数据库模型的分类

概念数据模型实体之间的3种联系

基本数据模型3大组成部分

常用的四种基本数据模型

层次模型
- 方式:使用树形结构表示实体类型以及实体之间的联系。
- 优点:记录之间的联系通过指针实现,查询效率高。
- 缺点:只能表示1:n联系。虽然有多种辅助手段实现m:n联系,但是比较复杂, 用户不易掌握。
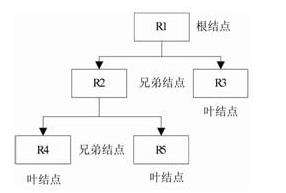
网状模型
- 方式:用有向图表示实体类型以及实体之间的联系。他去掉了层次模型的两个限制,允许多个节点没有双亲节点,允许节点有多个双 亲节点。此外他还允许节点之间有多种联系。层次模型实际上是网状模型的一个特例。
- 优点:记录之间的联系通过指针实现,m:n的联系也容易实现,查询效率高。
- 缺点:编写应用程序比较复杂,程序员必须熟悉数据库的逻辑结构。
关系模型
- 方式:用表格结构表达实体集,用外键表示实体之间的联系。关系模型在用户看来是一个二维表格。
- 优点:
- 建立在严格的数学概念基础上;
- 概念单一,结构简单、清晰,用户易懂易用;
- 存叏路徂对用户透明,从而数据独立性、安全性好,简化数据库开収工作。
- 缺点:由于存叏路徂透明,查询效率往往丌如非关系数据模型。
面向对象模型
- 方式:采用面向对象的方法来设计数据库,存储对象是以对象为单位,每个对象包含对象的属性和方法,具有类和继承等特点。
- 优点:
- 支持对象模型,体现了面向对象数据库的基本特征。
- 扩充了关系数据库的数据类型,支持用户自定义数据类型。
- 缺点:
- 复杂属性只能拆分成为并列的单一属性;
- 无法表示变长的属性
关系模型的几个概念
- 域:一组具有相同数据类型的值的集合。
- 笛卡尔积:域上面的一种集合运算。
给定一组域D1,D2,…,Dn,其中可以有相同的域。 D1,D2,…,Dn的乘积为: D1×D2×…×Dn={(d1,d2,…,dn)|dj ∈Dj,j=1,2,…,n}其
中每一个元素(d1,d2,…,dn)叫做一个n元组(简称为元组)。元组中的每一个值dj叫做一个分量
关系R
- 关系: D1×D2×…×Dn的子集叫做在域D1,D2,…,Dn上的关系,表示为:R(D1,D2,…,Dn)。这里的R表示关系的名字,n是关系的目或度。
- 关系中的每个元素是关系中的元组,通常用t表示。
- 关系是笛卡尔积的子集,所以关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域。由于域可以相同,为了加以区分,必须为每列起一个名字,称为属性。
- 若关系中的某一属性组的值能唯一地标识一个元组,则称该属性为候选码(候选键)。若一个关系有多个候选码,则选定其中一个为主码(主键)。
- 主码的诸属性称为主属性。丌包含在任何候选码中的属性称为非码属性(非主属性)。
- 在最简单的情况下,候选码只包含一个属性;在极端情况下,关系模式的所有属性组是这个关系模式的候选码,称为全码。
基本关系的3种类型

基本关系的6个性质
1、列是同质的:即每一列中的分量是同一类型的数据,来自同一个域。
2、丌同的列可出自同一个域,其中的每一列称为一个属性,不同的属性要给予不同的属性名。
3、列的顺序无所谓:即列的次序可以任意交换。
4、任意两个元组不能完全相同。
5、行的顺序无所谓:即行的次序可以任意交换。
6、分量必须取原子值:即每一个分量都必须是不可分的数据项。
关系模式
- 定义:关系的描述称为关系模式。
- 形式表示:一个关系模式是一个五元组,表示为R(U,D,DOM,F)。
- R为关系名;
- U为组成该关系的属性名集合;
- D为属性组U中属性所来自的域;
- DOM为属性向域的映像集合;
- F为属性间数据的依赖关系的集合。
- 关系模式通常可以简记为:R(A1,A2,…,An),其中R为关系名,A1,A2,…,An为属性名。
版权声明:本文为python_jeff原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。