一,性能测试常用指标
| 序号 | 名称 | 含义 |
|---|---|---|
| 业务指标 | ||
| 1) | throughput | 吞吐量,指在一次性能测试过程中网络上传输的数据量总和 |
| 2) | 吞吐率 | 单位时间内网络上传输的数据量,也指单位时间内处理客户请求数量 |
| 3) | 事务 | 客户端一步或几步操作的集合,一个有完整意义的行为。一个页面的请求,一次完整的确认支付过程,一次登录。 |
| 4) | TPS | Transaction Per Second,每秒系统能处理的事务数量,一般衡量系统处理能力就是用TPS |
| 5) | QPS | Query Per Second,每秒查询接口数 |
| 6) | RPS | Request Per Second,每秒请求数 |
| 7) | HPS | Hits Per Second ,每秒点击数 |
| 8) | RT/ART | 响应时间 |
| 9) | VU | (并发数)(线程数) |
| 10) | PV | page view,页面浏览量 用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计。 |
| 11) | UV | Unique visitor,独立访客 通过客户端的cookies实现。即同一页面,客户端多次点击只计算一次,访问量不累计。 |
| 12) | IP | Internet Protocol,本意本是指网络协议,在数据统计这块指通过ip的访问量。 即同一页面,客户端使用同一个IP访问多次只计算一次,访问量不累计。 |
| 13) | Thinking Time | |
| 14) | 错误率 | |
| 资源指标 | ||
| 1) | CPU | 使用不高于80%+-5% |
| 2) | Memory (内存) | 使用不高于80% |
| 3) | Disk I/O(磁盘) | 使用不高于90% |
| 4) | Network I/O (网络) | |
| 移动性能指标 | ||
| 1) | 内存 | |
| 2) | CPU | |
| 3) | 流量 | |
| 4) | 电量 | |
| 5) | 启动速度 | |
| 6) | 滑动速度,界面切换速度 | |
| 7) | 与服务器交互的网络速度 | |
二,指标含义明细
1)IP访问和UV访问的区别
- 比如你是ADSL拨号上网,拨一次号自动分配一个IP,进入了网站,就算一个IP;断线了而没清理Cookies,又拨号一次自动分配一个IP,又进入了同一个网站,又统计到一个IP,这时统计数据里IP就显示统计了2次。UV没有变,是1次。
- 同一个局域网内2个人,在2台电脑上访问同一个网站,他们的公网IP是相同的。IP就是1,但UV是2。
2)TPS,QPS,RPS,HPS
- TPS :Transaction Per Second,每秒能处理的事务数
- QPS :Query Per Second,每秒能处理的查询数目
- RPS :Requests Per Second,每秒能处理的请求数目
- HPS :Hits per Second,每秒点击次数
1, TPS (每秒通过的事务数)
- Transaction Per Second:每秒事务数,指服务器在单位时间内(秒)可以处理的事务数量,一般以request/second为单位;
- 每秒钟处理完的事务次数,一般TPS是对整个系统来讲的。一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能会对应多个请求,对于衡量单个接口服务的处理能力,用QPS比较多。
- QPS是查询,而TPS是事务,事务是查询的入口,也包含其他类型的业务场景,因此QPS应该是 TPS的子集
2, QPS(每秒查询接口数)
- Query Per Second:每秒查询率,指服务器在单位时间内(秒)处理的查询请求速率
- 每秒钟处理完请求的次数;注意这里是处理完。具体是指发出请求到服务器处理完成功返回结果。可以理解在server中有个counter,每处理一个请求加1,1秒后counter=QPS
- 复数用户高频操作(QPS测试)
- 单一时间,复数用户同时操作(负载测试)
3,RPS(每秒请求数)
4,HPS(每秒点击数)
- 点击数是衡量Web服务器处理能力的一个重要指标。它的统计是客户端向Web服务器发了多少次HTTP请求计算的
- 点击数不是通常一般人认为的访问一个页面就是1次点击数,点击数是该页面包含的元素(如:图片、链接、框架等)向Web服务器发出的请求数数量
- 通常我们也用每秒点击次数(Hits per Second)指标来衡量Web服务器的处理能力
5,吞吐量(throughput,通常用TPS和QPS来表示)
一般用单位时间内系统处理请求的数量来定义。吞吐量直接体现了软件系统的业务处理能力:
- 请求数/单位时间
- 点击数/单位时间
- 字节数/单位时间
在一次性能测试过程中网络上传输的数据量的总和,也可以这样说在单次业务中,客户端与服务 器端进行的数据交互总量;
对交互式应用来说,吞吐量指标反映服务器承受的压力,容量规划的测试中,吞吐量是重点关注的 指标,它能够说明系统级别的负载能力,另外,在性能调优过程中,吞吐量指标也有重要的价值;
吞吐量和负载之间的关系:
①上升阶段:吞吐量随着负载的增加而增加,吞吐量和负载成正比;
②平稳阶段:吞吐量随着负载的增加而保持稳定,无太大变化或波动;
③下降阶段:吞吐量随着负载的增加而下降,吞吐量和负载成反比; 总结:吞吐量干不过负载!!!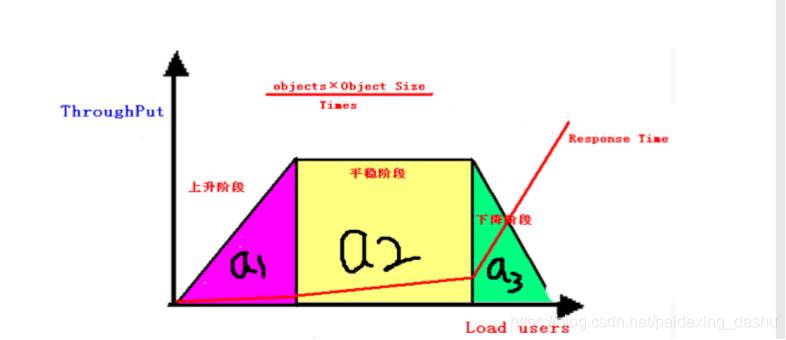
a1面积越大,说明系统的性能能力越强,a2面积越大,说明系统稳定性越好,a3面积越大,说明 系统的容错能力越好
6,并发数(线程数)
- 广义
单位时间内同时发送给服务器的请求数,不限定具体业务类型,强调的是同时发送 - 狭义
是单位时间内同时发送给服务器的相同的业务请求数,需限定具体的业务类型,强调业务请求相同 - 服务端视角
并发数为单位时间内服务端接收到的请求数 - 客户端视角
客户端的某个具体业务行为包括多个请求,并发数可被理解为客户端单位时间内同时发送给服务器端的请求数 - 用户视角
客户端的业务请求一般为用户操作行为,并发数也可理解为并发用户数,又可称为虚拟用户数
7, 响应时间/平均响应时间(RT/ART)
- Response Time/average Response Time:响应时间/平均响应时间,指一个事务花费多长 时间完成
- 一般来说,性能测试中平均响应时间更有代表意义。细分的话,还有最小最大响应时间,50%、 90%用户响应时间等
- 对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。
注:需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。
- 对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了
- 而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的
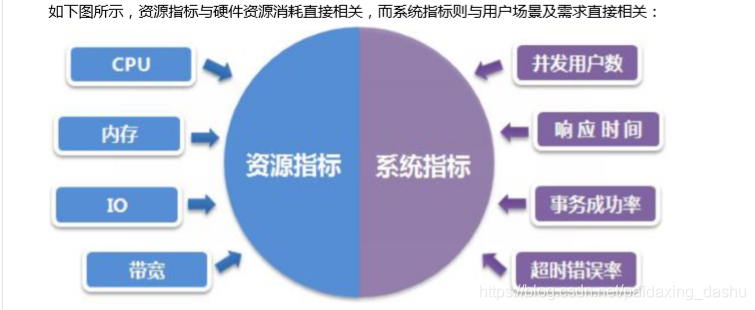
8,资源利用率
资源的使用量/总的资源可用量x100%形成资源利用率的数据。
通常下:
1)CPU不高于80%(浮动5)
2)内存不高于80%
3)磁盘不高于90%
9, 错误率
一般不超过千分之五,稳定性较好的系统,其错误率应该由超时引起,超时率
10. 利用率
- 在特定时间段内所使用容量占全部可用容量的百分比
- 最优利用率: 网络饱和之前的最大平均利用率。例如,共享以 太网的最大利用率一般不超过37%;令牌环和光 纤分布式数据接口(FDDI),典型的最优平均网 络利用率目标是70%;广域网的最优平均利用率 与令牌环相近,也为70%左右
11. PV/UV
PV:
page view的缩写,即页面浏览量,通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标
网页一般通过URL或标题(html title)来标识,大多数工具都提供了类似的定义方法]关于PV的统计要考虑2种特殊情况:
一是从服务器返回错误网页或重定向网页时,是否计数以及如何配置;
二是本地或网关服务器的缓存生效时是否计数
UV:
unique visitor的简写,是指通过互联网访问、浏览这个网页的自然人
UV是一个反映实际使用者的概念,每个UV相对于每个IP,更加准确地对应一个实际的浏览者。使用UV作为统计量,可以更加准确的了解单位时间内实际上有多少个访问者来到了相应的页面
12. Thinking Time
思考时间,在性能测试中,模拟用户的真实操作场景。用户操作的事务与事务之间是有一定间隔 的,引入这个概念是为了并发测试(有交叉业务场景)时,业务场景比率更符合真实业务场景;
13. 连接池
- 连接池是一个进程,多个连接在一个进程中存储、管理,它是共享、可复用的
- 当客户端发起请求,先检查是否有闲置连接,如果有,则分配该连接给其使用;如果没有,则请求 进入等待队列(等待空闲连接分配,这个取决于调度配置)或新建一个连接对象供其使用 (取决于连接池有多少连接以及允许的最大连接数)
- 每次客户端发起请求,如果都新建连接,会消耗很多的资源,连接池的存在及其特性,减少了连接 的建立所消耗的资源以及节省了很多连接创建时间,给系统提供了更好的伸缩性,也有助于 服务器性能的提升。
- 参观大佬
14. 标准方差
- 各数据偏离平均数的距离(离均差)的平均数,它能反应一个数据集的离散程度。离散程度越大, 数据越不可靠
- 性能测试中引入这个术语,是为了对高峰期、平缓期的系统响应时间分布,不同业务场景的响应时 间分布,以及I/o数在时间段上的分布等情况进行分析,以判断系统的稳定性
15. 容量(信道容量或带宽)
电路和网络传输数据的能力,通常以每秒 传输比特数来度量
16. 延迟
- 从报文开始进入网络/节点/链路到它开始离开网 络/节点/链路之间的时间,分别称为网络延迟、 节点延迟或链路延迟
- 延迟变化量: 也称为延迟抖动,指平均延迟变化的时间量
2)资源指标
1. CPU
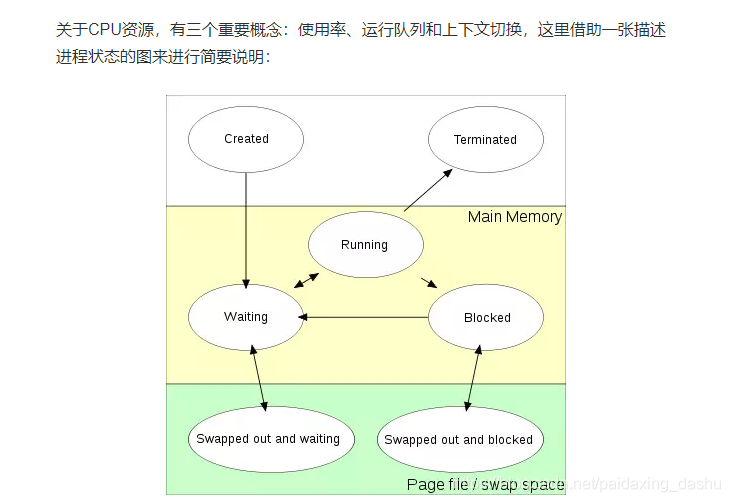

Linux查看方式

2,Memory
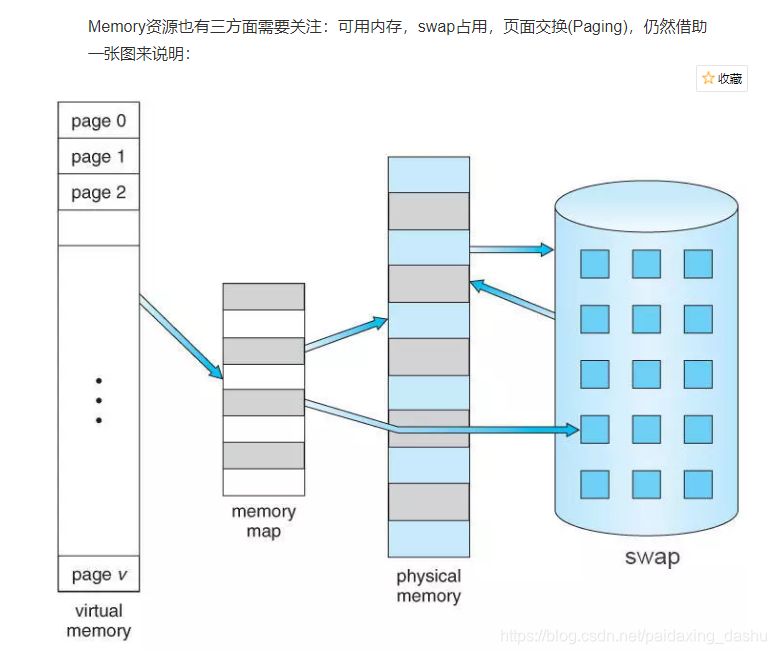

3, Disk

Linux查看方式

4,Network

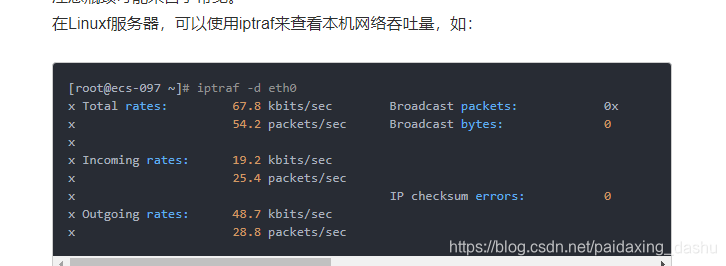
Linux查看方式
版权声明:本文为paidaxing_dashu原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。