最近在做一个多特征多步输出预测的时间序列预测问题,我打算将机器翻译的seq2seq的理论用在预测上面,通过nlp领域的机器翻译,从一般LSTM Seq2Seq -> GRU Seq2Seq -> 基于注意力机制的 Seq2Seq,分别讲解基于pytorch深度学习框架实现Encoder部分的对比。
关于序列到序列框架,在构建模型的时候,对Encoder和Decoder进行拆分,最后通过Seq2Seq整合,如果含有Attention机制,还需要增加attention模块。
Encoder就是处理输入Seq的模块,LSTM 和 GRU Seq2Seq比较类似,区别在于使用的cell类型(LSTM还是GRU)和输出结果(hidden,cell还是只有hidden),attention机制Seq2Seq复杂一些,因为是双向的。
1、LSTM Seq2Seq Encoder
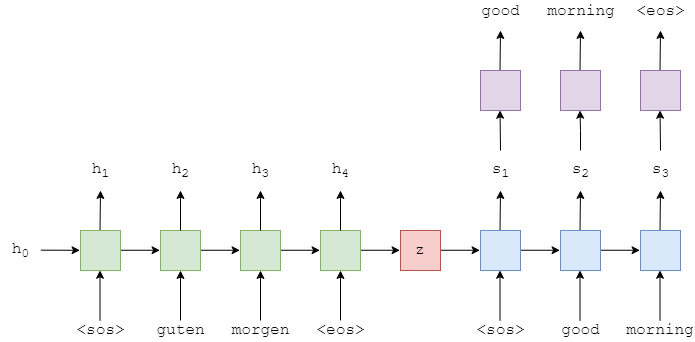
2层LSTM,数据顺序从下往上。Encoder输入参数:
input_dim输入encoder的one-hot向量维度,这个和输入词汇大小一致,就是输入字典长度;
emb_dim嵌入层的维度,这一层将one-hot向量转为密度向量,256
词嵌入在 pytorch 中只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,是一种降维,相当于是一个大矩阵,矩阵的每一行表示一个单词。
hid_dim隐藏和cell的状态维度,512;
n_layers RNN层数,这里就是2;
dropout是要使用的丢失量。这是一个防止过度拟合的正则化参数,0.5;
Encoder返回参数:
- hidden,隐藏状态
- cell,单元状态
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super(Encoder,self).__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.hid_dim=hid_dim
self.n_layers=n_layers
self.dropout=dropout
self.embedding=nn.Embedding(input_dim,emb_dim)
self.rnn=nn.LSTM(emb_dim,hid_dim,n_layers,dropout=dropout)
self.dropout=nn.Dropout(dropout)
def forward(self, src):
embedded=self.dropout(self.embedding(src))
outputs, (hidden,cell)=self.rnn(embedded)
return hidden ,cell
2、GRU Seq2Seq Encoder
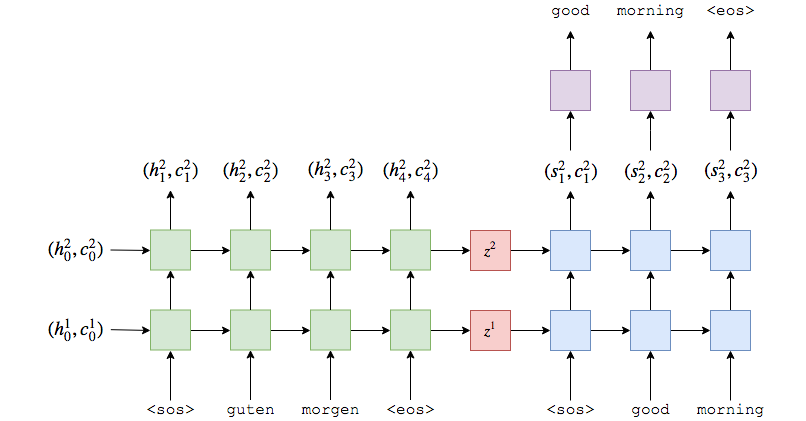
和LSTM比较类似,做了单层GRU,dropout不再作为参数传入GRU,返回结果只有hidden状态
Encoder输入参数:
- input_dim输入encoder的one-hot向量维度,这个和输入词汇大小一致,就是输入字典长度;
- emb_dim嵌入层的维度,这一层将one-hot向量转为密度向量,256;
词嵌入在 pytorch 中只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,是一种降维,相当于是一个大矩阵,矩阵的每一行表示一个单词。 - hid_dim隐藏和cell的状态维度,512;
- dropout是要使用的丢失量。这是一个防止过度拟合的正则化参数,0.5;
Encoder返回参数:
- hidden,隐藏状态
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, dropout):
super(Encoder,self).__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.hid_dim=hid_dim
self.dropout=dropout
self.embedding=nn.Embedding(input_dim,emb_dim)
self.rnn=nn.GRU(emb_dim,hid_dim)
self.dropout=nn.Dropout(dropout)
def forward(self, src):
embedded=self.dropout(self.embedding(src))
outputs, hidden=self.rnn(embedded)
return hidden
3、attention Seq2Seq Encoder
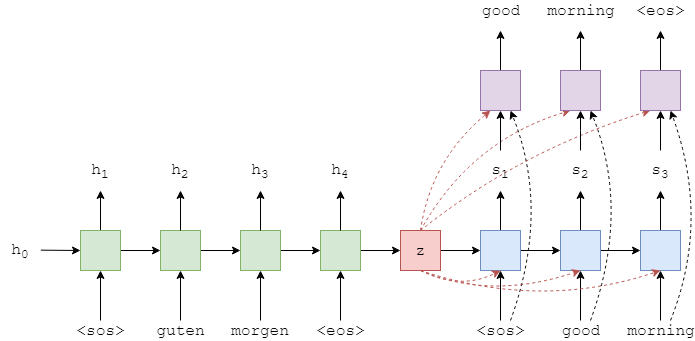
因为attention机制这个差别就比较大,使用单层GRU,通过bidirectional RNN,每层可以有两个RNN网络,这样就可以从左到右,从右到左对输入seq进行观察,得到上下文向量,从某种意义上说,是一种对文本的理解。
Encoder输入参数:
- input_dim输入encoder的one-hot向量维度,这个和输入词汇大小一致,就是输入字典长度;
- emb_dim嵌入层的维度,这一层将one-hot向量转为密度向量,256;
词嵌入在 pytorch 中只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,是一种降维,相当于是一个大矩阵,矩阵的每一行表示一个单词。 - enc_hid_dim encoder隐藏和cell的状态维度,512;
- dec_hid_dim decoder隐藏和cell的状态维度,512;
- dropout是要使用的丢失量。这是一个防止过度拟合的正则化参数,0.5;

class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super(Encoder,self).__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.enc_hid_dim=enc_hid_dim
self.dec_hid_dim=dec_hid_dim
self.dropout=dropout
self.embedding=nn.Embedding(input_dim,emb_dim)
self.rnn=nn.GRU(emb_dim,enc_hid_dim,bidirectional=True)
self.fc=nn.Linear(enc_hid_dim*2,dec_hid_dim)
self.dropout=nn.Dropout(dropout)
def forward(self, src):
embedded=self.dropout(self.embedding(src))
outputs, hidden=self.rnn(embedded)
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))
return outputs, hidden