1 数据类型
| 数据类型 | 类型名称 | 取值范围 | 字节数 |
|---|---|---|---|
| boolean | 布尔类型 | 0或1 | 1 bit |
| tinyint | 微整数类型 | -128到127 | 1字节 |
| smallint | 整数类型 | -32768到32767 | 2字节 |
| int | 整数类型 | -2147483648到2147483647 | 4字节 |
| bigint | 大整数类型 | -9223372036854775808到9223372036854775807 | 8字节 |
| float | 单精度浮点数 | -3.402823466E+38到-1.175494351E-38, 0, 1.175494351E-38到3.402823466E+38, IEEE标准 | 4字节 |
| double | 双精度浮点数 | -1.7976931348623157E+308到-2.2250738585072014E-308, 0, 2.2250738585072014E-308 到 1.7976931348623157E+308. IEEE标准 | 8字节 |
| varchar | 变长字符串类型 | 最大长度8k | 变长 |
| date | 日期类型 | ‘1000-01-01’ 到 '9999-12-31’支持的数据格式为 ‘YYYY-MM-DD’ | 4字节 |
| timestamp | 时间戳类型 | ‘1970-01-01 00:00:01.000’ UTC 到 ‘2038-01-19 03:14:07.999’ UTC. 支持的的数据格式为:‘YYYY-MM-DD HH:MM:SS’ | 4字节 |
| multivalue | 多值列类型 | String 类型的多个值,各值间默认分隔符为英文半角逗号(,) |
多值列
- 多值列是ADB特有的数据类型,多值列可以存入String类型的多个值,各值间的分隔符默认为英文半角逗号(,)。
- 多值列数据存入ADB后,可使用 IN(OR的关系)或 CONTAINTS(AND的关系) 条件对该列的单个值进行查询。
- 如果您对某个多值列进行了枚举查询,则该多值列的每个值可像一个普通列一样进行各类操作;如果您未对某个多值列进行枚举查询,则不可直接在 SELECT 或 GROUP BY 语句中使用该多值列。
CREATE TABLE table_2 (
userid bigint COMMENT '',
productid multivalue,
PRIMARY KEY (userid)
)
PARTITION BY HASH KEY (userid) PARTITION NUM 8
TABLEGROUP ads_demo
OPTIONS (UPDATETYPE='realtime')
COMMENT '';
insert into table_2 VALUES (1, 'A,B,C' );
insert into table_2 VALUES (2, 'A,B' );
select * from table_2 where productid contains ('A','B');
与MySQL数据类型对比
见高级部分
2 建表
在ADB中,您可通过DDL语句创建(CREATE)、修改(ALTER)、删除(DROP)事实表和维度表。
创建事实表
语法:
CREATE TABLE [db_name.]table_name
(
col1 bigint COMMENT 'col1',
col2 varchar COMMENT 'col2',
col3 int COMMENT 'col3',
col4 bigint [disableIndex true] COMMENT 'col4',
col5 multivalue COMMENT 'col5 多值列',
[primary key(col1, col3)]
)
PARTITION BY HASH KEY (col1) PARTITION NUM [2-256]
[SUBPARTITION BY LIST (part_col2 bigint)]
[SUBPARTITION OPTIONS (available_partition_num =[1-90])]
[CLUSTERED BY(col3,col4)]
TABLEGROUP tablegroup_name
[options (updateType='{realtime | batch}')];
说明 []内的参数项均为可选项。
必填参数描述
| 参数 | 描述 | 说明 |
|---|---|---|
| db_name | 数据库名称。 | N/A |
| table_name | 表名称。 | 不可与当前数据库中现有表重复。 |
| col* | 语句中的 col1 bigint COMMENT ‘col1’ 等是表的列信息,基本格式为: col_name type NOT NULL | NULL] [DEFAULT default_value] [COMMENT ’ string’] [disableIndex true] 其中[]中的参数为可选参数,关键参数说明如下:
| 同一张数据表中,列名称不可重复。一个事实表最大支持1024个列。 |
| primary key () | 表的主键,用于唯一地标识表中的某一条记录;表关联时用来在一个表中引用另一个表的指定记录。 | 实时更新表至少需要设置一个主键;批量更新表不需要设置主键。 |
| PARTITION BY HASH KEY() | 一级分区列,必须是一个主键列,只支持HASH分区。HASH分区根据实际数据中的某一列的内容进行分区。一个HASH分区一般不宜超过2000万条记录。您可通过设置二级分区来扩大数据存储容量。 如果表仅有一级HASH分区并且是批量更新表,则每次导入数据时会对已有数据进行全量覆盖。如果每次导入数据是增量导入,则您需要设置二级分区。 | 事实表必须指定一级分区列。HASH分区列的数据需要尽可能保持均匀分布,如果有明显的数据倾斜,则会严重的影响查询性能。 |
| PARTITION NUM | HASH分区数,最小支持2个,最大支持256个。 | 同一个表组中的所有表,HASH分区数建议一致。 |
| TABLEGROUP | 事实表所归属的表组。 | 一个事实表组最多可以创建256个事实表。 |
选填参数描述
| 参数名称 | 描述 | 备注 |
|---|---|---|
| SUBPARTITION BY LIST () | 二级分区列,只支持LIST分区。二级分区为非动态分区,即分区值不是由数据本身决定的,而是由每次导入/写入数据时用户指定的。 二级分区列必须是新的列,不可与已有的列重复,列数据类型只支持bigint型。 | 如果每次导入数据是增量导入,则需要指定二级LIST分区信息。 实时更新表的二级分区仅用于极大的扩展单表容量、生命周期管理,其增量更新不依赖于二级分区。 |
| SUBPARTITION OPTIONS () | 最大保留的二级分区数,最大支持365*3个。 新数据装载后,如果线上存在的二级分区数大于这个值,那么会根据二级分区的值进行排序,下线最小的若干分区的数据。 | N/A |
| CLUSTERED BY () | 聚集列,可指定多列。如果指定多列,那么该表的数据聚集顺序按照DDL中这个子句中指定的列组合顺序进行排序。 在物理上,同一个分区内聚集列内容相同的数据会尽可能的分布在同样的区块进行存储。 | 如果您将表查询中肯定会涉及到的并且数据区分度很大的列设置为聚集列,则可能较显著的提升查询性能。 |
| updateType | 表数据更新方式: realtime:实时更新,只支持实时写入数据。 batch:批量更新,只支持批量离线导入数据。 不带此参数时,默认为批量更新。 | N/A |
常用分区方法:
创建表时,一般将需要频繁进行Join的列(例如买家ID)作为一级Hash分区列,将日期列作为二级分区列。这样的表既可以进行大表Join的加速,又可以每天进行增量数据导入,并且指定保留若干天的数据在线上来进行生命周期管理。
一级分区数量和二级分区数量需要根据表的数据量、数据库拥有的资源数来设置,并非越多越好。如果一级分区和二级分区过多而数据库的资源数过少,则分区的数据Meta很容易将内存耗尽。
示例:
CREATE TABLE t_fact_customers
(
customer_id varchar COMMENT '',
customer_name varchar COMMENT '',
phone_number varchar COMMENT '',
address varchar COMMENT '',
last_login_time timestam
3 插入
通过INSERT语句,您可将数据实时插入到ADB的实时更新表中。插入数据后,约一分钟即可查询。
基本语法
INSERT INTO table_name [ ( column [, ... ] ) ] VALUES [(),()]
- 按默认建表列顺序插入数据时,您可以不带列参数:
INSERT INTO table_name VALUES (?,?,?,...)。
说明按此模式插入数据时,VALUES中对应的数据列顺序必须符合表定义时的列顺序。您可通过以下语句查询表的列定义顺序:
SHOW CREATETABLE db_name.table_name;
- 指定列名插入数据:
INSERT INTO table_name(co1,col2,col3,...) VALUES(?,?,?,...)。 - 一次插入多条记录:
INSERT INTO table_name(co1,col2,col3,...) VALUES(?,?,?,...),(?,?,?,...),(?,?,?,...)
当前,一次提交16KB数据时,数据库性能处于最佳状态。现场实际使用时,建议根据表行长来确定一次提交的记录数 N ,N = 16KB/rowsize。
INSERT IGNORE 与 INSERT
INSERT和INSERT IGNORE的区别如下:
INSERT:主键覆盖,即如果当前插入的记录与数据库中已有的记录主键相同,则覆盖已有记录。INSERT IGNORE:如果当前插入的记录与数据库中已有的记录主键相同,则丢弃正在插入的新记录,保留已有记录。
在实际应用中,您可根据业务应用的需求来选择 INSERT 或 INSERT IGNORE 语句。
常规聚合函数
| 函数名 | 表达式及返回值类型 | 说明描述 |
|---|---|---|
| arbitrary | arbitrary(x) → [类型与输入参数相同] | 返回 x 的任意非 NULL 值。 |
| array_agg | array_agg(x) → array<[类型和输入参数相同]> | 返回以输入参数 x 为元素的数组。 |
| avg | avg(x) → double | 返回所有输入值的平均数(算数平均数)。 |
| bool_and | bool_and(boolean) → boolean | 所有参数均为 TRUE ,则返回 TRUE ,否则返回 FALSE 。 |
| bool_or | bool_or(boolean) → boolean | 任何一个参数为 TRUE ,则返回 TRUE , 否则返回 FALSE 。 |
| checksum | checksum(x) → varbinary | 返回不受给定参数值顺序影响的校验值。 |
| count | count(*) → bigint count(x) → bigint | 返回输入数据行的统计个数。 返回非 NULL 值的输入参数个数。 |
| count_if | count_if(x) → bigint | 返回输入参数中 TRUE 的个数。 这个函数和 count(CASE WHEN x THEN 1 END) 等同。 |
| every | every(boolean) → boolean | 这个函数是 bool_and() 的别名。 |
| geometric_mean | geometric_mean(x) → double | 返回所有输入参数的几何平均值。 |
| max_by | max_by(x, y) → [与x类型相同] max_by(x, y, n) → array<[与x类型相同]> | 返回 x 与 y 的全部关联中,y 最大值所关联的第一个 x 值。 x 与 y 的全部关联中, 以 y 降序排列前 n 个最大值所关联的 x 值中, 返回前 n 个值。 |
| min_by | min_by(x, y) → [与x类型相同] min_by(x, y, n) → array<[与x类型相同]> | 返回 x 与 y 的全部关联中,y 最小值所关联的第一个 x 值。 x 与 y 的全部关联中, 以 y 升序排列前 n 个值所关联的 x 值中, 返回前 n 个值。 |
| max | max(x) → [与输入类型相同] max(x, n) → array<[与x类型相同]> | 返回输入参数中最大的值。 返回所有参数 x 中前 n 大的值。 |
| min | min(x) → [与输入类型相同] min(x, n) → array<[与x类型相同]> | 返回所有输入参数中最小的值。 返回所有输入参数 x 中,前 n 小的值。 |
| sum | sum(x) → [和输入类型相同] | 返回所有输入参数的和。 |
函数用例
arbitrary(x) → [类型与输入参数相同]
SQL 示例:
/*+engine=mpp*/select arbitrary(customer_name) from t_fact_customers;
返回结果(返回任意非null costomer_name):
mysql> /*+engine=mpp*/select arbitrary(customer_name) from t_fact_customers;
+-----------+
| _col0 |
+-----------+
| 孙大帅 |
+-----------+
1 row in set (0.27 sec)
array_agg(x) → array<[类型和输入参数相同]>
SQL 示例:
/*+engine=mpp*/select array_agg(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select array_agg(customer_id) from t_fact_customers;
+---------------------------------+
| _col0 |
+---------------------------------+
| [2, 9, 3, 8, 10, 1, 5, 4, 6, 7] |
+---------------------------------+
1 row in set (0.18 sec)
avg(x) → double
SQL 示例:
/*+engine=mpp*/select avg(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select avg(customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 5.5 |
+-------+
1 row in set (0.30 sec)
bool_and(boolean) → boolean
SQL 示例(sex存在为1):
/*+engine=mpp*/select bool_and(sex = 0) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select bool_and(sex = 0) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 0 |
+-------+
1 row in set (0.09 sec)
bool_or(boolean) → boolean
SQL 示例:
/*+engine=mpp*/select bool_or(sex = 0) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select bool_or(sex = 0) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 1 |
+-------+
1 row in set (0.09 sec)
checksum(x) → varbinary
SQL 示例:
/*+engine=mpp*/select checksum(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select checksum(customer_id) from t_fact_customers;
+-------------------------+
| _col0 |
+-------------------------+
| fd d8 7d 03 15 52 63 9a |
+-------------------------+
1 row in set (0.20 sec)
count(*) → bigint
SQL 示例:
/*+engine=mpp*/select count(*) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select count(*) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 10 |
+-------+
1 row in set (0.13 sec)
count(x) → bigint
SQL 示例:
/*+engine=mpp*/select count(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select count(customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 10 |
+-------+
1 row in set (0.10 sec)
count_if(x) → bigint
SQL 示例:
/*+engine=mpp*/select count_if(sex = 0) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select count_if(sex = 0) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 6 |
+-------+
1 row in set (0.12 sec)
every(boolean) → boolean
SQL 示例:
/*+engine=mpp*/select every(sex = 1) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select every(sex = 1) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 0 |
+-------+
1 row in set (0.10 sec)
geometric_mean(x) → double
SQL 示例:
/*+engine=mpp*/select geometric_mean(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select geometric_mean(customer_id) from t_fact_customers;
+--------------------+
| _col0 |
+--------------------+
| 4.5287286881167645 |
+--------------------+
1 row in set (0.11 sec)
max_by(x, y) → [与x类型相同]
SQL 示例:
/*+engine=mpp*/select max_by(sex, customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select max_by(sex, customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 0 |
+-------+
1 row in set (0.17 sec)
max_by(x, y, n) → array<[与x类型相同]>
SQL 示例:
/*+engine=mpp*/select max_by(customer_id, sex, 3) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select max_by(customer_id, sex, 3) from t_fact_customers;
+-----------+
| _col0 |
+-----------+
| [5, 6, 9] |
+-----------+
1 row in set (0.14 sec)
min_by(x, y) → [与x类型相同]
SQL 示例:
/*+engine=mpp*/select min_by(customer_id, sex) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select min_by(customer_id, sex) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 4 |
+-------+
1 row in set (0.09 sec)
min_by(x, y, n) →array<[与x类型相同]>
SQL 示例:
/*+engine=mpp*/select min_by(customer_id, sex, 3) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select min_by(customer_id, sex, 3) from t_fact_customers;
+------------+
| _col0 |
+------------+
| [10, 8, 1] |
+------------+
1 row in set (0.18 sec)
max(x) → [与输入类型相同]
SQL 示例:
/*+engine=mpp*/select max(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select max(customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 10 |
+-------+
1 row in set (0.10 sec)
max(x, n) → array<[与x类型相同]>
SQL 示例:
/*+engine=mpp*/select max(customer_id,3) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select max(customer_id,3) from t_fact_customers;
+------------+
| _col0 |
+------------+
| [10, 9, 8] |
+------------+
1 row in set (0.20 sec)
min(x) → [与输入类型相同]
SQL 示例:
/*+engine=mpp*/select min(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select min(customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 1 |
+-------+
1 row in set (0.13 sec)
min(x, n) →array<[与x类型相同]>
SQL 示例:
/*+engine=mpp*/select min(customer_id, 3) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select min(customer_id, 3) from t_fact_customers;
+-----------+
| _col0 |
+-----------+
| [1, 2, 3] |
+-----------+
1 row in set (0.08 sec)
sum(x) → [和输入类型相同]
SQL 示例:
/*+engine=mpp*/select sum(customer_id) from t_fact_customers;
返回结果:
mysql> /*+engine=mpp*/select sum(customer_id) from t_fact_customers;
+-------+
| _col0 |
+-------+
| 55 |
+-------+
1 row in set (0.13 sec)
窗口函数
概述
窗口函数是基于查询结果的行数据进行计算的函数,运行在 HAVING 子句之后 ORDER BY 子句之前。触发一个窗口函数需要特殊的关键字 OVER子句来指定窗口。
一个窗口包含三个组成部分:
- 分区规范:用于将输入行分裂到不同的分区中,与 GROUP BY 子句的分裂过程相似。
- 排序规范:用于决定输入数据行在窗口函数中执行的顺序。
- 窗口框架:用于指定一个滑动窗口的数据,以给窗口函数指定需要处理的行数据。如果这个框架没有指定,则默认是 RANGE UNBOUNDED PRECEDING (与 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 相同),默认框架包含当前分区中所有从开始到目前行所有数据。
聚合函数
所有聚合函数可以通过添加 OVER 子句来作为窗口函数使用。这些聚合函数会基于当前 滑动窗口内的数据行计算每一行数据。
聚合函数作为窗口函数使用的示例如下:
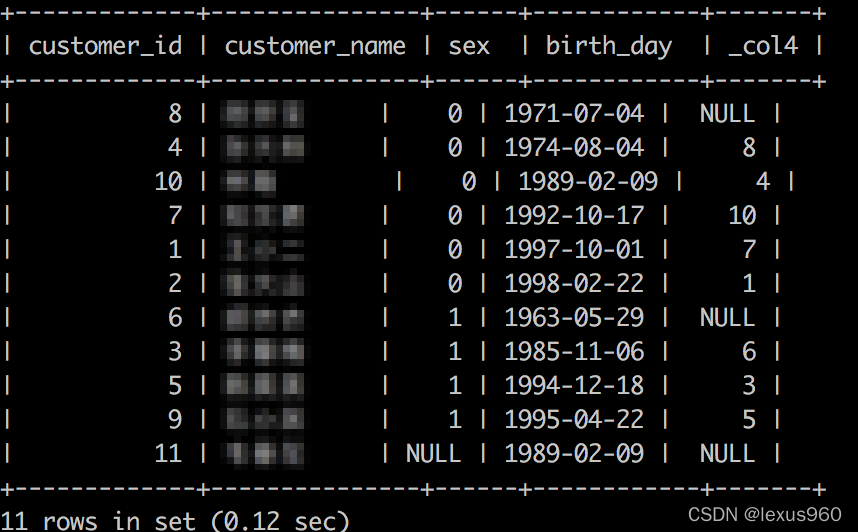
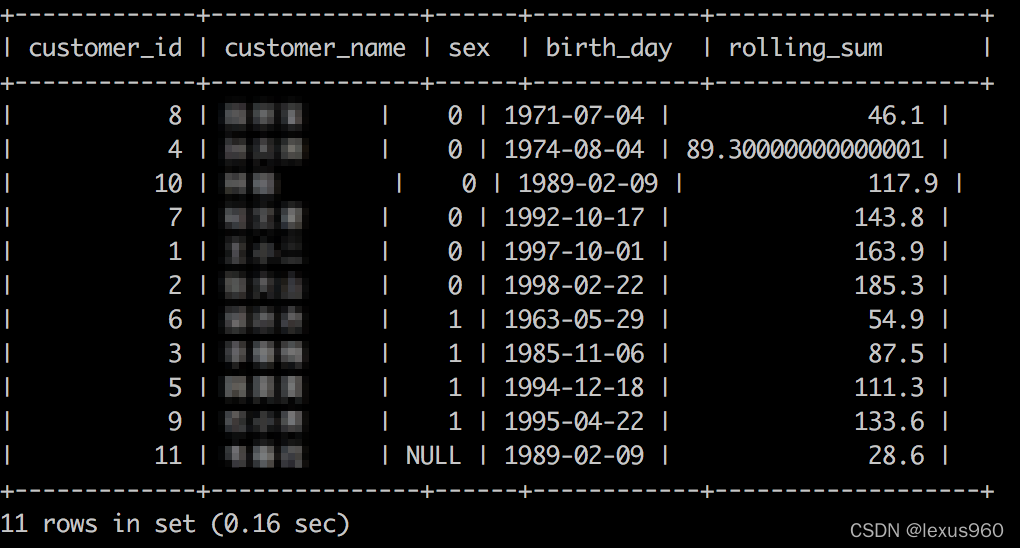
SELECT customer_id, customer_name, sex,birth_day,
sum(age) OVER (PARTITION BY sex ORDER BY birth_day) AS rolling_sum
FROM t_fact_customers;
排序函数
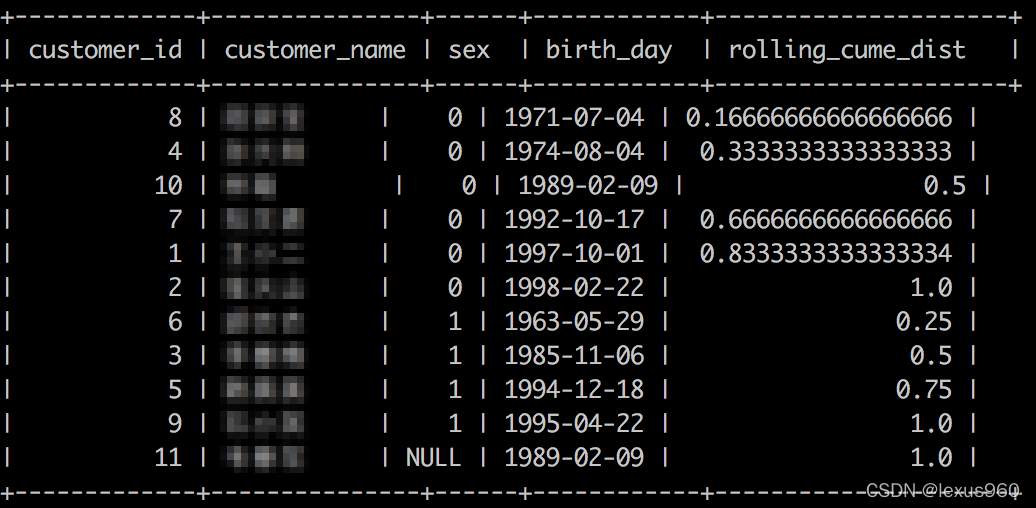
cume_dist() → bigint
返回一组数值中每个值的累计分布。结果返回的是按照窗口分区下窗口排序后的数据集下,当前行前面包括当前行数据的行数。因此,排序中任何关联值均会计算成相同的分布值。
SELECT customer_id,customer_name,sex,birth_day,
cume_dist()OVER(PARTITIONBY sex ORDERBY birth_day)AS rolling_cume_dist
FROM t_fact_customers;
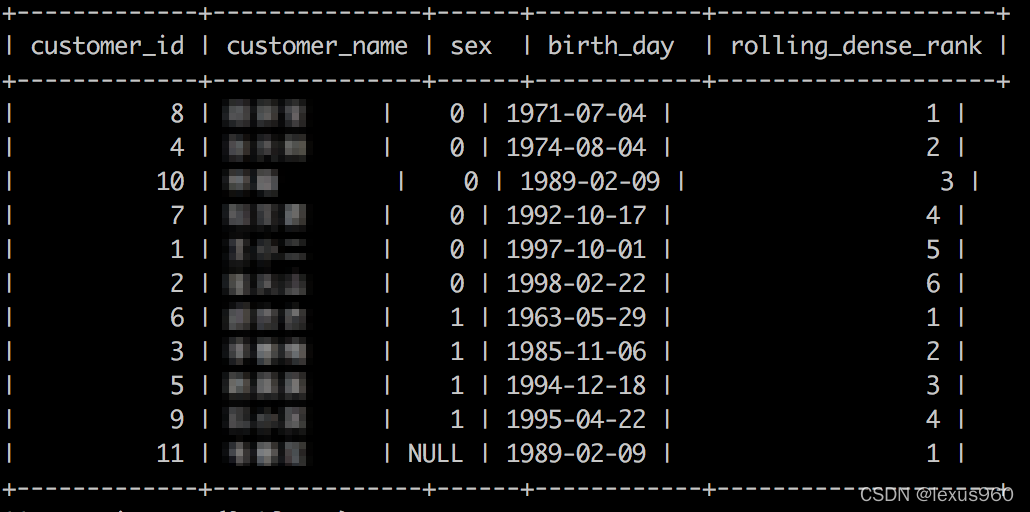
dense_rank() → bigint
返回一组数值中每个数值的排名。这个函数与 rank() 相似,但该函数关联值不会产生顺序上的空隙。
SELECT customer_id,customer_name,sex,birth_day,
dense_rank()OVER(PARTITIONBY sex ORDERBY birth_day)AS rolling_dense_rank
FROM t_fact_customers;
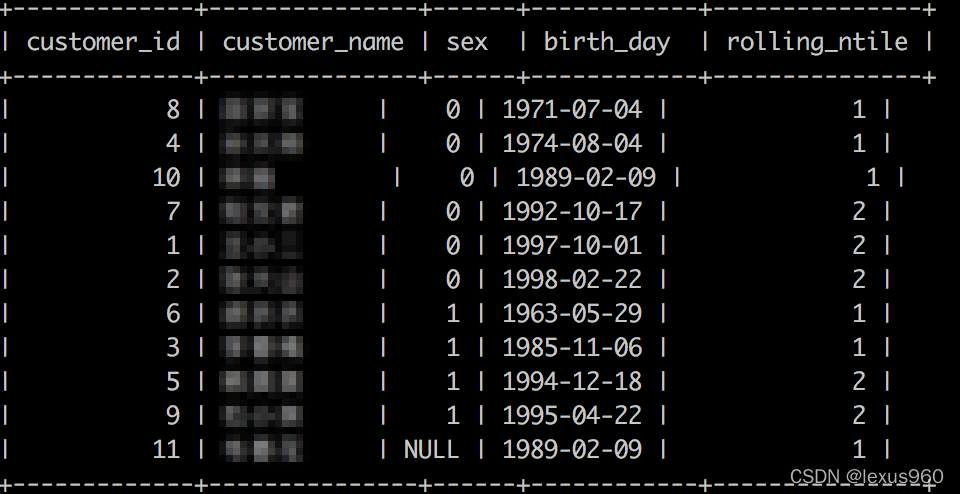
ntile(n) → bigint
将每个窗口分区的数据分裂到 n 个桶中(桶号从 1 到最大 n ,桶号值最多间隔是 1)。 如果窗口分区中的数据行数不能均匀的分到每一个桶中,则剩余值将每一个桶分一个,从第一个桶开始。
SELECT customer_id,customer_name,sex,birth_day,
ntile(2)OVER(PARTITIONBY sex ORDERBY birth_day)AS rolling_ntile
FROM t_fact_customers;
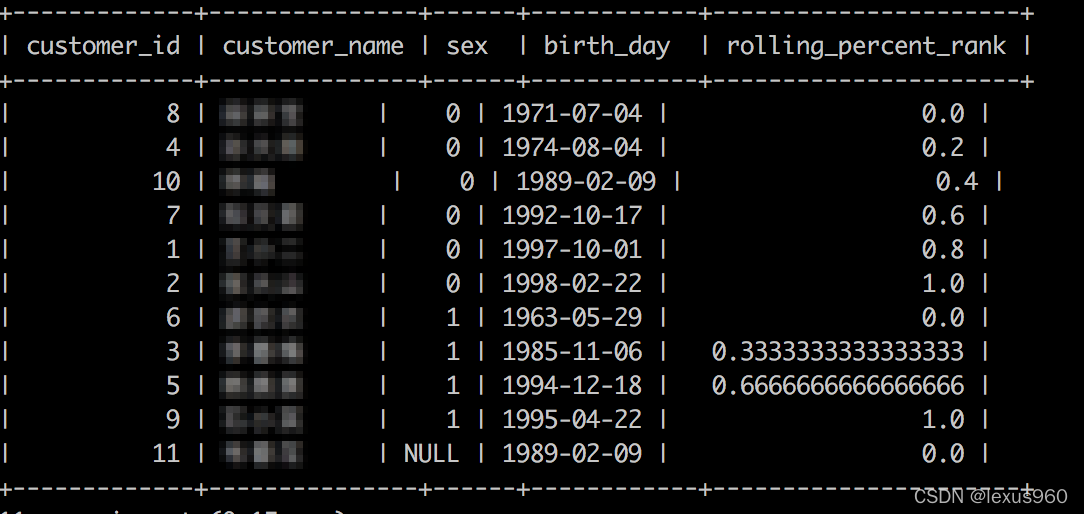
percent_rank() → bigint
返回数据集中每个数据的排名百分比。结果是根据 (r - 1) / (n - 1) 计算的,其中 r 是由 rank() 计算 的当前行排名, n 是当前窗口分区内总的行数。
SELECT customer_id,customer_name,sex,birth_day,
percent_rank()OVER(PARTITIONBY sex ORDERBY birth_day)AS rolling_percent_rank
FROM t_fact_customers;
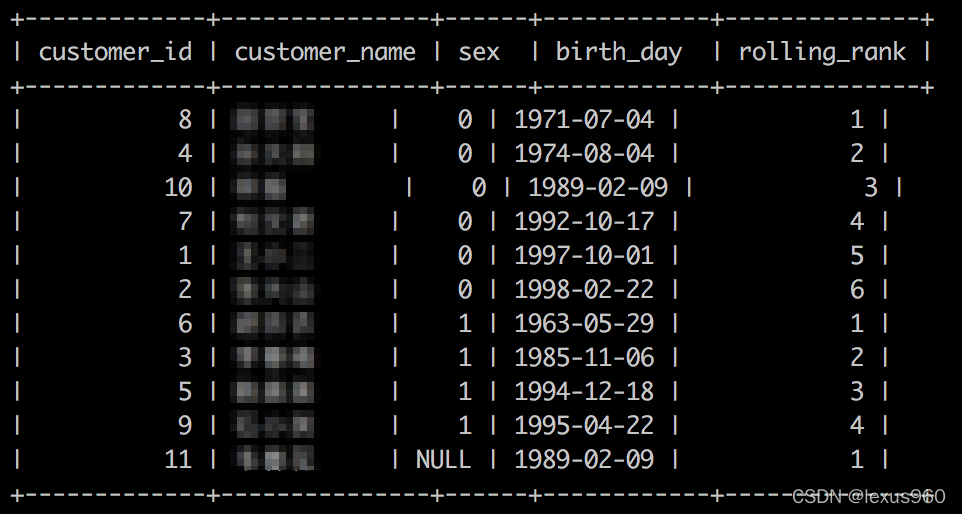
rank() → bigint
返回数据集中每个值的排名。排名值是根据当前行之前的行数加1,不包含当前行,因此排序的关联值可能产生顺序上的空隙。 rank() 排名会对每个窗口分区进行计算。
SELECT customer_id,customer_name,sex,birth_day,
rank() OVER (PARTITION BY sex ORDER BY birth_day) AS rolling_rank
FROM t_fact_customers;
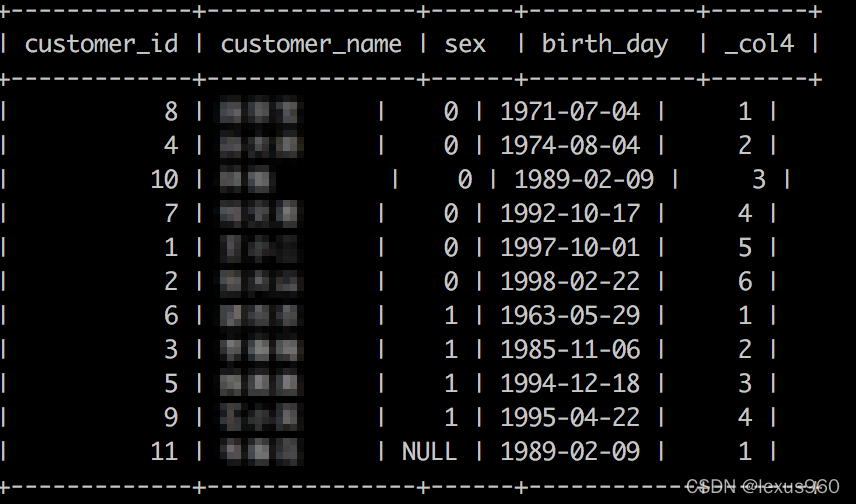
row_number() → bigint
根据行在窗口分区内的顺序,为每行数据返回一个唯一的顺序的行号,从1开始。
SELECT customer_id,customer_name,sex,birth_day,
row_number()OVER(PARTITIONBY sex ORDERBY birth_day)FROM t_fact_customers;
值函数
first_value(x) → [与输入类型相同]
返回窗口内的第一个值。
SELECT customer_id,customer_name,sex,birth_day,
first_value(customer_id) OVER (PARTITION BY sex ORDER BY birth_day)
FROM t_fact_customers;
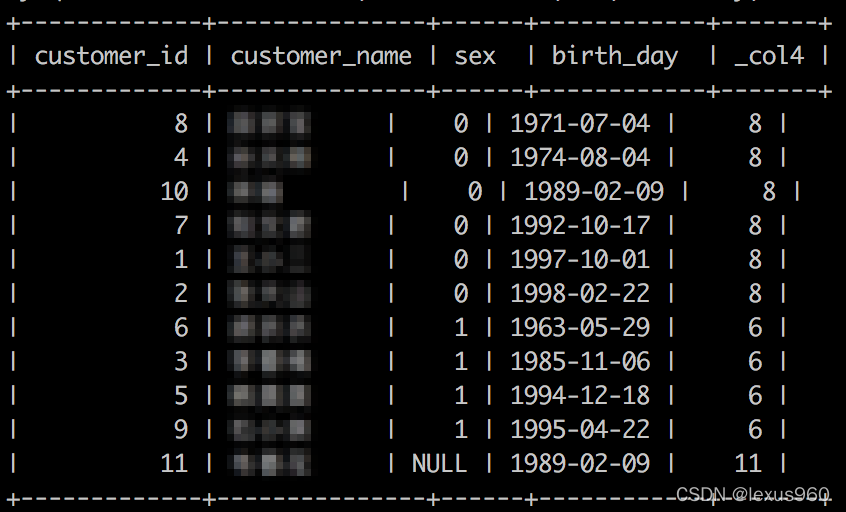
last_value(x) → [与输入类型相同]
返回窗口内的最后一个值。
SELECT customer_id,customer_name,sex,birth_day,
last_value(customer_id) OVER (PARTITION BY sex ORDER BY birth_day)
FROM t_fact_customers;
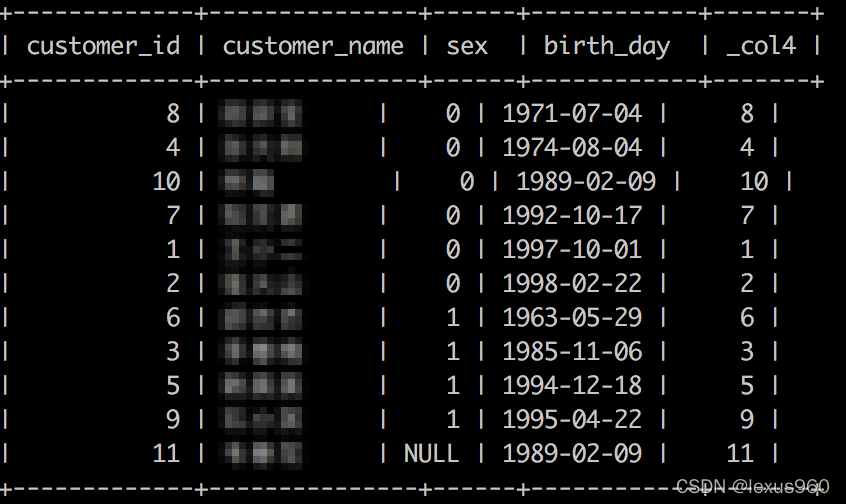
nth_value(x, offset) → [与输入类型相同]
返回窗口内指定偏移的值。偏移量从 1 开始。如果偏移量是null或者大于窗口内值的个数,返回null。 如果偏移量为0或者负数,则会报错。
SELECT customer_id,customer_name,sex,birth_day,
nth_value(customer_id,2) OVER (PARTITION BY sex ORDER BY birth_day)
FROM t_fact_customers;
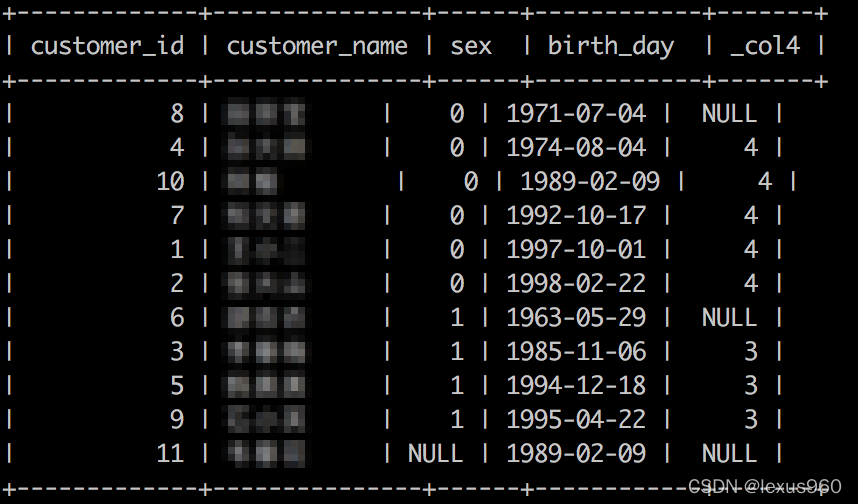
lead(x[, offset[, default_value]]) → [与输入类型相同]
返回窗口内当前行往后偏移 offset 的值。偏移量可以是标量表达式,起始值是0(即当前数据行),默认是1 。如果偏移量的值是 null 或者大于窗口长度,则返回 default_value;如果没有指定偏移量,则会返回 null 。
SELECT customer_id,customer_name,sex,birth_day,
lead(customer_id) OVER (PARTITION BY sex ORDER BY birth_day)
FROM t_fact_customers;
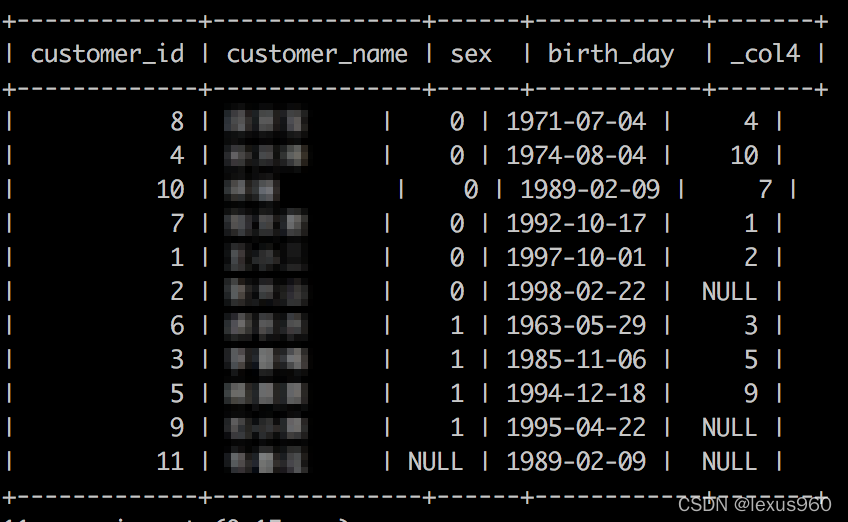
lag(x[, offset[, default_value]]) → [与输入类型相同]
返回窗口内当前行往前偏移 offset 的值。偏移量可以是标量表达式,起始值是0(即当前数据行),默认是1 。如果偏移量的值是null或者大于窗口长度,则返回 default_value;如果没有指定偏移量,则返回 null 。
SELECT customer_id,customer_name,sex,birth_day,
lag(customer_id)OVER(PARTITIONBY sex ORDERBY birth_day)FROM t_fact_customers;