python爬虫爬取京东商品信息
爬取思路:
1、在京东首页搜索栏输入关键词,以“电脑“为例。需要复制浏览器中的链接
2、爬取搜索页面中共十页的600件商品信息,其中包括商品名称,商品价格,店铺链接,商品样例图,商品价格,商品描述,店铺名称,商品当前活动(如免邮,秒杀)。
3、在爬取搜索页面的商品信息时,获得店铺id,通过店铺id跳转到商品详细信息页面,爬取商品的50条评论信息,商品标签信息及评论总人数,好评数、差评数、中评数。
4、将每一件商品的信息都用json格式存储,并以json格式写入本地txt文件中。
5、通过数据处理,计算出相同店铺的销售量,总销售额和平均价格并排序,最后将排完序的数据分别写入本地txt文件中,并将数据通过echarts进行展示。
6、对好评率超过70%的商品,进行标签分析,拿到买家评论的标签,进行统计,得到该类商品哪些优点会更受大家的青睐,并生成图云文件。
7、爬取中的问题:
7.1:在搜索页爬取商品时会拿不到一些商品的信息,因为当一些特价商品处于秒杀情况时,他的信息会标红,因此css样式的class会不同。
解决:进行分类,观察页面会出现多少种类别的class,将不同的class进行不同的循环提取,保证不会丢失数据。
7.2:在商品详细信息页面中,用户评论信息是实时加载,需要单独拿取,且它的数据格式非标准化json,为jQuery+商品id+{内容}
解决:需要在拿到数据后,进行字符串切割操作,将{}外面的数据全部清除,这样才能使用json.loads()
7.3:在进行数据统计的时候,如价格计算的时候会有脏数据,比如有些特卖电脑标价100,但这只是定金,所以不能用来计算,需要舍弃。
解决:对电脑价格进行一个判断,超出常理的价格将会被丢弃,如小于一千以及大于五万。
注:此次编写的爬虫程序,可以对任意京东商品进行爬取,并且爬取完会储存数据到本地,若使用django,那么本程序可以只用一个查询框,当输入想要查询的商品时,
会一键生成信息文件,价格,销量排行数据,以及echarts图表展示,并且可以下载到本地。所以当以后我们需要购买什么商品时,此程序便可以清晰明了的给我们提供商品信息,
而不用我们一件一件的商品进行查看,四处对比评论及店铺好评率,节省了很多麻烦。
当然,本程序尽供学习使用,非商业用途。
将图片中的地址复制,修改至代码中的165行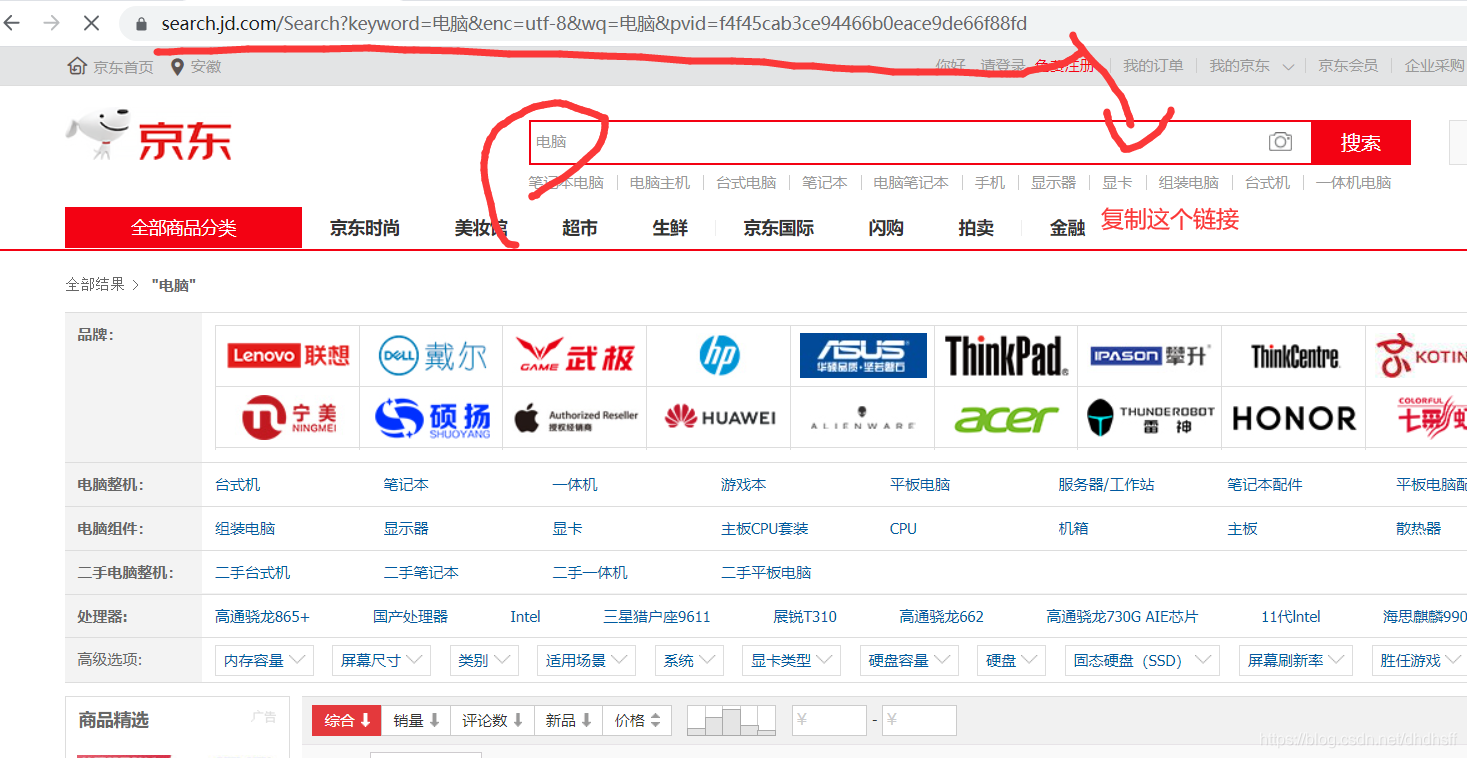
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/5/7 11:17
# @Author : dddchongya
# @Site :
# @File : ComputerFromJD.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup as bst
import json
import os
informationnumber=0
def GetComment(id):
param = {
'callback': 'fetchJSON_comment98',
'productId': id,
'score': 0,
'sortType': 5,
'page': 1,
'pageSize': 10,
'isShadowSku': 0,
'rid': 0,
'fold': 1,
}
url="https://club.jd.com/comment/productPageComments.action"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
CommentLs={}
bool=1
label=[]
comments=[]
commentnumber={}
for i in range(1,5):
param["page"]=i
res_songs = requests.get(url, params=param, headers=headers)
jsondata = res_songs.text
jsondata = json.loads(jsondata.replace("(", "").replace(")", "").replace("fetchJSON_comment98", "").replace(" ","").replace(";", ""))
if bool ==1 :
# 标签只用拿一次
hotCommentTagStatistics=jsondata["hotCommentTagStatistics"]
for j in hotCommentTagStatistics:
label.append(j["name"]+":"+str(j["count"]))
# 评论数量也只用拿一次
productCommentSummary = jsondata["productCommentSummary"]
commentnumber["commentCount"]=productCommentSummary["commentCount"]
commentnumber["defaultGoodCount"] = productCommentSummary["defaultGoodCount"]
commentnumber["goodCount"] = productCommentSummary["goodCount"]
commentnumber["poorCount"] = productCommentSummary["poorCount"]
commentnumber["generalCount"] = productCommentSummary["generalCount"]
commentnumber["afterCountStr"] = productCommentSummary["afterCount"]
commentnumber["showCount"] = productCommentSummary["showCount"]
bool=bool+1
comment=jsondata["comments"]
for j in comment:
comments.append(j["content"].replace("\n",""))
CommentLs["commentnumber"]=commentnumber
CommentLs["label"]=label
CommentLs["comments"]=comments
return CommentLs
def GetMoreInformation(id):
url="https://item.jd.com/"+id+".html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
res= requests.get(url, headers=headers)
html=bst(res.content)
def GetGoodResone(LsComputer):
labells = []
label = set()
labellist = {}
for i in LsComputer:
if (i['comments']['commentnumber']['goodCount'] + i['comments']['commentnumber'][
'defaultGoodCount']) / float(i['comments']['commentnumber']['commentCount']) > 0.7:
labells.append(i['comments']["label"])
for i in labells:
for j in i:
label.add(j.split(":")[0])
for i in label:
labellist[i] = 0
for j in labells:
for k in j:
labellist[k.split(":")[0]] = labellist[k.split(":")[0]] + float(k.split(":")[1])
result = sorted(labellist.items(), key=lambda x: x[1], reverse=False)
with open(os.getcwd() + '\好评过七十的标签排行.txt', 'w', encoding="utf-8") as f:
for i in result:
f.write(str(i))
f.write('\r\n')
f.close()
def GetMaxSalesShop(LsComputer):
shop=set()
for i in LsComputer:
shop.add(i["ShopName"])
shopcount={}
shopsalecount={}
shopprice={}
for i in shop:
shopcount[i]=0
shopsalecount[i]=0
shopprice[i] = []
for i in shop:
for j in LsComputer:
if j["ShopName"]==i:
if j["Price"].__len__()>=5:
price=j["Price"][0:-3].replace("\n","").replace(" ","").replace("\t","")
# 销售额
shopcount[i]=shopcount[i]+j["comments"]["commentnumber"]["commentCount"]*float(price)
#价格总和,为了求平均数
shopprice[i].append(price)
# 销售量
shopsalecount[i]=shopsalecount[i]+j["comments"]["commentnumber"]["commentCount"]
shopprice2={}
for i in shopprice:
sum=0
if shopprice[i].__len__() != 0:
for j in shopprice[i]:
sum=sum+float(j)
price=sum/(shopprice[i].__len__())
shopprice2[i]=price
print()
print()
result=sorted(shopcount.items(), key=lambda x: x[1], reverse=False)
print("销售额排行::")
for i in result:
print(i)
with open(os.getcwd() + '\销售额排行.txt', 'w', encoding="utf-8") as f:
for i in result:
f.write(str(i))
f.write('\r\n')
f.close()
print()
print()
result = sorted(shopprice2.items(), key=lambda x: x[1], reverse=False)
print("销售量排行::")
for i in result:
print(i)
with open(os.getcwd() + '\销售量排行.txt', 'w', encoding="utf-8") as f:
for i in result:
f.write(str(i))
f.write('\r\n')
f.close()
print()
print()
result = sorted(shopsalecount.items(), key=lambda x: x[1], reverse=False)
print("平均价格排行::")
for i in result:
print(i)
with open(os.getcwd() + '\平均价格排行.txt', 'w', encoding="utf-8") as f:
for i in result:
f.write(str(i))
f.write('\r\n')
f.close()
# 可任意写搜索链接
url = 'https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E7%94%B5%E8%84%91&page='
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
LsComputer=[]
#bool=1 # 每页开头第一个商品格式有误差,所以以此为判断符号跳过第一个
for k in range(1,10):
url=url+str(k*2+1)
res= requests.get(url, headers=headers)
html=bst(res.content)
list=html.findAll("li",{"class","gl-item gl-item-presell"})
for html in list:
ComputerInformation={}
CustomUrl=html.find("div",{"class","p-img"}).find("a").get("href")
if not str(CustomUrl).__contains__("https:"):
CustomUrl="https:"+CustomUrl
# print(CustomUrl)
id=html.find("div",{"class","p-price"}).find("strong").get("class")
id=id[0].replace("J","").replace("_","")
# 拿到评论信息
Comments=GetComment(id)
#print(Comment)
#进入页面拿更详细的信息
ImgUrl="https:"+str(html.find("div",{"class","p-img"}).find("img").get("source-data-lazy-img"))
# print(ImgUrl)
Price=str(html.find("div",{"class","p-price"}).find("i"))[3:-4]
# print(Price[3:-4])
Describe=str(html.find("div",{"class","p-name p-name-type-2"}).find("em").getText())
# print(Describe)
#第一行一个会为空
ShopName=html.find("div",{"class","p-shop"}).find("a")
if ShopName != None:
ShopName=str(ShopName.getText())
# print(ShopName)
# 店铺描述可能有多个
Mode=html.find("div",{"class","p-icons"}).findAll("i")
BusinessMode=[]
for i in Mode:
BusinessMode.append(i.getText())
# print(BusinessMode)
ComputerInformation["CustomUrl"]=CustomUrl
ComputerInformation["ImgUrl"] = ImgUrl
ComputerInformation["Price"] = Price
ComputerInformation["Describe"] = Describe
ComputerInformation["ShopName"] = ShopName
ComputerInformation["CustomUrl"] = CustomUrl
ComputerInformation["BusinessMode"] = BusinessMode
ComputerInformation["comments"]=Comments
LsComputer.append(ComputerInformation)
for k in range(1,10):
url=url+str(k*2+1)
res= requests.get(url, headers=headers)
html=bst(res.content)
list=html.findAll("li",{"class","gl-item"})
for html in list:
ComputerInformation={}
CustomUrl=html.find("div",{"class","p-img"}).find("a").get("href")
if not str(CustomUrl).__contains__("https:"):
CustomUrl="https:"+CustomUrl
# print(CustomUrl)
id=html.find("div",{"class","p-price"}).find("strong").get("class")
id=id[0].replace("J","").replace("_","")
# 拿到评论信息
Comments=GetComment(id)
#print(Comment)
#进入页面拿更详细的信息
ImgUrl="https:"+str(html.find("div",{"class","p-img"}).find("img").get("source-data-lazy-img"))
# print(ImgUrl)
Price=str(html.find("div",{"class","p-price"}).find("i"))[3:-4]
# print(Price[3:-4])
Describe=str(html.find("div",{"class","p-name p-name-type-2"}).find("em").getText())
# print(Describe)
#第一行一个会为空
ShopName=html.find("div",{"class","p-shop"}).find("a")
if ShopName != None:
ShopName=str(ShopName.getText())
# print(ShopName)
# 店铺描述可能有多个
Mode=html.find("div",{"class","p-icons"}).findAll("i")
BusinessMode=[]
for i in Mode:
BusinessMode.append(i.getText())
# print(BusinessMode)
ComputerInformation["CustomUrl"]=CustomUrl
ComputerInformation["ImgUrl"] = ImgUrl
ComputerInformation["Price"] = Price
ComputerInformation["Describe"] = Describe
ComputerInformation["ShopName"] = ShopName
ComputerInformation["CustomUrl"] = CustomUrl
ComputerInformation["BusinessMode"] = BusinessMode
ComputerInformation["comments"]=Comments
LsComputer.append(ComputerInformation)
#数据写入文件
with open(os.getcwd() + '\json.txt', 'w',encoding="utf-8") as f:
for i in LsComputer:
f.write(json.dumps(i,indent=4,ensure_ascii=False))
f.close()
GetMaxSalesShop(LsComputer)