本文就从如下的几个方面讲述下我的使用心得:
初体验——与Logstash的对比
安装部署
启动教程
参数与实例分析
Flume初体验
Flume的配置是真繁琐,source,channel,sink的关系在配置文件里面交织在一起,没有Logstash那么简单明了。
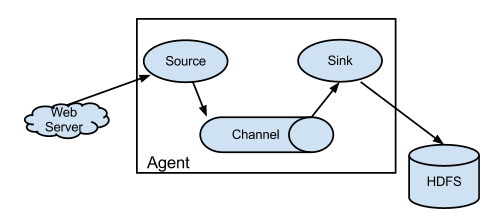
Flume与Logstash相比,我个人的体会如下:
Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
Logstash浅谈:
Logstash中:
input负责数据的输入(产生或者说是搜集,以及解码decode);
Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)

在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
Flume浅谈:
在Flume中:
source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
channel 负责数据的存储持久化(一般都是memory或者file两种)
sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
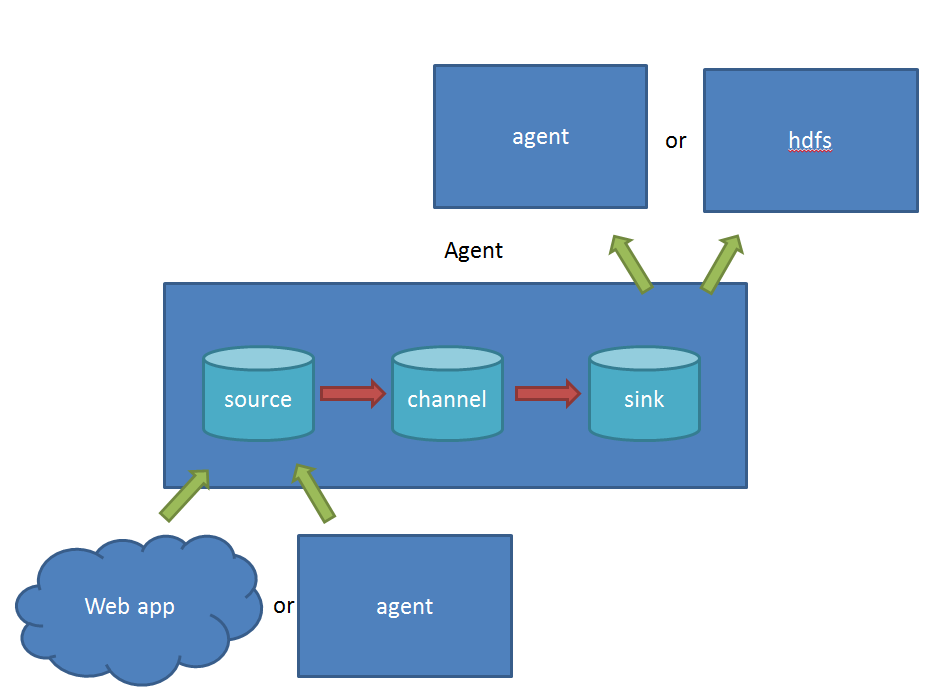
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
参考
1 Flume开发者指南
2 Flume使用指南
作者:Albert陈凯
链接:https://www.jianshu.com/p/9ff3360d99bb
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。