Spark初探案例WordCount之Scala版本
1. 背景
- Spark作为大数据处理引擎的事实标准,基本可以涵盖大数据处理的90%以上场景。Spark SQL、Streaming、MLib、Graphx
- 作为大数据技术中最常见的案例,wordcount既简单,又可以很好跟实际企业开发中需求关联起来。因为很多企业需求其实就是换个面目的wordcount,或者组合型的wordcount需求而已
2. 本地模式运行代码
2.1 读写本地文件
- pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.doit</groupId>
<artifactId>spark_test1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 定义了一些常量 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.10</scala.version>
<spark.version>3.0.1</spark.version>
<hbase.version>2.2.5</hbase.version>
<hadoop.version>3.2.1</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- 导入scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<!-- 编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- 编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 元数据文件
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
cannot assign instance of java.lang.invoke.SerializedLambda to field org
apache spark rdd MapPartitionsRDD f of type scala Function3 in instance
of org apache spark rdd MapPartitionsRDD
- scala代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01Local {
def main(args: Array[String]): Unit = {
// conf配置文件
val wordCountSparkConf: SparkConf = new SparkConf().setAppName("WordCount")
wordCountSparkConf.setMaster("local[*]")
// sparkcontext上下文对象
val sparkContext = new SparkContext(wordCountSparkConf)
// 读取文件
val source: RDD[String] = sparkContext.textFile("E:\\wc.txt")
// 切割字符串
val wordStrings: RDD[String] = source.flatMap(_.split("\\s+"))
// 将切割好的单词字符转换为元组
val wordTuple: RDD[(String, Int)] = wordStrings.map((_, 1))
// 将元组数据进行分组聚合(分布式处理)
val reducedWords: RDD[(String, Int)] = wordTuple.reduceByKey(_ + _)
// 将聚合后数据进行排序,asc=false,就是降序
val sortedWords: RDD[(String, Int)] = reducedWords.sortBy(_._2, false)
// 将处理好的数据保存到hdfs
sortedWords.saveAsTextFile("E:\\out2")
// 关闭连接
sparkContext.stop()
}
}
- 运行结果

(of,27)
(apache,18)
(org,18)
(rdd,18)
(spark,18)
(instance,18)
(MapPartitionsRDD,18)
(scala,9)
(field,9)
(type,9)
(f,9)
(Function3,9)
(cannot,9)
(java.lang.invoke.SerializedLambda,9)
(to,9)
(in,9)
(assign,9)
2. 读写hdfs文件
- pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.doit</groupId>
<artifactId>spark_test1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 定义了一些常量 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.10</scala.version>
<spark.version>3.0.1</spark.version>
<hbase.version>2.2.5</hbase.version>
<hadoop.version>3.2.1</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- 导入scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<!-- 编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- 编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 元数据
a b c d e f g a a a a a a a a a a a a a a a a a
c c c c c c c c d d d d d d d d d d d d d d d d
d d d d d d d d a a a a a a a a a a a a
a a a a a a a a a a
d d d d d d d d d d d d d d d d d d d d
d d d d d d d d a a a a a a c c c c c
- scala代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01LocalFromHDFS {
def main(args: Array[String]): Unit = {
// hadoop的用户权限设置,否则会报读写权限错误问题
System.setProperty("HADOOP_USER_NAME", "root");
// conf配置文件
val wordCountSparkConf: SparkConf = new SparkConf().setAppName("WordCount")
// 这里设置spark进行本地模式运行而不是在集群上运行,并且executor虚拟核心数为本机电脑的虚拟核心数
wordCountSparkConf.setMaster("local[*]")
// sparkcontext上下文对象
val sparkContext = new SparkContext(wordCountSparkConf)
// 读取hdfs文件
val source: RDD[String] = sparkContext.textFile("hdfs://linux100:8020/spark/wordcount.txt")
// 切割字符串
val wordStrings: RDD[String] = source.flatMap(_.split("\\s+"))
// 将切割好的单词字符转换为元组
val wordTuple: RDD[(String, Int)] = wordStrings.map((_, 1))
// 将元组数据进行分组聚合(分布式处理)
val reducedWords: RDD[(String, Int)] = wordTuple.reduceByKey(_ + _)
// 将聚合后数据进行排序,asc=false,就是降序
val sortedWords: RDD[(String, Int)] = reducedWords.sortBy(_._2, false)
// 将处理好的数据保存到hdfs
sortedWords.saveAsTextFile("hdfs://linux100:8020/spark/out3")
}
}
- 运行结果
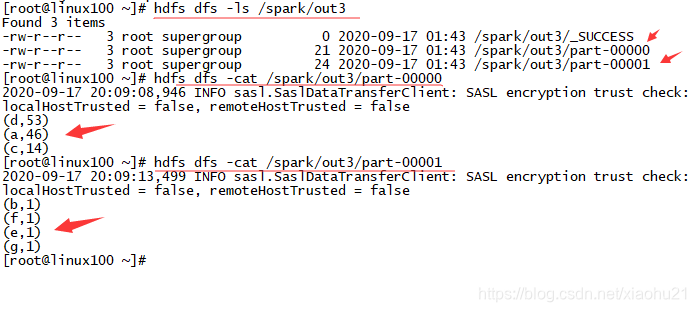
3. 集群standalone运行模式
注意,使用standlone模式运行spark集群,如果需要将代码运行在集群上,需要采取shell连接集群或者将代码通过submit程序提交到集群上,并设定参数运行jar包
- pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.doit</groupId>
<artifactId>spark_test1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 定义了一些常量 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.10</scala.version>
<spark.version>3.0.1</spark.version>
<hbase.version>2.2.5</hbase.version>
<hadoop.version>3.2.1</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- 导入scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<!-- 编译时会引入依赖,打包是不引入依赖 -->
<!-- <scope>provided</scope>-->
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<!-- 编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- 编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 元数据

a b c d e f g a a a a a a a a a a a a a a a a a
c c c c c c c c d d d d d d d d d d d d d d d d
d d d d d d d d a a a a a a a a a a a a
a a a a a a a a a a
d d d d d d d d d d d d d d d d d d d d
d d d d d d d d a a a a a a c c c c c
- scala代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01InClusterFromHDFS {
def main(args: Array[String]): Unit = {
// hadoop的用户权限设置,否则会报读写权限错误问题
System.setProperty("HADOOP_USER_NAME", "root");
// conf配置文件
val wordCountSparkConf: SparkConf = new SparkConf().setAppName("Spark01InClusterFromHDFS")
wordCountSparkConf.setMaster("spark://linux101:7077")
// sparkcontext上下文对象
val sparkContext = new SparkContext(wordCountSparkConf)
// 读取hdfs文件
val source: RDD[String] = sparkContext.textFile("hdfs://linux100:8020/spark/b.txt")
// 切割字符串
val wordStrings: RDD[String] = source.flatMap(_.split("\\s+"))
// 将切割好的单词字符转换为元组
val wordTuple: RDD[(String, Int)] = wordStrings.map((_, 1))
// 将元组数据进行分组聚合(分布式处理)
val reducedWords: RDD[(String, Int)] = wordTuple.reduceByKey(_ + _)
// 将聚合后数据进行排序,asc=false,就是降序
val sortedWords: RDD[(String, Int)] = reducedWords.sortBy(_._2, false)
// 将处理好的数据保存到hdfs
sortedWords.saveAsTextFile("hdfs://linux100:8020/spark/out4")
}
}
- 打包
- maven打包

- target产出

这里使用带依赖的jar包
- 将jar包上传到集群服务器中主节点所在服务器(不带original字样的包就是包含所有依赖的jar包,体积更大一些)
这里可以使用linux上安装的rz程序(需要自定义安装,使用yum install 安装即可)
6. 启动spark submit程序来提交任务
- spark-submit是一个可执行文件,位置在spark安装目录的bin目录下,具体如下截图
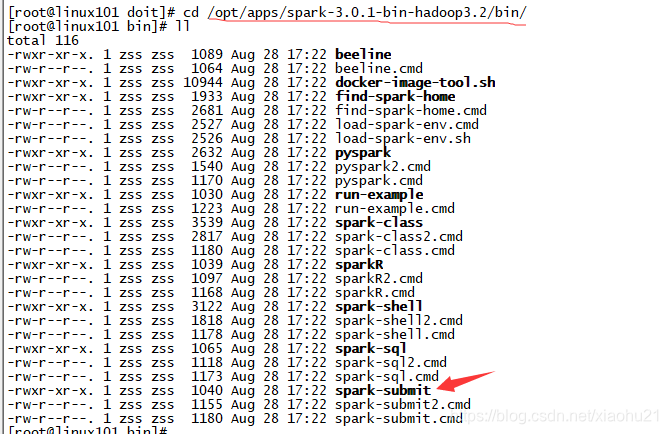
- 目前没有配置spark环境变量,所以需要cd到这个bin目录下执行spark-submit文件
./spark-submit --master spark://linux101:7077 --executor-memory 1g --total-executor-cores 4 --class Spark01InClusterFromHDFS /root/doit/spark_test1.jar
- ./spark-submit 是执行spark-submit程序
- –master 是参数名,指定spark主节点域名,实际参数就是spark://linux101:7077。注意7077是默认的访问spark主节点的端口,spark:// 是spark自定义的通信协议
- –executor-memory 是每个执行器executor的最高可用内存 1g,也可以使用mb为单位
- –total-executor-cores 是整个提交的程序可以使用的总共逻辑核心(不是真正的物理cpu核心,考虑到目前CPU性能,逻辑核心一般是实际cpu核心的1到3整数倍,具体看任务和电脑性能)
- –class 是提交的jar包的main方法入口类的全类名,这里没有使用包来管理,所以没有类似com.doit.XXX的全类名
- /root/doit/spark_test1.jar 这个是jar包所在地址
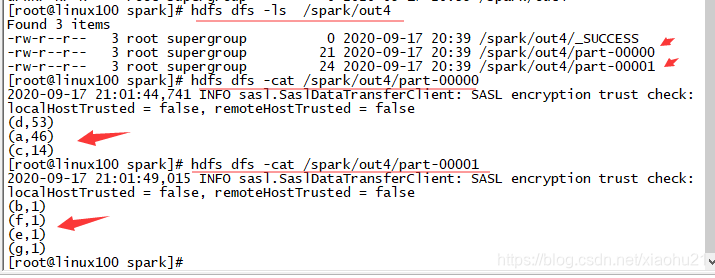
- 运行中状态
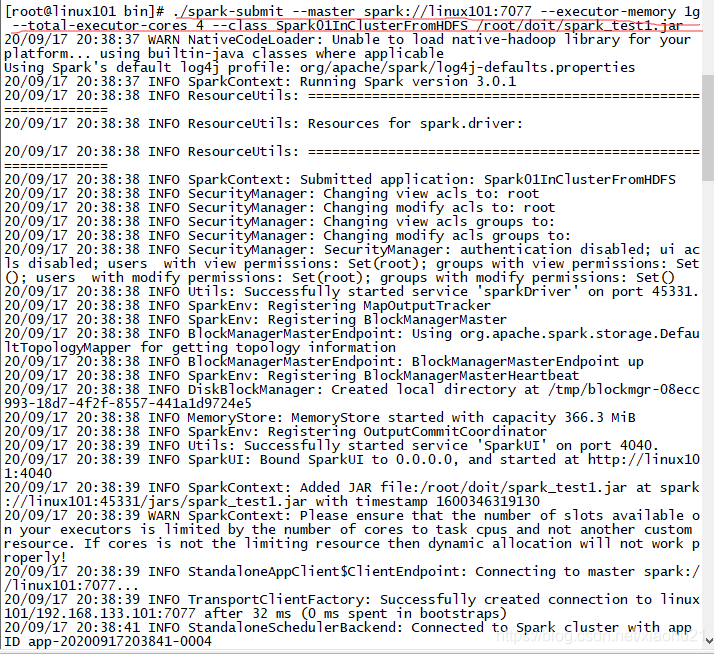
- 以下是运行的日志,从日志中可以看出spark的任务运行中的阶段和状态信息
[root@linux101 bin]# ./spark-submit --master spark://linux101:7077 --executor-memory 1g --total-executor-cores 4 --class Spark01InClusterFromHDFS /root/doit/spark_test1.jar
20/09/17 20:38:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/09/17 20:38:37 INFO SparkContext: Running Spark version 3.0.1
20/09/17 20:38:38 INFO ResourceUtils: ==============================================================
20/09/17 20:38:38 INFO ResourceUtils: Resources for spark.driver:
20/09/17 20:38:38 INFO ResourceUtils: ==============================================================
20/09/17 20:38:38 INFO SparkContext: Submitted application: Spark01InClusterFromHDFS
20/09/17 20:38:38 INFO SecurityManager: Changing view acls to: root
20/09/17 20:38:38 INFO SecurityManager: Changing modify acls to: root
20/09/17 20:38:38 INFO SecurityManager: Changing view acls groups to:
20/09/17 20:38:38 INFO SecurityManager: Changing modify acls groups to:
20/09/17 20:38:38 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
20/09/17 20:38:38 INFO Utils: Successfully started service 'sparkDriver' on port 45331.
20/09/17 20:38:38 INFO SparkEnv: Registering MapOutputTracker
20/09/17 20:38:38 INFO SparkEnv: Registering BlockManagerMaster
20/09/17 20:38:38 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/09/17 20:38:38 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/09/17 20:38:38 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
20/09/17 20:38:38 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-08ecc993-18d7-4f2f-8557-441a1d9724e5
20/09/17 20:38:38 INFO MemoryStore: MemoryStore started with capacity 366.3 MiB
20/09/17 20:38:38 INFO SparkEnv: Registering OutputCommitCoordinator
20/09/17 20:38:39 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/09/17 20:38:39 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://linux101:4040
20/09/17 20:38:39 INFO SparkContext: Added JAR file:/root/doit/spark_test1.jar at spark://linux101:45331/jars/spark_test1.jar with timestamp 1600346319130
20/09/17 20:38:39 WARN SparkContext: Please ensure that the number of slots available on your executors is limited by the number of cores to task cpus and not another custom resource. If cores is not the limiting resource then dynamic allocation will not work properly!
20/09/17 20:38:39 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://linux101:7077...
20/09/17 20:38:39 INFO TransportClientFactory: Successfully created connection to linux101/192.168.133.101:7077 after 32 ms (0 ms spent in bootstraps)
20/09/17 20:38:41 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20200917203841-0004
20/09/17 20:38:41 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20200917203841-0004/0 on worker-20200916185219-192.168.133.102-43504 (192.168.133.102:43504) with 2 core(s)
20/09/17 20:38:41 INFO StandaloneSchedulerBackend: Granted executor ID app-20200917203841-0004/0 on hostPort 192.168.133.102:43504 with 2 core(s), 1024.0 MiB RAM
20/09/17 20:38:41 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20200917203841-0004/1 on worker-20200916185217-192.168.133.101-44621 (192.168.133.101:44621) with 1 core(s)
20/09/17 20:38:41 INFO StandaloneSchedulerBackend: Granted executor ID app-20200917203841-0004/1 on hostPort 192.168.133.101:44621 with 1 core(s), 1024.0 MiB RAM
20/09/17 20:38:41 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20200917203841-0004/2 on worker-20200916185219-192.168.133.100-34827 (192.168.133.100:34827) with 1 core(s)
20/09/17 20:38:41 INFO StandaloneSchedulerBackend: Granted executor ID app-20200917203841-0004/2 on hostPort 192.168.133.100:34827 with 1 core(s), 1024.0 MiB RAM
20/09/17 20:38:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39936.
20/09/17 20:38:41 INFO NettyBlockTransferService: Server created on linux101:39936
20/09/17 20:38:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/09/17 20:38:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, linux101, 39936, None)
20/09/17 20:38:41 INFO BlockManagerMasterEndpoint: Registering block manager linux101:39936 with 366.3 MiB RAM, BlockManagerId(driver, linux101, 39936, None)
20/09/17 20:38:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, linux101, 39936, None)
20/09/17 20:38:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, linux101, 39936, None)
20/09/17 20:38:41 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
20/09/17 20:38:41 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20200917203841-0004/2 is now RUNNING
20/09/17 20:38:42 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20200917203841-0004/0 is now RUNNING
20/09/17 20:38:42 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20200917203841-0004/1 is now RUNNING
20/09/17 20:38:42 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 354.8 KiB, free 366.0 MiB)
20/09/17 20:38:42 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 33.3 KiB, free 365.9 MiB)
20/09/17 20:38:42 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on linux101:39936 (size: 33.3 KiB, free: 366.3 MiB)
20/09/17 20:38:42 INFO SparkContext: Created broadcast 0 from textFile at Spark01InClusterFromHDFS.scala:18
20/09/17 20:38:42 INFO deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
20/09/17 20:38:43 INFO FileInputFormat: Total input files to process : 1
20/09/17 20:38:43 INFO SparkContext: Starting job: sortBy at Spark01InClusterFromHDFS.scala:30
20/09/17 20:38:44 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
20/09/17 20:38:45 INFO DAGScheduler: Registering RDD 3 (map at Spark01InClusterFromHDFS.scala:24) as input to shuffle 0
20/09/17 20:38:45 INFO DAGScheduler: Got job 0 (sortBy at Spark01InClusterFromHDFS.scala:30) with 2 output partitions
20/09/17 20:38:45 INFO DAGScheduler: Final stage: ResultStage 1 (sortBy at Spark01InClusterFromHDFS.scala:30)
20/09/17 20:38:45 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
20/09/17 20:38:45 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
20/09/17 20:38:45 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Spark01InClusterFromHDFS.scala:24), which has no missing parents
20/09/17 20:38:45 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.133.100:53112) with ID 2
20/09/17 20:38:45 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 6.8 KiB, free 365.9 MiB)
20/09/17 20:38:45 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 3.9 KiB, free 365.9 MiB)
20/09/17 20:38:45 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on linux101:39936 (size: 3.9 KiB, free: 366.3 MiB)
20/09/17 20:38:45 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1223
20/09/17 20:38:45 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Spark01InClusterFromHDFS.scala:24) (first 15 tasks are for partitions Vector(0, 1))
20/09/17 20:38:45 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
20/09/17 20:38:45 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.133.100:39232 with 366.3 MiB RAM, BlockManagerId(2, 192.168.133.100, 39232, None)
20/09/17 20:38:45 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.133.100, executor 2, partition 0, ANY, 7366 bytes)
20/09/17 20:38:46 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.133.101:60198) with ID 1
20/09/17 20:38:46 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.133.102:43726) with ID 0
20/09/17 20:38:46 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.133.101:36428 with 366.3 MiB RAM, BlockManagerId(1, 192.168.133.101, 36428, None)
20/09/17 20:38:46 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 192.168.133.101, executor 1, partition 1, ANY, 7366 bytes)
20/09/17 20:38:46 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.133.102:40192 with 366.3 MiB RAM, BlockManagerId(0, 192.168.133.102, 40192, None)
20/09/17 20:38:46 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.133.100:39232 (size: 3.9 KiB, free: 366.3 MiB)
20/09/17 20:38:47 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.133.101:36428 (size: 3.9 KiB, free: 366.3 MiB)
20/09/17 20:38:55 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.133.101:36428 (size: 33.3 KiB, free: 366.3 MiB)
20/09/17 20:38:55 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.133.100:39232 (size: 33.3 KiB, free: 366.3 MiB)
20/09/17 20:38:57 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 12531 ms on 192.168.133.100 (executor 2) (1/2)
20/09/17 20:39:04 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 18035 ms on 192.168.133.101 (executor 1) (2/2)
20/09/17 20:39:04 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/09/17 20:39:04 INFO DAGScheduler: ShuffleMapStage 0 (map at Spark01InClusterFromHDFS.scala:24) finished in 19.051 s
20/09/17 20:39:04 INFO DAGScheduler: looking for newly runnable stages
20/09/17 20:39:04 INFO DAGScheduler: running: Set()
20/09/17 20:39:04 INFO DAGScheduler: waiting: Set(ResultStage 1)
20/09/17 20:39:04 INFO DAGScheduler: failed: Set()
20/09/17 20:39:04 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[7] at sortBy at Spark01InClusterFromHDFS.scala:30), which has no missing parents
20/09/17 20:39:04 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 6.4 KiB, free 365.9 MiB)
20/09/17 20:39:04 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.4 KiB, free 365.9 MiB)
20/09/17 20:39:04 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on linux101:39936 (size: 3.4 KiB, free: 366.3 MiB)
20/09/17 20:39:04 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1223
20/09/17 20:39:04 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (MapPartitionsRDD[7] at sortBy at Spark01InClusterFromHDFS.scala:30) (first 15 tasks are for partitions Vector(0, 1))
20/09/17 20:39:04 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
20/09/17 20:39:04 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, 192.168.133.101, executor 1, partition 0, NODE_LOCAL, 7147 bytes)
20/09/17 20:39:04 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, 192.168.133.100, executor 2, partition 1, NODE_LOCAL, 7147 bytes)
20/09/17 20:39:04 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.133.101:36428 (size: 3.4 KiB, free: 366.3 MiB)
20/09/17 20:39:04 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.133.101:60198
20/09/17 20:39:04 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.133.100:39232 (size: 3.4 KiB, free: 366.3 MiB)
20/09/17 20:39:04 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.133.100:53112
20/09/17 20:39:05 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 985 ms on 192.168.133.101 (executor 1) (1/2)
20/09/17 20:39:05 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 1033 ms on 192.168.133.100 (executor 2) (2/2)
20/09/17 20:39:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
20/09/17 20:39:05 INFO DAGScheduler: ResultStage 1 (sortBy at Spark01InClusterFromHDFS.scala:30) finished in 1.045 s
20/09/17 20:39:05 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
20/09/17 20:39:05 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
20/09/17 20:39:05 INFO DAGScheduler: Job 0 finished: sortBy at Spark01InClusterFromHDFS.scala:30, took 21.401796 s
20/09/17 20:39:05 INFO deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
20/09/17 20:39:05 INFO HadoopMapRedCommitProtocol: Using output committer class org.apache.hadoop.mapred.FileOutputCommitter
20/09/17 20:39:05 INFO FileOutputCommitter: File Output Committer Algorithm version is 2
20/09/17 20:39:05 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
20/09/17 20:39:05 INFO SparkContext: Starting job: runJob at SparkHadoopWriter.scala:78
20/09/17 20:39:05 INFO DAGScheduler: Registering RDD 5 (sortBy at Spark01InClusterFromHDFS.scala:30) as input to shuffle 1
20/09/17 20:39:05 INFO DAGScheduler: Got job 1 (runJob at SparkHadoopWriter.scala:78) with 2 output partitions
20/09/17 20:39:05 INFO DAGScheduler: Final stage: ResultStage 4 (runJob at SparkHadoopWriter.scala:78)
20/09/17 20:39:05 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 3)
20/09/17 20:39:05 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 3)
20/09/17 20:39:05 INFO DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[5] at sortBy at Spark01InClusterFromHDFS.scala:30), which has no missing parents
20/09/17 20:39:05 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 6.3 KiB, free 365.9 MiB)
20/09/17 20:39:05 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 3.6 KiB, free 365.9 MiB)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on linux101:39936 (size: 3.6 KiB, free: 366.3 MiB)
20/09/17 20:39:05 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1223
20/09/17 20:39:05 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 3 (MapPartitionsRDD[5] at sortBy at Spark01InClusterFromHDFS.scala:30) (first 15 tasks are for partitions Vector(0, 1))
20/09/17 20:39:05 INFO TaskSchedulerImpl: Adding task set 3.0 with 2 tasks
20/09/17 20:39:05 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 4, 192.168.133.100, executor 2, partition 0, NODE_LOCAL, 7136 bytes)
20/09/17 20:39:05 INFO TaskSetManager: Starting task 1.0 in stage 3.0 (TID 5, 192.168.133.101, executor 1, partition 1, NODE_LOCAL, 7136 bytes)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.133.100:39232 (size: 3.6 KiB, free: 366.3 MiB)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.133.101:36428 (size: 3.6 KiB, free: 366.3 MiB)
20/09/17 20:39:05 INFO TaskSetManager: Finished task 1.0 in stage 3.0 (TID 5) in 225 ms on 192.168.133.101 (executor 1) (1/2)
20/09/17 20:39:05 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 4) in 246 ms on 192.168.133.100 (executor 2) (2/2)
20/09/17 20:39:05 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
20/09/17 20:39:05 INFO DAGScheduler: ShuffleMapStage 3 (sortBy at Spark01InClusterFromHDFS.scala:30) finished in 0.258 s
20/09/17 20:39:05 INFO DAGScheduler: looking for newly runnable stages
20/09/17 20:39:05 INFO DAGScheduler: running: Set()
20/09/17 20:39:05 INFO DAGScheduler: waiting: Set(ResultStage 4)
20/09/17 20:39:05 INFO DAGScheduler: failed: Set()
20/09/17 20:39:05 INFO DAGScheduler: Submitting ResultStage 4 (MapPartitionsRDD[10] at saveAsTextFile at Spark01InClusterFromHDFS.scala:33), which has no missing parents
20/09/17 20:39:05 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 102.7 KiB, free 365.8 MiB)
20/09/17 20:39:05 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 37.6 KiB, free 365.8 MiB)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on linux101:39936 (size: 37.6 KiB, free: 366.2 MiB)
20/09/17 20:39:05 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1223
20/09/17 20:39:05 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 4 (MapPartitionsRDD[10] at saveAsTextFile at Spark01InClusterFromHDFS.scala:33) (first 15 tasks are for partitions Vector(0, 1))
20/09/17 20:39:05 INFO TaskSchedulerImpl: Adding task set 4.0 with 2 tasks
20/09/17 20:39:05 INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID 6, 192.168.133.101, executor 1, partition 0, NODE_LOCAL, 7147 bytes)
20/09/17 20:39:05 INFO TaskSetManager: Starting task 1.0 in stage 4.0 (TID 7, 192.168.133.100, executor 2, partition 1, NODE_LOCAL, 7147 bytes)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.133.100:39232 (size: 37.6 KiB, free: 366.2 MiB)
20/09/17 20:39:05 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.133.101:36428 (size: 37.6 KiB, free: 366.2 MiB)
20/09/17 20:39:05 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 192.168.133.101:60198
20/09/17 20:39:05 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 192.168.133.100:53112
20/09/17 20:39:06 INFO TaskSetManager: Finished task 1.0 in stage 4.0 (TID 7) in 304 ms on 192.168.133.100 (executor 2) (1/2)
20/09/17 20:39:06 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 6) in 325 ms on 192.168.133.101 (executor 1) (2/2)
20/09/17 20:39:06 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
20/09/17 20:39:06 INFO DAGScheduler: ResultStage 4 (runJob at SparkHadoopWriter.scala:78) finished in 0.345 s
20/09/17 20:39:06 INFO DAGScheduler: Job 1 is finished. Cancelling potential speculative or zombie tasks for this job
20/09/17 20:39:06 INFO TaskSchedulerImpl: Killing all running tasks in stage 4: Stage finished
20/09/17 20:39:06 INFO DAGScheduler: Job 1 finished: runJob at SparkHadoopWriter.scala:78, took 0.609898 s
20/09/17 20:39:06 INFO SparkHadoopWriter: Job job_20200917203905_0010 committed.
20/09/17 20:39:06 INFO SparkContext: Invoking stop() from shutdown hook
20/09/17 20:39:06 INFO SparkUI: Stopped Spark web UI at http://linux101:4040
20/09/17 20:39:06 INFO StandaloneSchedulerBackend: Shutting down all executors
20/09/17 20:39:06 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
20/09/17 20:39:06 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/09/17 20:39:06 INFO MemoryStore: MemoryStore cleared
20/09/17 20:39:06 INFO BlockManager: BlockManager stopped
20/09/17 20:39:06 INFO BlockManagerMaster: BlockManagerMaster stopped
20/09/17 20:39:06 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/09/17 20:39:06 INFO SparkContext: Successfully stopped SparkContext
20/09/17 20:39:06 INFO ShutdownHookManager: Shutdown hook called
20/09/17 20:39:06 INFO ShutdownHookManager: Deleting directory /tmp/spark-951d986b-0676-458d-9bb9-59c951374cd4
20/09/17 20:39:06 INFO ShutdownHookManager: Deleting directory /tmp/spark-ff322f2a-f8d9-43d6-8e46-52ca54cc8676
- 也可以使用web网页查看
http://linux101:8080/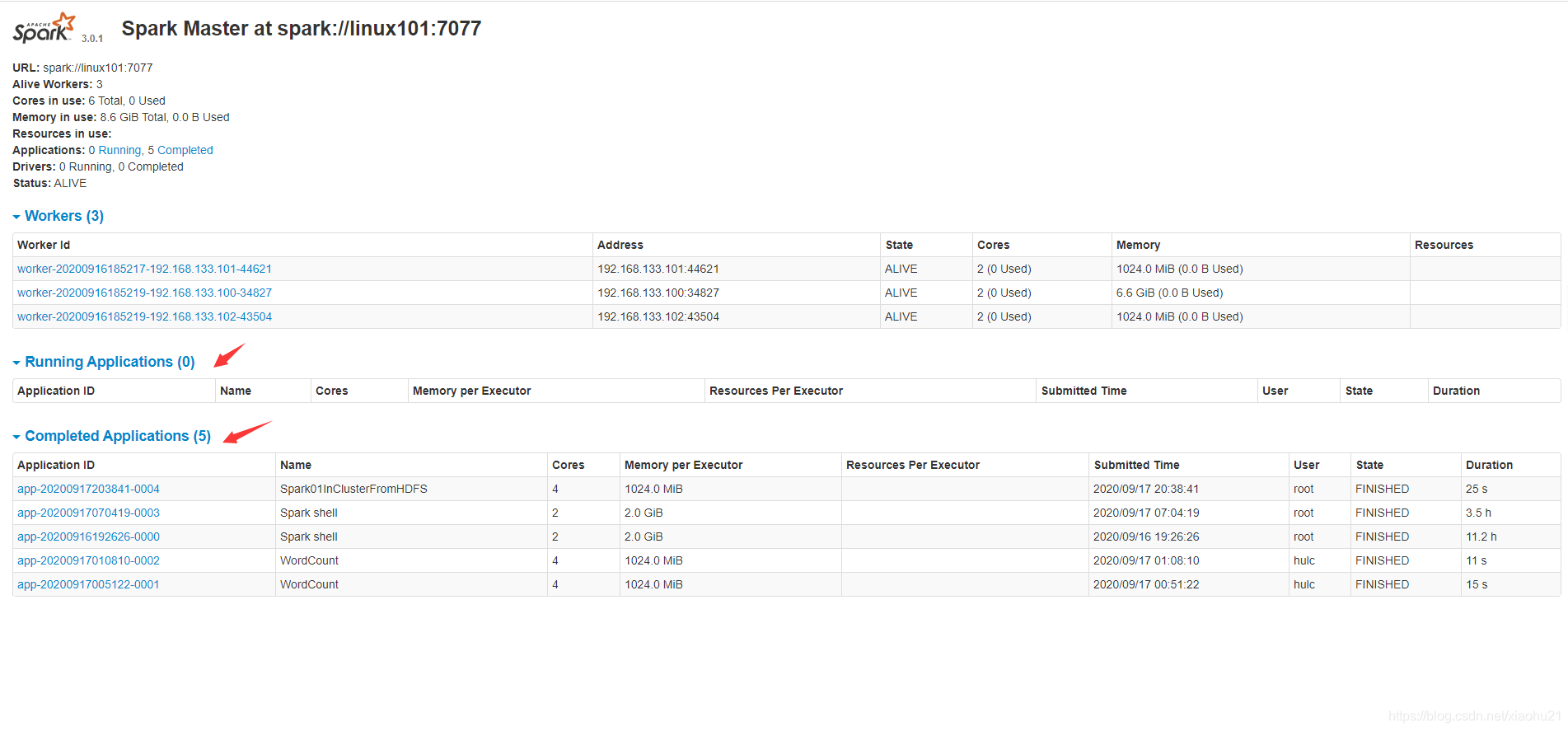
因为程序已经运行完毕,所以去已完成程序里面查看,就是上述25秒耗时那个任务,可以从时间,核心,内存等来判断是哪个任务。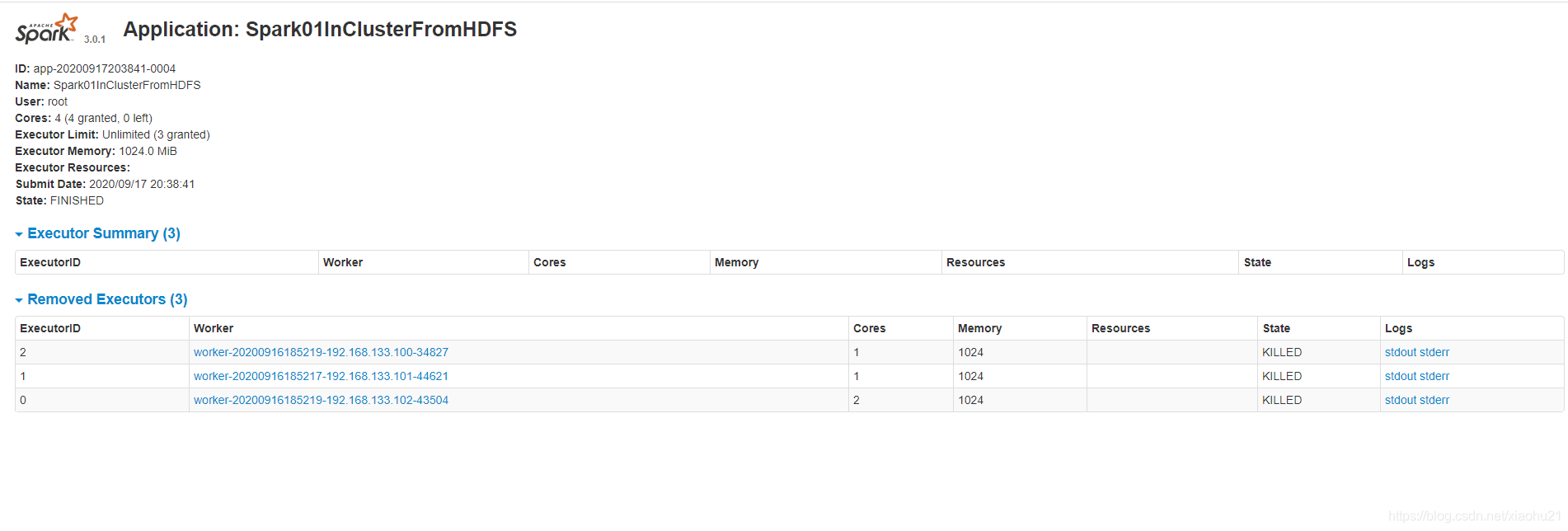
上述可以看到,执行器executor编号id,参与执行任务的worker节点,核心数,内存数
版权声明:本文为xiaohu21原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。