目录
编程的模型
编程的主要是用以下三步来写
- data source
获取数据的来源例如基于集合中,文件,socket,MySQL - transforations
对获取到的数据进行相关的规则计算 - sink
将处理好的数据输出或者保存
Source
基于集合的Source
env.fromElements():元素


env.fromCollection():集合

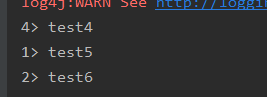
env.generateSequence():产生序列


env.fromSequence():来自于序列

全代码
package datastream;
/**
* @author 公羽
* date 2021/7/3
*/
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class source_set {
public static void main(String[] args) throws Exception {
// 1.环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 流处理模式
// 2.source
// env.formElements() 元素
DataStream<String> ds1 = env.fromElements("test1","test2","test3");
// env.fromcollection 集合
DataStream<String> ds2 = env.fromCollection(Arrays.asList("test4","test5","test6"));
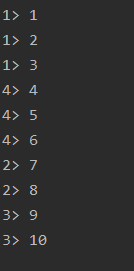
// env.generateSequence() 产生序列 已经放弃的用法
DataStream<Long> ds3 = env.generateSequence(1,10);
// env.fromSequence() 来自序列
DataStream<Long> ds4 = env.fromSequence(1,10);
// 3.transformation
// 4.sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
// 5.执行
env.execute();
}
}
基于文件的Source
- env.readTextFile(本地/hdfs文件/文件夹/压缩包)
在pom.xml文件中加入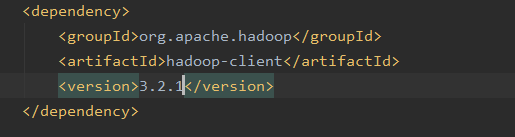
要是想要读取hdfs上的数据需要把hadoop的配置文件hdfs-site.xml和core-site.xml下载复制到项目resource是文件下
- 本地

- 本地文件夹

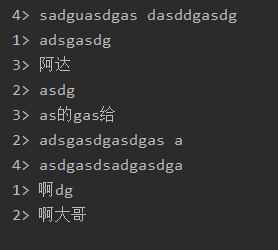
- hdfs


- 压缩包

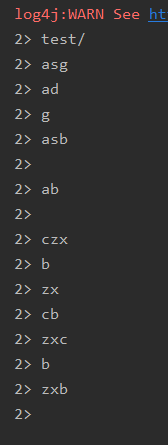
全代码
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 公羽
* date 2021/7/3
*/
public class source_file {
public static void main(String[] args) throws Exception {
// 1.环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 流处理模式
// 2.source
// 读取单个文件
DataStream<String> ds1 = env.readTextFile("E:\\input\\test.txt");
// 读取文件夹
DataStream<String> ds2 = env.readTextFile("E:\\input");
// 读取hdfs上单个文件
DataStream<String> ds3 = env.readTextFile("hdfs://spark01:9000/test/test.txt");
// 读取压缩包
DataStream<String> ds4 = env.readTextFile("hdfs://spark01:9000/test/test.gz");
// 3.transformation
// 4.sink
// ds1.print();
// ds2.print();
// ds3.print();
ds4.print();
// 5.executor
env.execute();
}
//
}
基于socket的Source
监听9999端口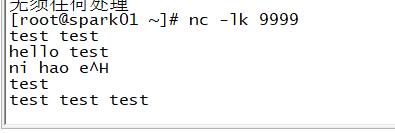
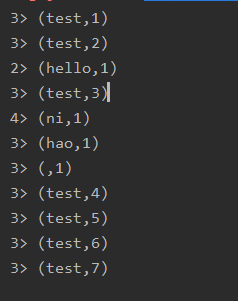
全代码
package datastream;
import javafx.util.converter.DateStringConverter;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Date;
/**
* @author 公羽
* date 2021/7/3
*/
public class source_socket {
public static void main(String[] args) throws Exception {
// 1.环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 流处理模式
// 2.source
DataStream<String> ds1 = env.socketTextStream("spark01",9999);
// 3.transformation
DataStream<String> ds2 = ds1.flatMap(new FlatMapFunction<String, String>() {
@Override
// 重写map方法
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] words = s.split(" ");//按照" "切词
for (String word : words){
collector.collect(word);
}
}
});
DataStream<Tuple2<String, Integer>> ds3 = ds2.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
// 重写reduce方法
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s,1);//组成二元组的形式
}
});
// 按照key结合进行统计
KeyedStream<Tuple2<String,Integer>, String > ds4 = ds3.keyBy(t -> t.f0);
DataStream<Tuple2<String,Integer>> ds5 = ds4.sum(1);
// 4.sink
ds5.print();
// 5.execute
env.execute();
}
}
自定义source–MySQL
安装插件Lombok
添加依赖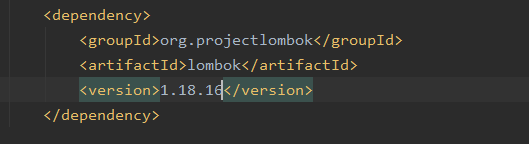
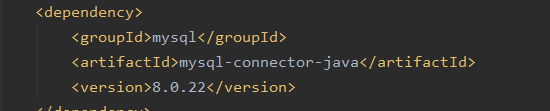
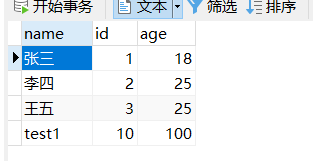
数据库中的数据
创建学生实体类
package datastream;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 公羽
* date 2021/7/3
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class student {
private Integer id;
private String name;
private Integer age;
}
创建自定义来源类
package datastream;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.concurrent.TimeUnit;
public class source_mysql extends RichParallelSourceFunction<student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
private boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf-8&serverTimezone=UTC","root","123456");
String sql = "select * from test_flink";
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void run(SourceContext sourceContext) throws Exception {
while (flag) {
ResultSet rs = preparedStatement.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
sourceContext.collect(new student(id,name,age));
}
TimeUnit.SECONDS.sleep(5);
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
super.close();
preparedStatement.close();
connection.close();
}
}
编写主类
package datastream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 公羽
* date 2021/7/3
*/
public class driver_mysql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<student> ds = env.addSource(new source_mysql()).setParallelism(1);
ds.print();
env.execute();
}
}

Transformation
基本操作
flatmap
将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
- map
将函数作用在集合的每一个元素上,并返回作用后的结果 - keyBy
按照指定的key对流中的数据进行分组,注意流处理中没有groupBy,而是keyBy - filter
按照指定的条件对集合中的元素进行过滤,返回符合条件的元素 - sum
按照指定的字段对集合中的元素进行求和 - reduce
对集合中的元素进行聚合
案列
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author 公羽
* date 2021/7/4
*/
public class trans_basic {
public static void main(String args[]) throws Exception {
//1、准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动选择处理模式
//2、准备数据-source
DataStream<String> lineDS = env.fromElements("spark heihei sqoop hadoop","spark flink","hadoop fink heihei spark");
//3、处理数据-transformation
//3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
//s就是一行行的数据,再将每一行分割为一个个的单词
String[] words = s.split(" ");
for (String word : words) {
//将切割的单词收集起来并返回
collector.collect(word);
}
}
});
//3.1.5 对数据进行敏感词过滤
DataStream<String> filterDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return !s.equals("heihei");
}
});
//3.2 对集合中的每个单词记为1
DataStream<Tuple2<String,Integer>> wordAndOnesDS = filterDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
//s就是进来的一个个单词,再跟1组成一个二元组
return Tuple2.of(s,1);
}
});
//3.3 对数据按照key进行分组
KeyedStream<Tuple2<String,Integer>,String> groupedDS = wordAndOnesDS.keyBy(t->t.f0);
//3.4 对各个组内的数据按照value进行聚合也就是求sum
DataStream<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5 对结果聚合
DataStream<Tuple2<String,Integer>> redResult = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t2, Tuple2<String, Integer> t1) throws Exception {
return Tuple2.of(t2.f0,t2.f1 + t2.f1);
}
});
//4、输出结果-sink
aggResult.print();
redResult.print();
// 5、触发执行-execute
//说明:如果有print那么Dataset不需要调用execute,DataStream需要调用execute
env.execute();
}
}
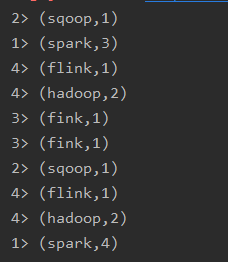
合并和拆分
合并
- union和connect
union合并多个同类型的数据流,并生成一个同类型的新的数据流,connect连接两个数据流,这两个数据流可以是不同的类型
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Arrays;
/**
* @author 公羽
* date 2021/7/4
*/
public class trans_con {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream<String> dataStreamSource = env.fromElements("test1", "test2", "test3");
DataStream<String> stringDataStreamSource = env.fromCollection(Arrays.asList("test4", "test5", "test6"));
DataStream<Long> longDataStreamSource = env.generateSequence(1, 10);
DataStream<Long> longDataStreamSource1 = env.fromSequence(1, 10);
DataStream<String> union = dataStreamSource.union(stringDataStreamSource);
ConnectedStreams<String, Long> connect = dataStreamSource.connect(longDataStreamSource);
DataStream<String> map = connect.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String s) throws Exception {
return "String -> String" +" "+ s;
}
@Override
public String map2(Long aLong) throws Exception {
return "Long -> String" + " " + aLong.toString();
}
});
// union.print();
map.print();
env.execute();
}
}
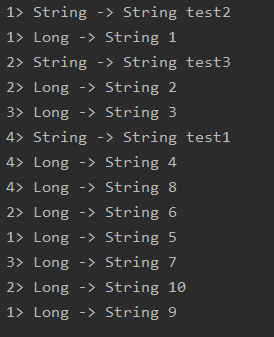
拆分
- Side Outputs
Side Outputs可以使用process方法对流中的数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* @author 公羽
* date 2021/7/4
*/
public class trans_split {
public static void main(String[] args) throws Exception {
// 环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<Integer> integerDataStreamSource = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9);
// transformation
// 拆分
// 定义标签
OutputTag<Integer> tag1 = new OutputTag<Integer>("偶数", TypeInformation.of(Integer.class));
OutputTag<Integer> tag2 = new OutputTag<>("奇数", TypeInformation.of(Integer.class));
SingleOutputStreamOperator<Integer> process = integerDataStreamSource.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer integer, Context context, Collector<Integer> collector) throws Exception {
if (integer % 2 == 0){
context.output(tag1,integer);
}else {
context.output(tag2,integer);
}
}
});
// 取出标签
DataStream<Integer> sideOutput = process.getSideOutput(tag1);
DataStream<Integer> sideOutput1 = process.getSideOutput(tag2);
// sink
sideOutput.print();
sideOutput1.print();
// execute
env.execute();
}
}
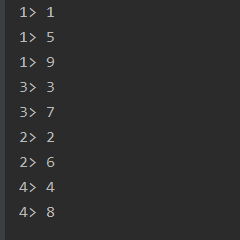
分区
- rebalance重平衡分区
解决数据倾斜,数据倾斜指的是大量的数据集中于一台节点上,而其他节点的负载较轻
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 公羽
* date 2021/7/4
*/
public class trans_para {
public static void main(String[] args) throws Exception {
// 环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<Long> longDataStreamSource = env.fromSequence(1, 10000);
// transformation
// 将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filter = longDataStreamSource.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return aLong > 10;
}
});
// 直接处理,有可能出现数据倾斜
DataStream<Tuple2<Integer, Integer>> map = filter.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id,1);
}
}).keyBy(t -> t.f0).sum(1);
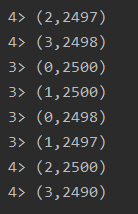
//在数据输出前进行了rebalance重平衡分区,解决数据的倾斜
DataStream<Tuple2<Integer, Integer>> map1 = filter.rebalance().map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id,1);
}
}).keyBy(t -> t.f0).sum(1);
// sink
map.print();
map1.print();
// execute
env.execute();
}
}
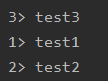
sink
预定义Sink
ds.print():直接输出到控制台

ds.printToErr():直接输出到控制台,用红色

- ds.writeAsText(“本地/HDFS”,WriteMode.OVERWRITE).setParallelism(n):输出到本地或者hdfs上,如果n=1,则输出为文件名,如果n>1,则输出为文件夹



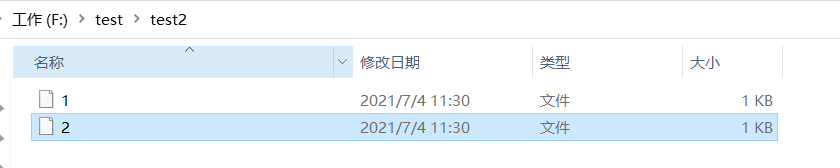
全代码
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 公羽
* date 2021/7/4
*/
public class sink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
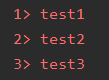
DataStream<String> ds = env.fromElements("test1", "test2", "test3");
// sink
// ds.print();
// ds.printToErr();
// ds.writeAsText("f:/test/test1").setParallelism(1);
ds.writeAsText("f:/test/test2").setParallelism(2);
env.execute();
}
}
自定义Sink
将数据存入MySQL中
定义sink类
package datastream;
import datastream.student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* @author 公羽
* date 2021/7/4
*/
public class sink_mysql extends RichSinkFunction<student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
@Override
public void open(Configuration parameters) throws Exception {
//调用父类的构造方法,可删除
super.open(parameters);
//加载mysql驱动,建立连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf-8&serverTimezone=UTC","root","123456");
String sql = "insert into test_flink(name,id,age) values(?,?,?)";
//建立Statement
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void invoke(student value, Context context) throws Exception {
//给ps中的?设置具体的值
preparedStatement.setString(1,value.getName());//获取姓名
preparedStatement.setInt(2,value.getId());//获取id
preparedStatement.setInt(3,value.getAge());//获取年龄
//执行sql
preparedStatement.executeUpdate();
}
@Override
public void close() throws Exception {
super.close();
preparedStatement.close();
connection.close();
}
}
定义sink主类
package datastream;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 公羽
* date 2021/7/4
*/
public class sink_driver {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStream<student> test1 = env.fromElements(new student(10,"test1",100));
test1.addSink(new sink_mysql());
env.execute();
}
}
版权声明:本文为qq_43659234原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。