every blog every motto: There’s only one corner of the universe you can be sure of improving, and that’s your own self.
https://blog.csdn.net/weixin_39190382?spm=1010.2135.3001.5343
0. 前言
梳理yolo v2
bbd: 没耐心仔细看了,摔,
1. 正文
时间: 2016
论文: https://arxiv.org/abs/1612.08242
代码: https://github.com/pjreddie/darknet
作者: Joseph Redmon∗† , Ali Farhadi∗†
作者单位: University of Washington , Allen Institute for AI
1. 正文
总览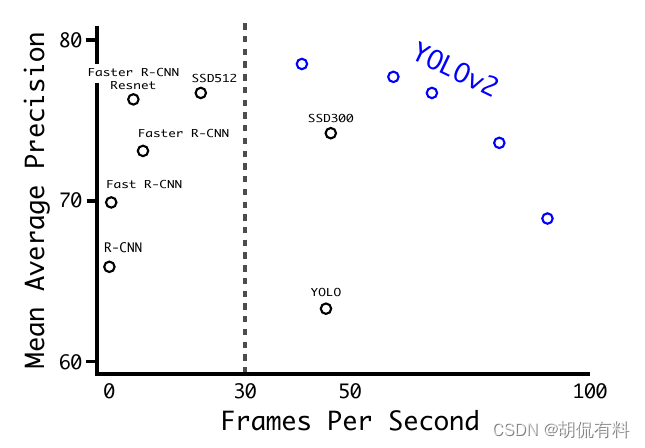
1.1 改进点
改进点主要有: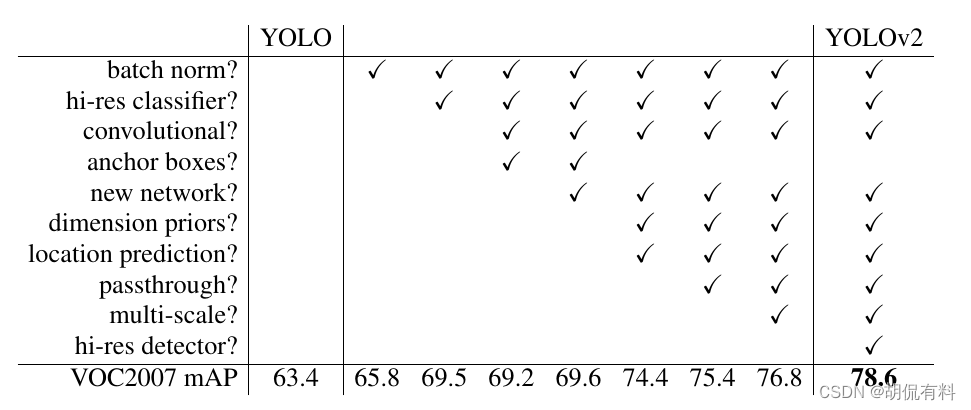
1. Better
1.1 BN
卷积层后添加Batch Normalization层,去掉原有的dropout层,涨点约2%mAP
1.2. High Resolution
先在ImageNet上以224×224训练,再调整图片大小为448×448finetune10个eopchs涨点约4%mAP
1.3. Anchor Boxes
v1中使用全连接层对边框进行预测,导致信息丢失,定位不准。v2中去掉了全连接层,使用了anchor boxs,同时,为了得到更高分辨率的特征图,去掉了一个池化。最终是网络输入为416 × 416,网络进行32倍下采样,最后得到13 × 13 的特征图,每个cell预测5个anchor box,一共可以预测13×13×5 = 845个框。召回率有81%提高到88%,mAP有69.5%降到69.2%。即,
召回率提升7%,准确率下降了0.3%。
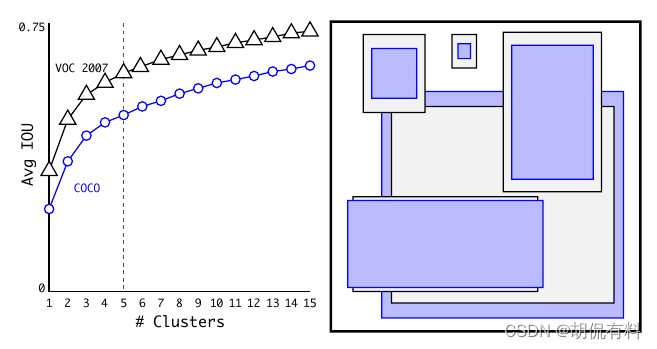
1.4. Dimension Clusters
在Faster R-CNN中,anchor box是先验手动产生的 ,v2中采用k-means对训练数据的边界框进行聚类,选用boxes之间的IoU作为聚类指标。选取了5个聚类中心,得到5个先验框。
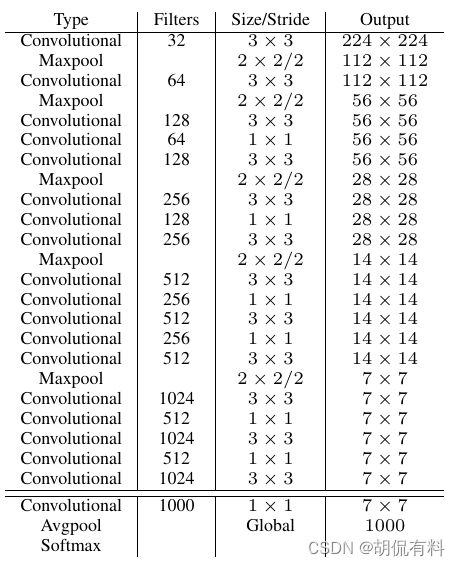
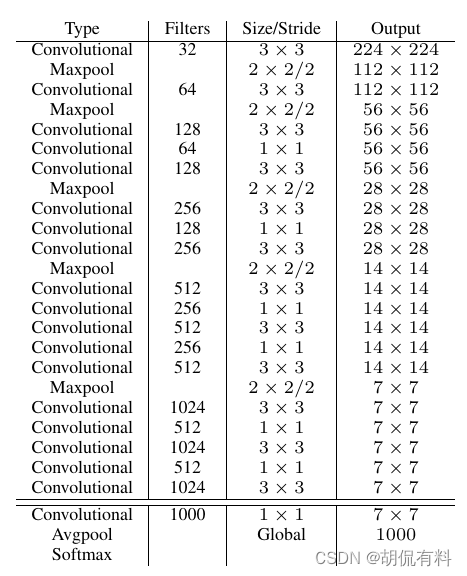
1.5. Darknet-19
使用了新的模型结构,包含19个卷积和5个maxpooling层。主要采用3×3的卷积,2×2的maxpooling。并且在3×3卷积之间使用1×1卷积来压缩特征图的通道降低模型计算量和参数。
mPA没有显著提升,但是计算量可以减小约33%
1.6. 直接预测位置
在yolo v2 中借鉴了Faster R-CNN中的Anchor box,在Faster R-CNN中是预测边框的四个坐标值的偏移量(如下图所示),由于没有对偏移量进行约束,每个位置预测的边界框可以落在图片的任何位置,会导致模型不稳定,加长训练时间。 yolo v2 沿用了v1的方法,预测相对“格子”(“格子”就是最后网络输出特征图的像素)的值,其值介于0和1之间。网络中让网络预测的结果输入sigmoid,这样值就介于0和1之间。

与 v1 类似,我们对框一共预测了四个值,分别是,框的中心点坐标x,y,以及框的长宽 w,h。为了使模型更稳定,使用了sigmoid将值约束到0和1之间。
预测框中心相对与所在“格子”的坐标σ ( t x ) \sigma(t_x)σ(tx)和σ ( t y ) \sigma(t_y)σ(ty),再加上当前格子相对整个格子左上角的坐标c x c_xcx和c y c_ycy就能确定预测框相当于整个格子的坐标:
b x = σ ( x ) + c x b_x = \sigma(x) + c_xbx=σ(x)+cx
b y = σ ( y ) + c y b_y = \sigma(y) + c_yby=σ(y)+cy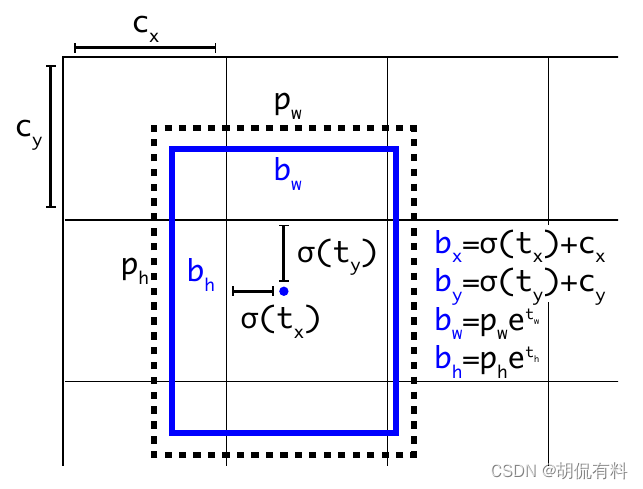
1.7. Fine-Grained Features
如图,不同分辨率的特征图在通道方向上合并,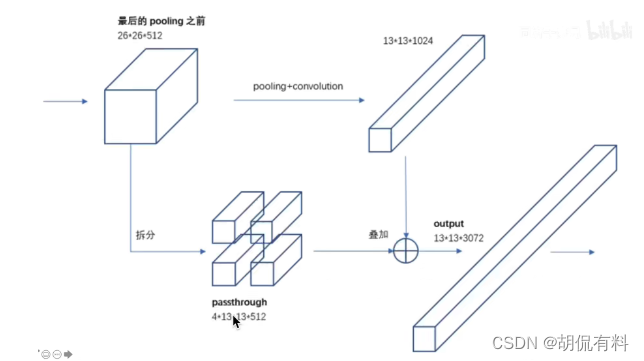
1.8. 多尺度训练
为了增强模型的鲁棒性,采用多尺度输入训练策略。具体说就是每迭代10次更改输入图片大小。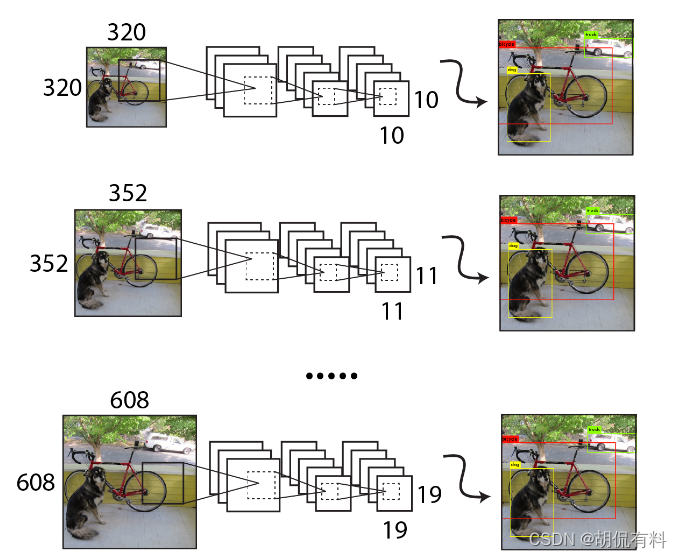
2. Faster
2.1 Darknet-19
2.2 Training for classification
我们首先在ImageNet数据集上训练160个epochs,其中在训练期间使用的数据增强方式有:随机裁剪、旋转以及色度,饱和度和对比度的调整。
然后我们在对网络初步训练后,微调了我们的网络,采用了448x448作为输入,训练10个epochs
2.3 Training for detection
将网络转换为进行检测,我们删除最后一个卷积层,然后添加3个3x3的卷积层,每个卷积层有1024个filter,而且每个后面跟着一个1x1卷积层,其filter的个数由需要检测的类别数来确定
参考
[1] https://www.cnblogs.com/limbercode/p/16154869.html#_label0
[2] https://blog.51cto.com/u_15490502/5219745
[3] https://www.jianshu.com/p/87645a11b510
[4] https://blog.csdn.net/qq_38375203/article/details/125502438
[5] https://blog.csdn.net/weixin_43694096/article/details/123523679
[6] https://zhuanlan.zhihu.com/p/366370644
[7] https://baijiahao.baidu.com/s?id=1717730887250972083&wfr=spider&for=pc
[8] http://www.qb5200.com/article/391620.html
[9] https://blog.csdn.net/m0_37940804/article/details/116244606
[10] https://blog.csdn.net/qq_42735631/article/details/121456856
[11] https://www.captainai.net/diffie/
[12] https://blog.csdn.net/weixin_39190382/article/details/125945387?spm=1001.2014.3001.5501