在拿到开源的已标注好的 NER 数据集后,往往需要了解一下数据集标注的类型有哪些,标注的数量有多少,因为每个人研究的领域不同,标注类型也不同。
比如说已经获得了三个文件,train.txt,test.txt,valid.txt。
标注格式如下图: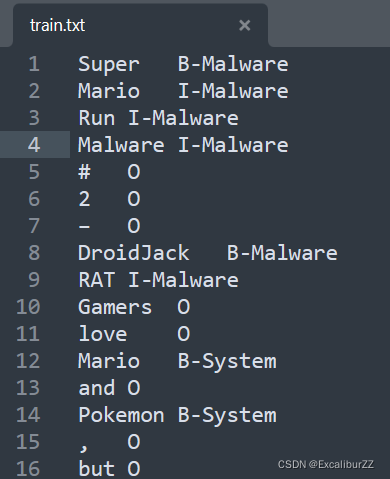
这里中间的分隔符会有不同,我这份是'\t'。
python 代码如下:
from codecs import open
import os
path = os.getcwd()
def set_tag(split, data_dir):
'''
统计标注种类有哪些
:param split: 文件名(不带后缀)
:param data_dir: 文件路径
:return: 去重的标注种类列表
'''
assert split.lower() in ["train", "valid", "test"]
tag_lists = []
with open(os.path.join(data_dir, split + ".txt"), 'r', encoding='utf-8') as f:
for line in f:
if line != '\r\n':
tag = line.strip().split('\t')[1]
tag_lists.append(tag)
else:
pass
return list(set(tag_lists))
def count_tag(split, data_dir):
'''
统计数据集里各个标注对应的数量
:param split: 文件名(不带后缀)
:param data_dir: 文件路径
:return: 去重的标注种类列表及其对应的数量列表
'''
tag_lst = set_tag('train', path) # 标注种类的列表
types = len(tag_lst)
num_lst = [0] * types # 统计个数的列表,和tag列表等长
with open(os.path.join(data_dir, split + ".txt"), 'r', encoding='utf-8') as f:
for line in f:
if line != '\r\n':
tag = line.strip().split('\t')[1]
if tag in tag_lst:
num_lst[tag_lst.index(tag)] = str(int(num_lst[tag_lst.index(tag)]) + 1)
else:
pass
return tag_lst, num_lst # 返回可自己修改,这里返回两个是方便显示
if __name__ == '__main__':
lst_tag, lst_tagNum = count_tag('train', path)
for i in range(len(lst_tag)):
print(lst_tag[i] + ':' + lst_tagNum[i])
版权声明:本文为gwruiki原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。