
一、分析背景及目的
Amazon一直是全球电商的佼佼者,也推出了不少深受大家喜爱的电子产品,如Kindle。python是目前越来越火的编程语言,近期有报道小学也在推广学习,故此次选择了Amazon Products的顾客评价作为分析对象,分析工具使用python。
数据来自kaggle:Consumer Reviews of Amazon Products
二、分析思路
1、理解数据
数据集一共有34655行,字段分别为:
id-用户编号
name-产品名称
asins-产品编号
brand-品牌
categories-产品类别
keys-类别关键字
manufacturer-制造商
date-评论时间
dateAdded-追评时间
dateSeen-评论可见时间
doRecommend-是否推荐
numHelpful-评论赞同数
rating-评分
sourceURLs-评论链接
text-评论文字内容
title-评论标题
username-用户名
2、提出问题
获得最多好评的产品是什么?
各类产品的好评率如何(评分5的占比)?
各产品在时间上评论差异?
各类产品用户的推荐意愿如何?
写出评论赞同数最多的用户是谁,对产品评价如何?
三、数据清洗
1、将数据导入python
import pandas as pd
import numpy as np
FileNameStr='../亚马逊智能产品评论.csv'
reviewsDf = pd.read_csv(FileNameStr,dtype=object)然后执行reviewsDf.head()
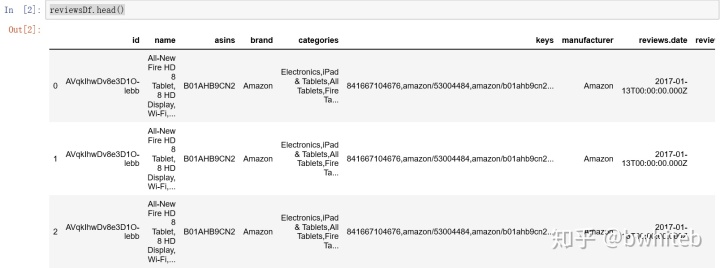
统计数据集的大小和类型:


2、确定子集及重命名
根据分析问题需要,选择其中的这些子集:id、name、brand、date、doRecommend、numHelpful、rating、username,并重命名为中文。
#取出需要的数据
subreviewsDf=reviewsDf.loc[:,['id','name','brand','reviews.date','reviews.doRecommend','reviews.numHelpful','reviews.rating','reviews.username']]
#并对数据重命名
colNameDict={'id':'产品id','name':'产品名称','brand':'品牌','reviews.date':'评论时间','reviews.doRecommend':'是否推荐','reviews.numHelpful':'评论赞同数','reviews.rating':'评分','reviews.username':'用户名'}
subreviewsDf.rename(columns=colNameDict,inplace=True)
3、缺失数据处理
对产品名称,评论时间和评分中任何一项有缺失的数据进行删除。

#删除列(产品名称,评论时间和评分)中为空的行
subreviewsDf=subreviewsDf.dropna(subset=['产品名称','评论时间','评分'],how='any')
print('删除缺失值后大小',subreviewsDf.shape)
处理后还剩27850条数据。
4、数据类型转换
将评论赞同数和评分改变为浮点型,评论时间和追评时间改变为日期格式
subreviewsDf['评论赞同数']=subreviewsDf['评论赞同数'].astype('float')
subreviewsDf['评分']=subreviewsDf['评分'].astype('float')
print('转换后的数据类型:n',subreviewsDf.dtypes)
使用split分割依次处理评论时间和追评时间
#获取“评论时间”这一列
timeSer=subreviewsDf.loc[:,'评论时间']
#对字符串进行分割,获取销售日期
dateSer=splittime(timeSer)
#修改评论时间这一列的值
subreviewsDf.loc[:,'评论时间']=dateSer
#展示前5列数据
subreviewsDf.head(5)
#转换为日期格式
subreviewsDf.loc[:,'评论时间']=pd.to_datetime(subreviewsDf.loc[:,'评论时间'],format='%Y-%m-%d', errors='coerce')
#输出数据类型
subreviewsDf.dtypes
再将不符合日期格式的删除
subreviewsDf=subreviewsDf.dropna(subset=['产品名称','评论时间','评分'],how='any')
print('删除缺失值后大小',subreviewsDf.shape)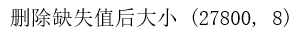
5、数据排序
按评论时间排序,并重命名行
#按销售日期进行升序排列
subreviewsDf=subreviewsDf.sort_values(by='评论时间',ascending=True,na_position='first')
#重命名行名(index):
subreviewsDf=subreviewsDf.reset_index(drop=True)
subreviewsDf.head()
6、异常值处理
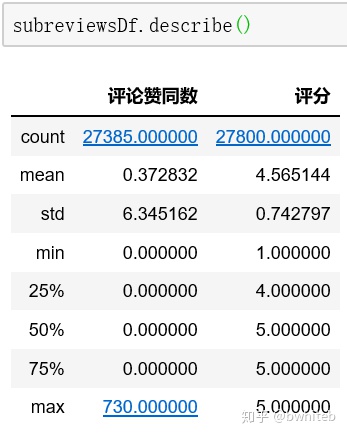
从评论赞同数都是>=0,评分也是1-5,数据无误。
四、分析内容
1、获得最多好评的产品是什么?
#选出分为5的
querySer = subreviewsDf.loc[:,'评分']==5
sub1Df = subreviewsDf.loc[querySer,:]
sub1Df.head()
sub1Df.shape[0]评分为5分的评论有18648次
#按产品进行分类
sub1Df1 = pd.DataFrame(sub1Df.groupby(["产品名称"],sort=True)["品牌"].size()).reset_index()
#列重命名
NameDict = {'品牌':'好评数'}
sub1Df1.rename(columns = NameDict,inplace=True)
#按好评数降序排列
sub1Df1=sub1Df1.sort_values(by='好评数',ascending=False ,na_position='first')
#取前5结果
sub1Df1=sub1Df1.head(5)
sub1Df1
其中Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta ,获得6482次5分评论,是获得好评最多的产品。 2、各类产品的好评率如何(评分5的占比)?
对整体产品看:
#按产品进行分类
sub2Df1 = pd.DataFrame(subreviewsDf.groupby(["评分"],sort=True)["品牌"].size()).reset_index()
#列重命名
NameDict = {'品牌':'评论数'}
sub2Df1.rename(columns = NameDict,inplace=True)
sub2Df1
a=sub2Df1.loc[:,'评论数'].sum()
#定义新列
aDf = pd.DataFrame()
aDf['占比']=sub2Df1['评论数']/a
sub2Df1 = pd.concat([sub2Df1,aDf],axis=1)
sub2Df1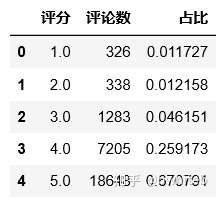
#导入matplotlib的pyplot模块
import matplotlib.pyplot as plt
sub2Df1.plot(x='评分',y='占比',kind='bar')
plt.show()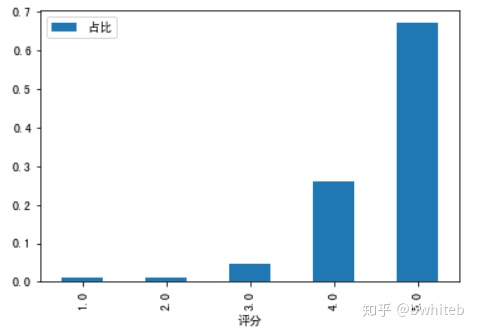
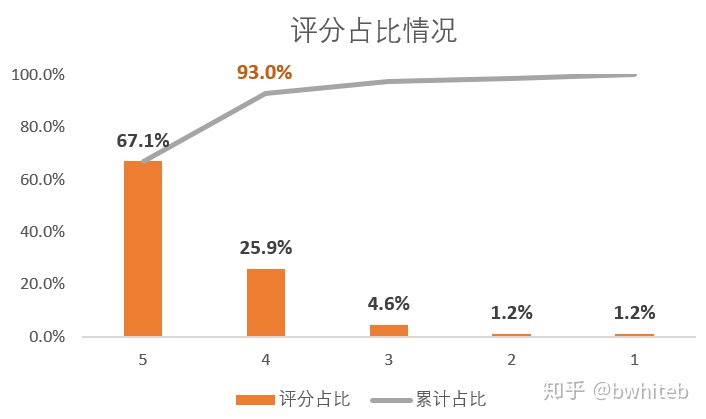
5分好评数18648,占总评论数27800的67.1%,4分及以上占比93%。
对好评数最多的Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta:
#选出Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta
querySer = subreviewsDf.loc[:,'产品名称']=='Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta'
sub2Df = subreviewsDf.loc[querySer,:]
#按产品进行分类
sub2Df2 = pd.DataFrame(sub2Df.groupby(["评分"],sort=True)["品牌"].size()).reset_index()
#列重命名
NameDict = {'品牌':'评论数'}
sub2Df2.rename(columns = NameDict,inplace=True)
sub2Df2
a=sub2Df2.loc[:,'评论数'].sum()
#定义新列
aDf = pd.DataFrame()
aDf['占比']=sub2Df2['评论数']/a
sub2Df2 = pd.concat([sub2Df2,aDf],axis=1)
sub2Df2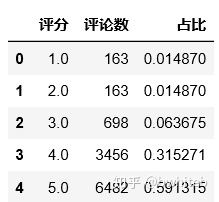
sub2Df2.plot(x='评分',y='占比',kind='bar')
plt.show()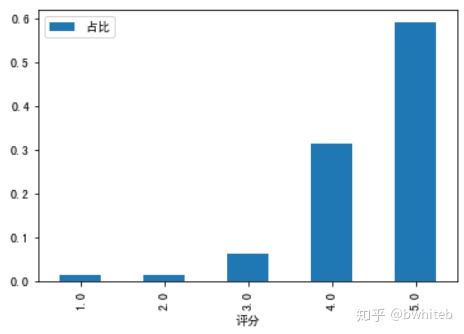
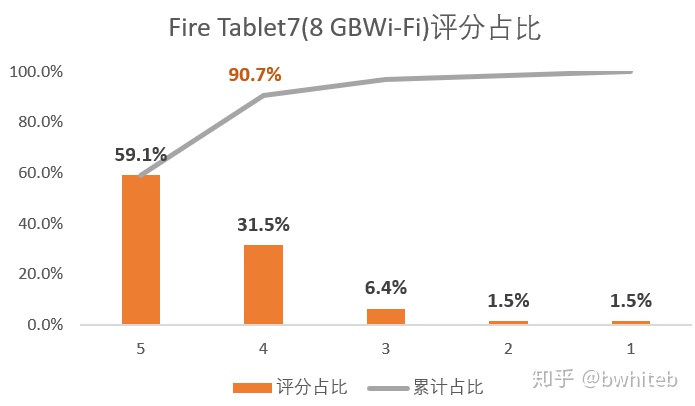
5分好评数6482,占总评论数10962的59.1%,4分及以上占比90.7%。
3、各产品在时间上评论差异?
sub1Df2 = pd.DataFrame(sub1Df.groupby(["评论时间"],sort=True)["评分"].size()).reset_index()
sub1Df2
#x坐标轴上点的数值
x=sub1Df2.loc[:,'评论时间']
#y坐标轴上点的数值
y=sub1Df2.loc[:,'评分']
plt.plot(x,y)
#x轴文本
plt.xlabel('评论时间')
#y轴文本
plt.ylabel('评论数')
#标题
plt.title('评论数随时间的变化情况')
plt.show()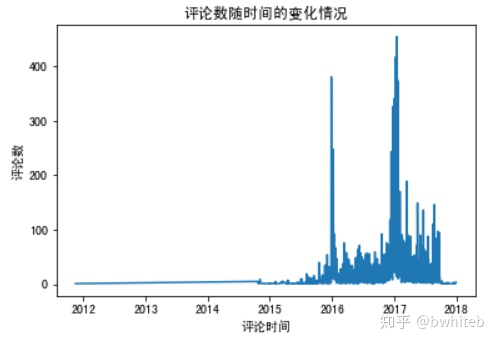
评论最多的是2016和2017年,按评论次数由多到少降序排列,看具体时间情况:
#列重命名
NameDict = {'评分':'评论数'}
sub1Df2.rename(columns = NameDict,inplace=True)
#按好评数降序排列
sub1Df2=sub1Df2.sort_values(by='评论数',ascending=False ,na_position='first')
#取前5结果
sub1Df3=sub1Df2.head(10)
sub1Df3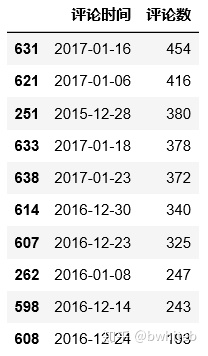
#按时间重新排序
sub1Df3=sub1Df3.sort_values(by='评论时间',ascending=True ,na_position='first')
#画出图形
sub1Df3.plot(x='评论时间',y='评论数',kind='bar')
plt.show()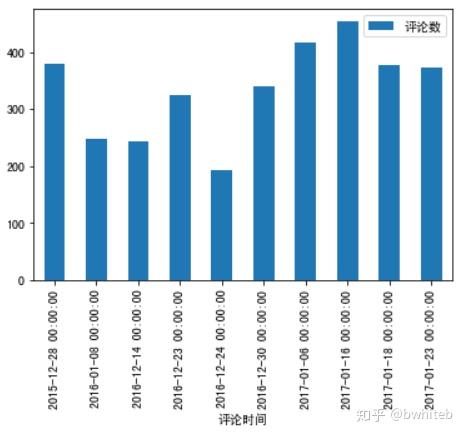
前十评论数集中在2015年底到2016年1月,2016年底到2017年1月。
4、各类产品用户的推荐意愿如何?
按品牌进行统计:
#按品牌和是否推荐进行分组,并统计个数
group4=subreviewsDf.groupby(['品牌','是否推荐']).size()
group4
推荐数为26213,占总统计数27359的95.81%。
按产品统计,选择好评数最多的Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta:

推荐数为10420,占总统计数10962的95.06%。
5、写出评论赞同数最多的用户是谁,对产品评价如何?
#按评论赞同数进行降序排列
sub4Df=subreviewsDf.sort_values(by='评论赞同数',ascending=False)
#取其前10行:
sub4Df.head(10)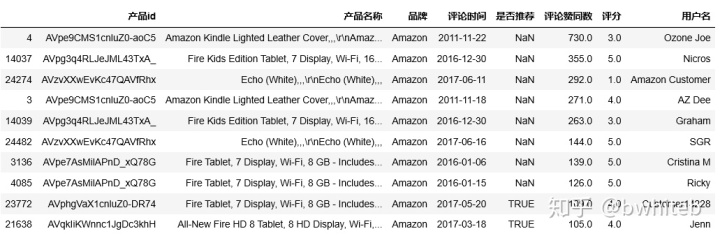
评论赞同数最多用户是‘Ozone Joe’,获得730个赞同数,评分是3分,可以在原始数据中查询出具体评价为:
#转评论赞同数为浮点型
reviewsDf['reviews.numHelpful']=reviewsDf['reviews.numHelpful'].astype('float')
#评论赞同数最多的用户的评论?
querySer = reviewsDf.loc[:,'reviews.numHelpful']==730
sub5Df = reviewsDf.loc[querySer,:]
sub5Df
#找出评论内容
sub5Df=sub5Df.loc[:,['name','reviews.date','reviews.numHelpful','reviews.rating','reviews.username','reviews.title','reviews.text']]
sub5Df
使用groupby显示评论的全部内容:

评论标题为:“A Step Down In Quality”,这是不满意的地方,内容具体有写是哪些感受。评论也提到“overall I was very pleased with the case”,说明用户总体还是比较满意。
五、结论及建议
1、获得最多好评的产品是Fire Tablet, 7 Display, Wi-Fi, 8 GB - Includes Special Offers, Magenta ,共获得6482次5分评论,这个系列需求大,需重点关注。
2、各类产品的好评率,整体5分好评数18648,占总评论数27800的67.1%,4分及以上占比93%。最受关注的Fire Tablet, 7 Display, Wi-Fi, 8 GB版本,5分好评数6482,占总评论数10962的59.1%,4分及以上占比90.7%。用户满意度总体较高,少部分差评也需要多关注。
3、产品在时间上评论差异,前十评论数集中在2015年底到2016年1月,2016年底到2017年1月。年底到年初是需求主要时间段,货源等需重点关注。
4、各类产品用户的推荐意愿,总体推荐数为26213,占总数的95.81%,其中Fire Tablet, 7 Display, Wi-Fi, 8 GB版本推荐数为10420,占总统计数10962的95.06%。推荐率比产品4分以上好评率高,用户接受度高。
5、写出评论赞同数最多的用户是Ozone Joe,评论获得730个赞同数,不满意的地方“A Step Down In Quality”,总体还是比较满意的。高赞同数的评论需要重点关注,对潜在用户的购买有引导作用。