redis中其他几种数据类型:
【List类型使用及底层结构】
【String类型使用及底层结构】
【set类型使用及底层结构】
【Zset类型使用及底层结构】
一、基本使用
由于hash也是存储key-value,map类型的数据,所以在redis中,value表示hash这个集合。
127.0.0.1:6379> hset myhash key1 value1 #myhash是redis中的key,key1和value1是redis中的value
(integer) 1 #key1是hash中的key,value1是hash中的value
127.0.0.1:6379> hget myhash key1
"value1"
127.0.0.1:6379> hmset myhash key2 value2 key3 value3
OK
127.0.0.1:6379> hmget myhash key2 key3
1) "value2"
2) "value3"
127.0.0.1:6379> hgetall myhash #hgetall获取全部的键值对
1) "key1"
2) "value1"
3) "key2"
4) "value2"
5) "key3"
6) "value3"
#删除某一个键值对 hdel
127.0.0.1:6379> hdel myhash key3 #指定key,对应的value也会删除
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "key1"
2) "value1"
3) "key2"
4) "value2"
#获取长度,有多少个键值对 hlen
127.0.0.1:6379> hlen myhash
(integer) 2
#判断指定字段是否存在 hexists
127.0.0.1:6379> hexists myhash key1
(integer) 1
#只获得所有的key hkeys
#只获得所有的value hvals
127.0.0.1:6379> hkeys myhash
1) "key1"
2) "key2"
127.0.0.1:6379> hvals myhash
1) "value1"
2) "value2"
127.0.0.1:6379>
#增加/减小指定的步长 hincrby/hdecrby
127.0.0.1:6379> hset myhash key3 5
(integer) 1
127.0.0.1:6379> hincrby myhash key3 1
(integer) 6
127.0.0.1:6379> hget myhash key3
"6"
127.0.0.1:6379>
#如果存在/不存在进行设置 hsetnx
127.0.0.1:6379> hsetnx myhash key4 hello #如果存在则可以设置
(integer) 1
127.0.0.1:6379> hsetnx myhash key4 hello1 #如果不存在则不可以设置
(integer) 0
127.0.0.1:6379>
二、底层结构
hash键的底层在redis3.0中式通过压缩列表和哈希表来实现的,在3.0以后式通过listpack和哈希表实现的。(为了避免文章过长,listpack的分析放在zset一节中)
1.压缩列表
压缩列表是一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。Redis 中,List 键、Hash 键、Zset 键的底层都用到了压缩列表。
- 结构设计
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,有点类似于数组。一个压缩列表可以包 含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整 数值。

zlbytes:记录整个压缩列表占用的内存字节数;
zltail:记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
zllen:记录压缩列表包含的节点数量;
zlend:标记压缩列表的结束点,固定值 0xFF(十进制255)。
eg.
(1)列表zlbytes属性的值为0x50(十进制80),表示压缩列表的总长。
(2)列表zltail属性的值为0x3c(十进制60),这表示如果我们有一个 指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量60,就可 以计算出表尾节点entry3的地址。
(3)列表zllen属性的值为0x3(十进制3),表示压缩列表包含三个节点。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
再来看一下**压缩列表中节点(entry)**的构成:
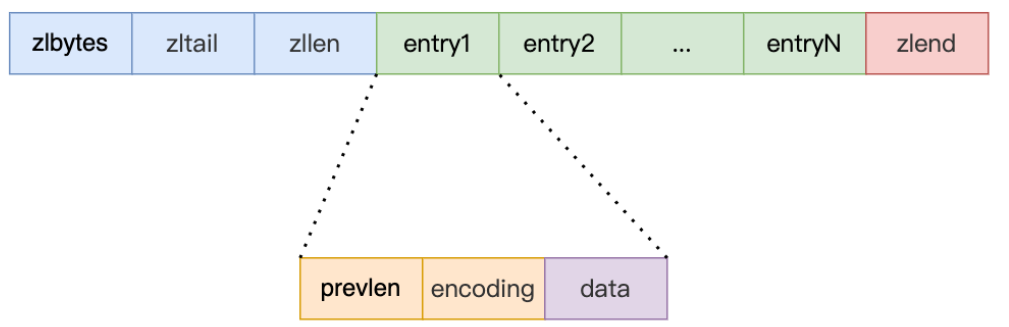
prevlen:记录了「前一个节点」的长度;
如果前一个节点的长度小于 254 字节,那么 prevlen 用 1 字节的空间来保存这个长度值;
如果前一个节点的长度大于等于254字节,那么 prevlen 用 5 字节的空间来保存这个长度值;
encoding:记录了当前节点实际数据的类型以及长度;
- 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码。
- 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码。
data:记录了当前节点的实际数据;
- 连锁更新问题
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
举个例子:在一个压缩列表中,有多个连续的、长度介于250到253字节之间的节点e1至eN

因为e1至eN的所有节点的长度都小于254字节,所以记录这些节点的长度只需要1字节长的prevlen属性。也就是说,e1至eN 的所有节点的prevlen属性都是1字节长的。
这时,如果我们将一个长度大于等于254字节的新节点new设置为压缩列表的表头节点,那么new将成为e1的前置节点。因为e1的prevlen属性仅长1字节,它没办法保存新节点new的长度,所以程序将对压缩列表执行空间重分配操作,并将e1节点的prevlen属性从原来的1字节长扩展为5字节长。

但是!e1原本的长度介于250字节至253字节之 间,在为prevlen属性新增四个字节的空间之后,e1的长度就变成了介于254字节至257字节之间,这就使得e2的prevlen属性无法再保存e1的长度!所以e2的prevlen属性也要进行扩展,e3、e4…eN都要跟着变化,导致性能下降!所以这再一次说明了压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。
2.哈希表
- 结构设计
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
哈希表是一个数组(dictEntry **table),数组的每个元素是指向哈希表节点(dictEntry)的指针。
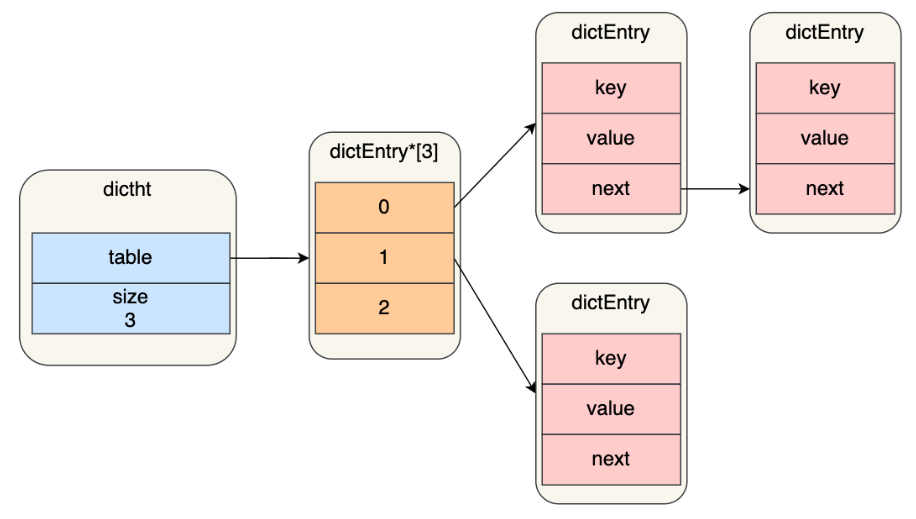
哈希表节点的结构:
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- hash冲突
Redis 采用了「链式哈希」的方法来解决哈希冲突。
实现的方式就是每个哈希表节点都有一个 next 指针,用于指向下一个哈希表节点,因此多个哈希表节点可以用 next 指针构成一个单项链表,被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来,这样就解决了哈希冲突。
不过,链式哈希局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O(n)。
- rehash
触发条件:
(1)当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
(2)当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
(负载因子=哈希表已保存节点数量/哈希表大小)
实际使用哈希表时,再Redis 定义的dict 结构体中,定义了两个哈希表(ht[2])。两个Hash表,交替使用,用于rehash操作。
typedef struct dict {
//
类型特定函数
dictType *type;
//
私有数据
void *privdata;
//
哈希表
dictht ht[2];
// rehash
索引
//
当rehash不再进行时,值为-1
in trehashidx;
} dict;
rehash步骤:
(1)给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
(2)将「哈希表 1 」的数据迁移到「哈希表 2」 中;
(3)迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求。所以redis采取了渐进式rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。
渐进式rehash步骤:
(1)给「哈希表 2」 分配空间;
(2)在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上
(3)随着处理客户端发起的哈希表操作请求数量越多,最终把数据全部迁移。
参考
[小林coding]
[redis的设计与实现]