>>>本篇参考Pytorch官方所给教程,进一步对其进行细化 <<<
> ①保存网络的结构图:在Tensorboard的GRAPHS当中,会有模型的结构图,可以比较清晰的看出整个模型搭建的每个模块。
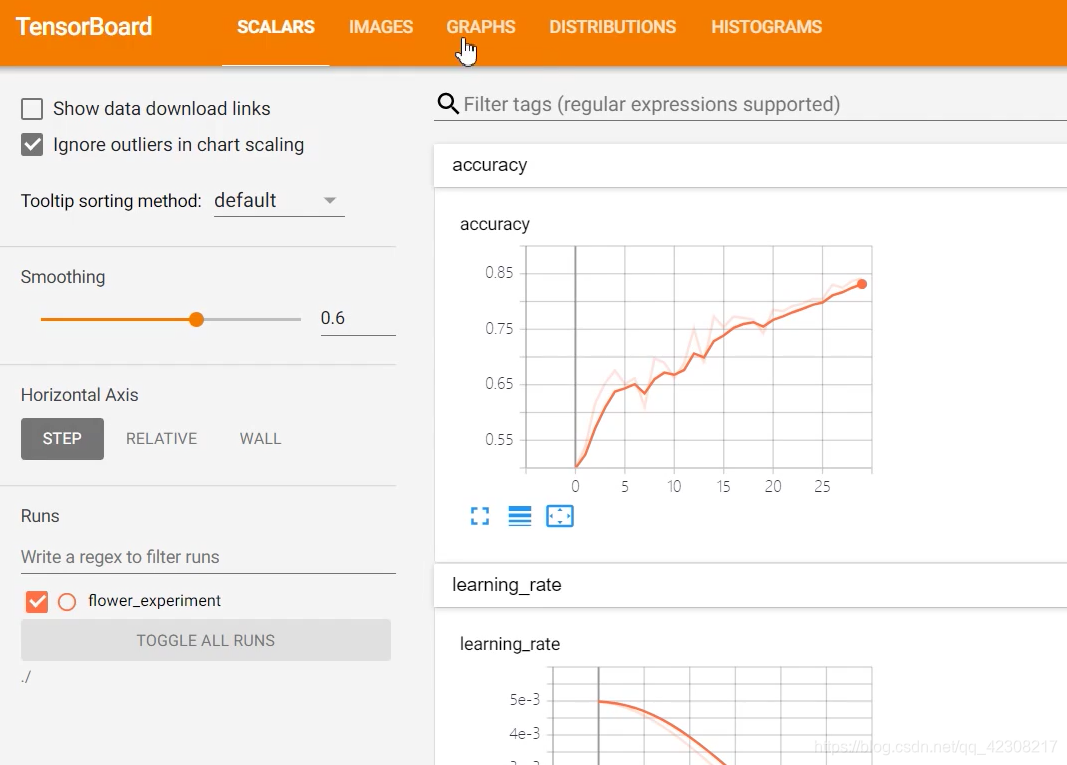
> ②保存training_loss、验证集的acc以及learning_rate的变化,在Tensorboard的SCALARS当中。
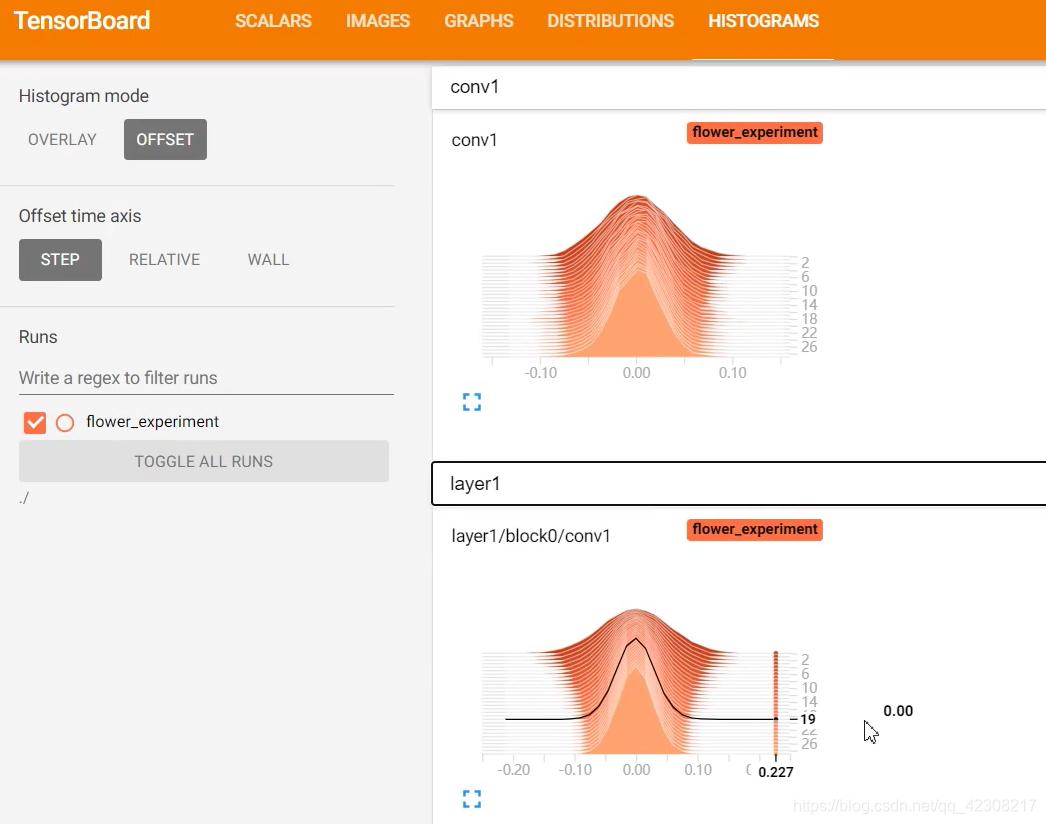
> ③查看每一个层结构权重数值的分布,在Tensorboard的HISTOGRAMS当中。
> ④保存预测图片的一些信息,在Tensorboard的IMAGES当中,保存有给定的一些图片每个step的预测结果
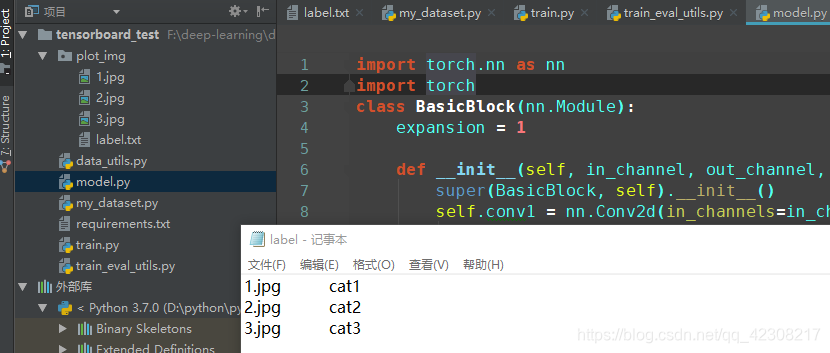
首先进入项目当中,需要创建一个文件夹,在其中所保存的图片等会在训练过程中会进行预测并将结果添加到tensorboard当中。除此之外,还需要准备一个label.txt文件,对应图片的标签,如下图所示:
-> ResNet预训练权重的下载方式:import torchvision.models.resnet ctrl+鼠标左键点击语句中的resnet即可下载自己想要的权重。但本次实验并不使用预训练权重,因为如果使用了预训练权重,就会发现acc和loss基本上是没有变化的,在训练的第一个epoch准确率就已经达到了97%
tensorboard语句分步说明:
tb_writer = SummaryWriter(log_dir="runs/experiment")
在实例化模型后还要创建一个0矩阵,为什么要去创建这个零矩阵?:因为添加网络结构图的时候需要其传入到模型中让它进行正向传播,根据这个矩阵在模型中正向传播的流程来创建网络结构图,所以只要这个矩阵和图片大小相同即可。
# 实例化模型
model = resnet34(num_classes=args.num_classes).to(device)
# 将模型写入tensorboard
init_img = torch.zeros((1, 3, 224, 224), device=device)#参数:模型输入tensor和使用训练的设备
tb_writer.add_graph(model, init_img)#利用模型和零矩阵创建网络的结构图
在每个epoch之后,即验证集代码执行完之后,会保存当前epoch训练集平均损失、验证集acc以及learning_rate。-------------注:tb_writer.add_scalar方法的使用:第一个参数传入的是标签;第二个参数是在训练过程中统计得到的数据,这里的值不是tensor,而是浮点类型的数据;第三个参数是当前训练到了哪一步。tb_writer.add_figure方法的使用:添加指定图片的预测结果将其绘制成一个图片,保存到tensorboard中,参数一是绘制图片的标题,参数二是fig对象,第三个参数是当前训练到了哪一步。
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# update learning rate
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
# add loss, acc and lr into tensorboard
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["train_loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
# add figure into tensorboard
fig = plot_class_preds(net=model,
images_dir="./plot_img",
transform=data_transform["val"],
num_plot=5,
device=device)
if fig is not None:
tb_writer.add_figure("predictions vs. actuals",
figure=fig,
global_step=epoch)
# add conv1 weights into tensorboard
tb_writer.add_histogram(tag="conv1",
values=model.conv1.weight,
global_step=epoch)
tb_writer.add_histogram(tag="layer1/block0/conv1",
values=model.layer1[0].conv1.weight,
global_step=epoch)
plot_class_preds(net,
images_dir: str,
transform,
num_plot: int = 5,
device="cpu"):
if not os.path.exists(images_dir):
print("not found {} path, ignore add figure.".format(images_dir))
return None
label_path = os.path.join(images_dir, "label.txt")
if not os.path.exists(label_path):
print("not found {} file, ignore add figure".format(label_path))
return None
# read class_indict
json_label_path = './class_indices.json'
assert os.path.exists(json_label_path), "not found {}".format(json_label_path)
json_file = open(json_label_path, 'r')
# {"0": "daisy"}
flower_class = json.load(json_file)
# {"daisy": "0"}
class_indices = dict((v, k) for k, v in flower_class.items())
# reading label.txt file
label_info = []
with open(label_path, "r") as rd:
for line in rd.readlines():
line = line.strip()
if len(line) > 0:
split_info = [i for i in line.split(" ") if len(i) > 0]
assert len(split_info) == 2, "label format error, expect file_name and class_name"
image_name, class_name = split_info
image_path = os.path.join(images_dir, image_name)
# 如果文件不存在,则跳过
if not os.path.exists(image_path):
print("not found {}, skip.".format(image_path))
continue
# 如果读取的类别不在给定的类别内,则跳过
if class_name not in class_indices.keys():
print("unrecognized category {}, skip".format(class_name))
continue
label_info.append([image_path, class_name])
if len(label_info) == 0:
return None
# get first num_plot info
if len(label_info) > num_plot:
label_info = label_info[:num_plot]
num_imgs = len(label_info)
images = []
labels = []
for img_path, class_name in label_info:
# read img
img = Image.open(img_path).convert("RGB")
label_index = int(class_indices[class_name])
# preprocessing
img = transform(img)
images.append(img)
labels.append(label_index)
# batching images
images = torch.stack(images, dim=0).to(device)
# inference
with torch.no_grad():
output = net(images)
probs, preds = torch.max(torch.softmax(output, dim=1), dim=1)
probs = probs.cpu().numpy()
preds = preds.cpu().numpy()
# width, height
fig = plt.figure(figsize=(num_imgs * 2.5, 3), dpi=100)
for i in range(num_imgs):
# 1:子图共1行,num_imgs:子图共num_imgs列,当前绘制第i+1个子图
ax = fig.add_subplot(1, num_imgs, i+1, xticks=[], yticks=[])
# CHW -> HWC
npimg = images[i].cpu().numpy().transpose(1, 2, 0)
# 将图像还原至标准化之前
# mean:[0.485, 0.456, 0.406], std:[0.229, 0.224, 0.225]
npimg = (npimg * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
plt.imshow(npimg.astype('uint8'))
title = "{}, {:.2f}%\n(label: {})".format(
flower_class[str(preds[i])], # predict class
probs[i] * 100, # predict probability
flower_class[str(labels[i])] # true class
)
ax.set_title(title, color=("green" if preds[i] == labels[i] else "red"))
return fig
版权声明:本文为qq_42308217原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。