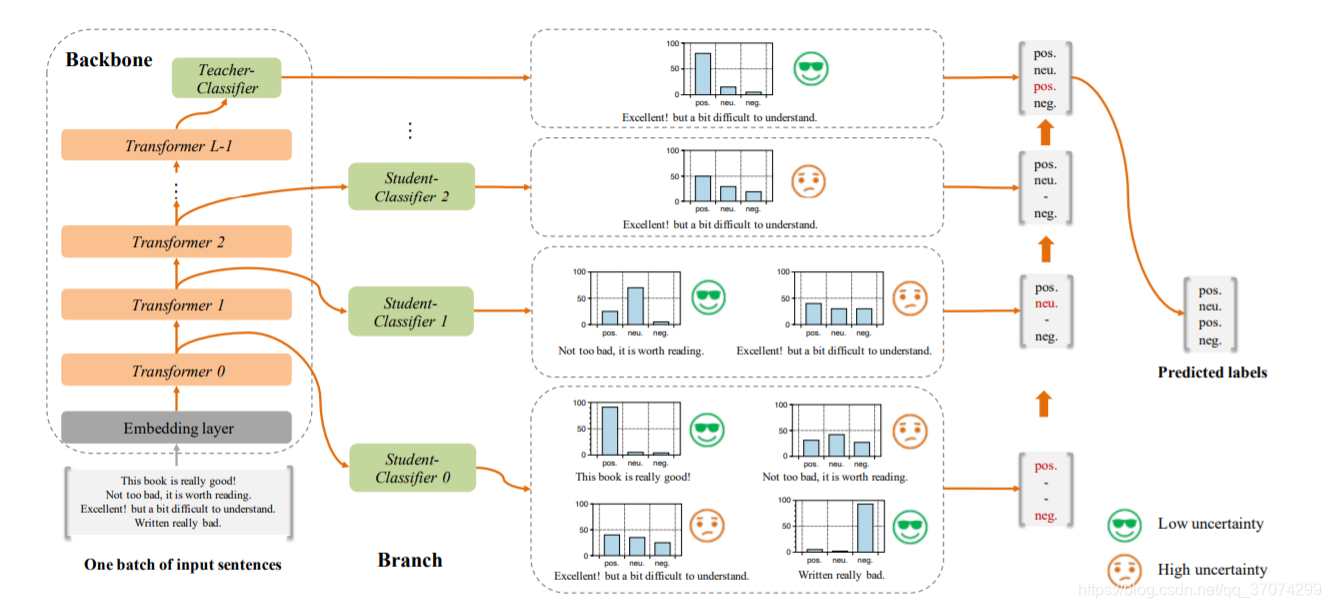
2.1 backbone
主骨架为原来的bert一样,把softmax叫作teacher classifier
2.2 branch
分支,就是在每层的transformer之后增加一个student classifier,当某层 student 分出的概率map,计算其熵,如果熵低于设置的 speed 值,就代表不确定性较低,就不在把这个数据输到下一个transformer了
loss 利用teacher和student 分类器分出的概率map,计算 KL 散度来表示
3 知识点
fastbert主要有两点创新:
- self-distillation 自蒸馏
- Adaptive Inference 自适应推理
3.1 self-distillation
其他的蒸馏是需要设计一个新的 student model,所以 T 和 S 之间的 ACC 都会降低很多来减小模型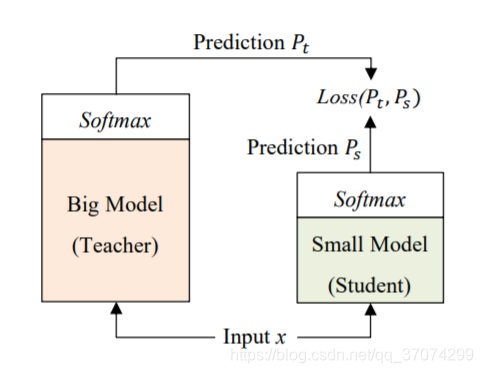
本文中提出的自蒸馏不仅减小了模型计算,还保证了 ACC ,而这个的模型设计就只是在每层transformer后加一个student classifier
3.2 Adaptive Inference
对于每一个Transformer层,我们需要采用一个评价指标来评价这一层的推理结果是否可信座作为输出,而不需要再到下一层进行推理。本文中这个指标成为不确定度Uncertainty。对于给定的输入句子,student分类器输出的不确定度采用的归一化香农熵进行计算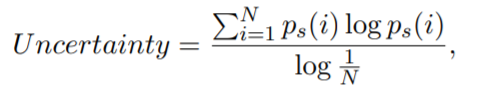
4 源码
版权声明:本文为qq_37074299原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。