六:zk实现分布式锁
分布式锁的原理:
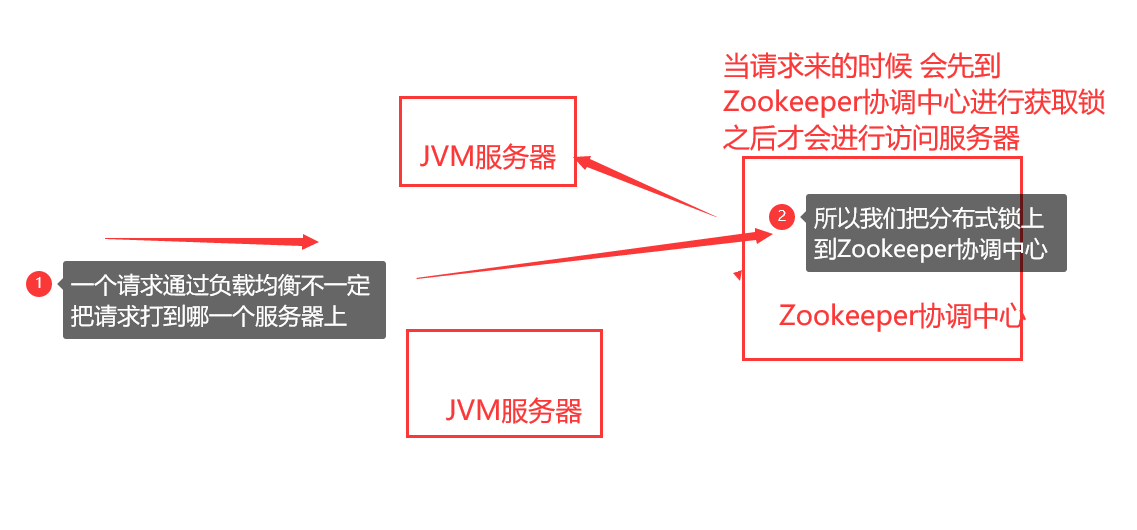
1.zk中锁的种类

我们模拟一个场景进行理解记忆:
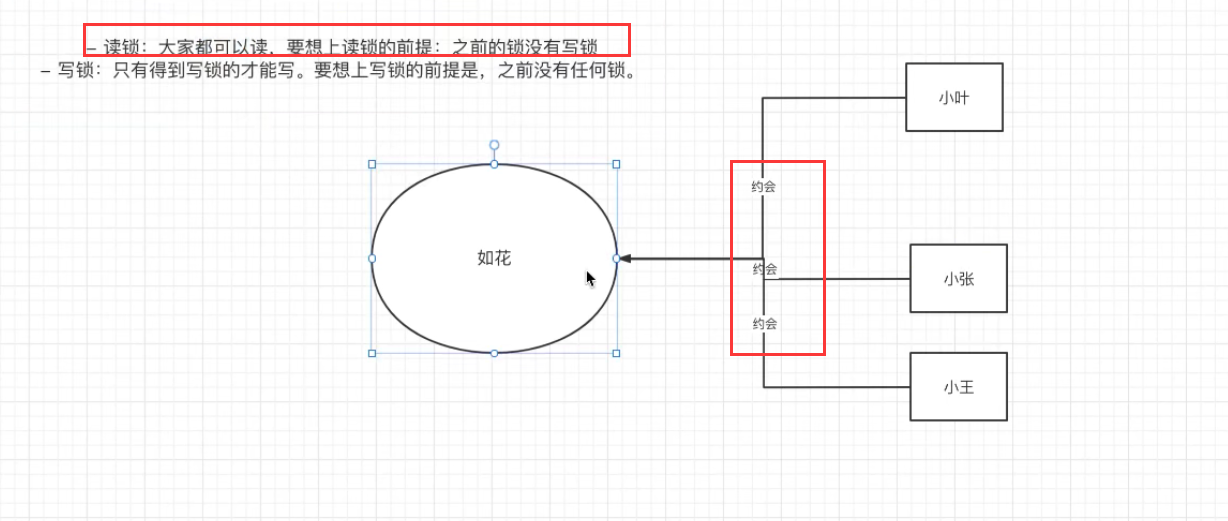
假设有三男:小叶,小张,小王 ,还有一个女生:如花
设读锁为约会,写锁为结婚
分情况讨论:
1.在如花没有结婚(没有上写锁)时,可以同时和这三个男人进行约会(都可以进行读)
2.如花和小叶结婚(上了一个写锁),那么就不可以再和其他人约会了(不可以再上读锁了)
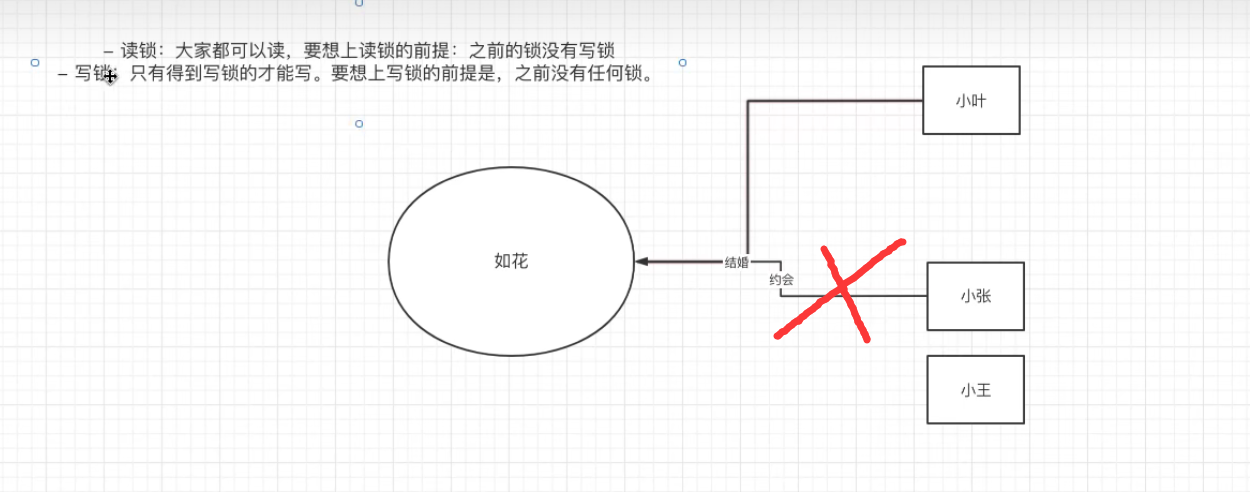
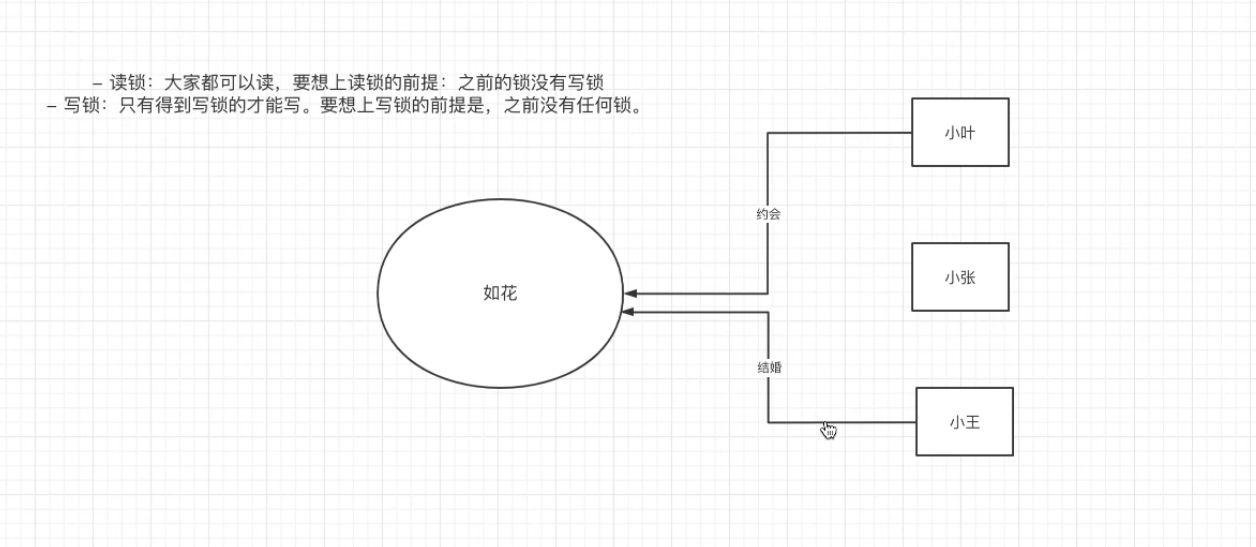
3.当如花在和小叶约会(上了读锁),那么此时小王不可以和如花结婚(不可以上写锁)
原因:要想和一个人结婚,应该和其他人的感情断干净 !
2.zk如何上读锁
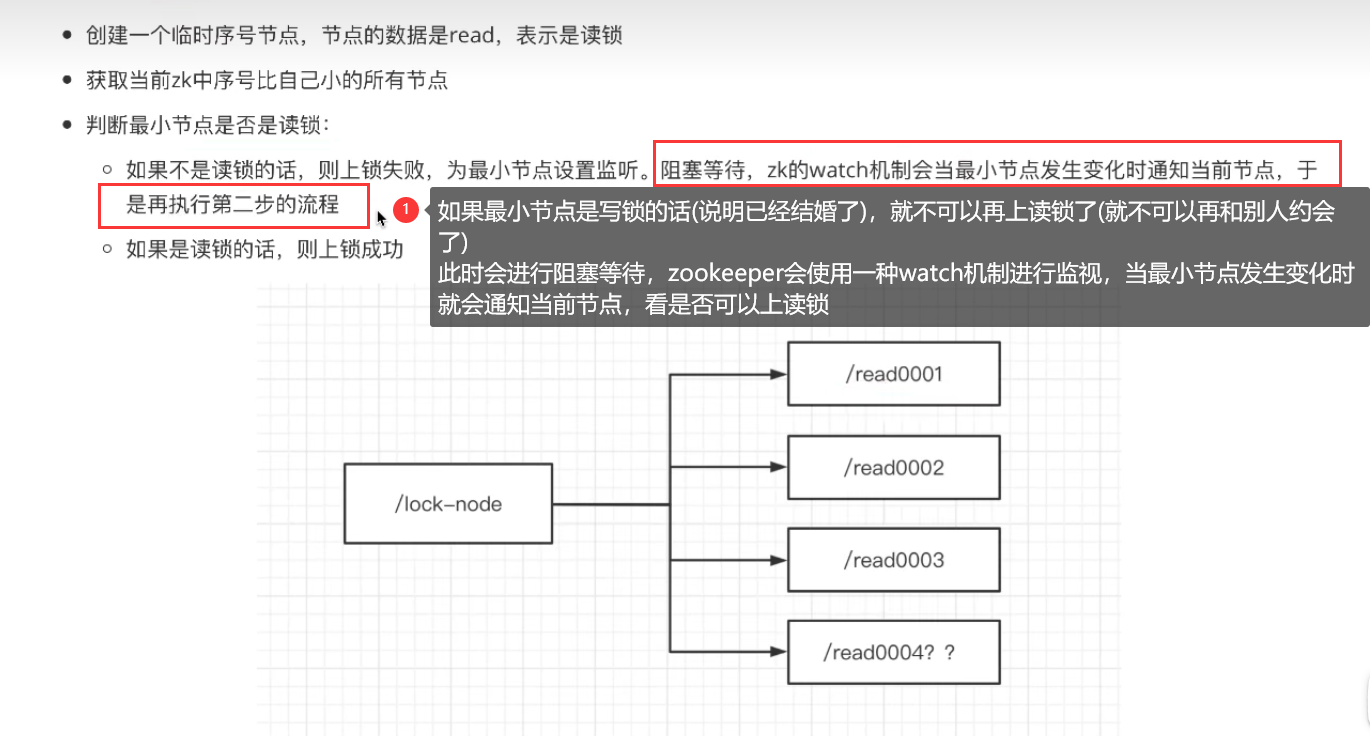
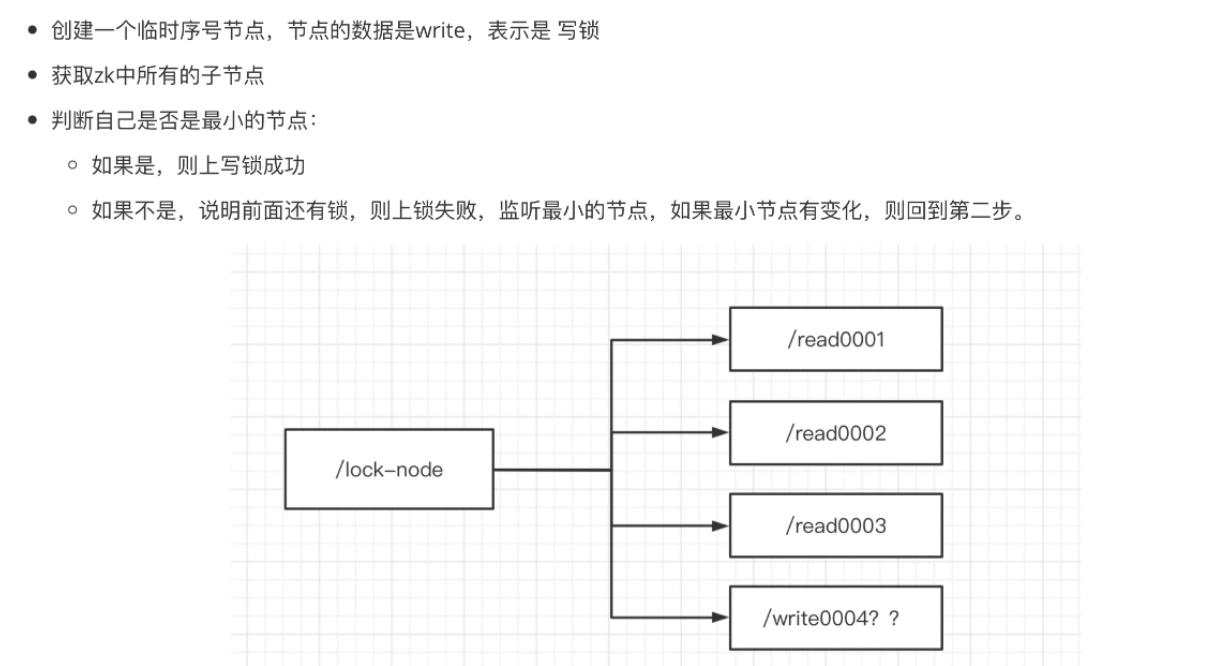
3.zk如何上写锁
上写锁就是好比是结婚,结婚之前不可以约会也不可以结婚
如果写锁不是在最小的节点上,那么就说明前面还有其他锁,有其他任意的锁,写锁就添加不成功 !
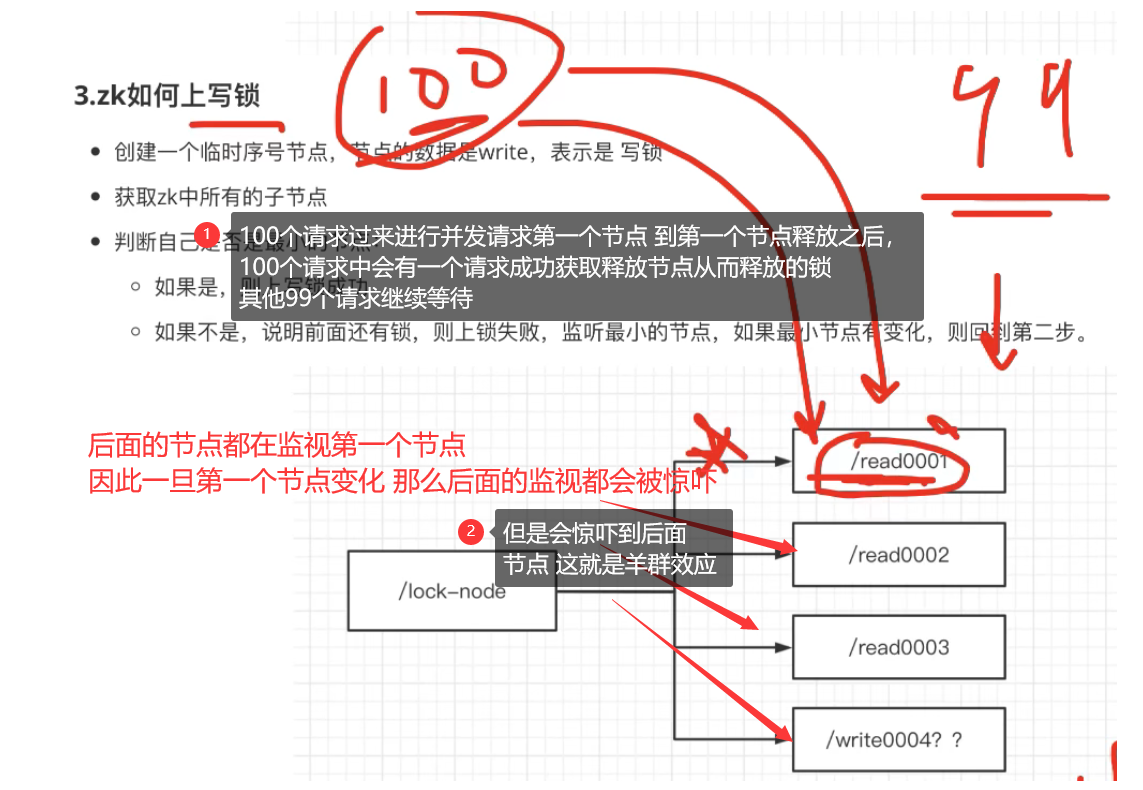
4.羊群效应
出现问题:
前提:
1.锁只有一把 2.后面的节点都进行监视第一个节点
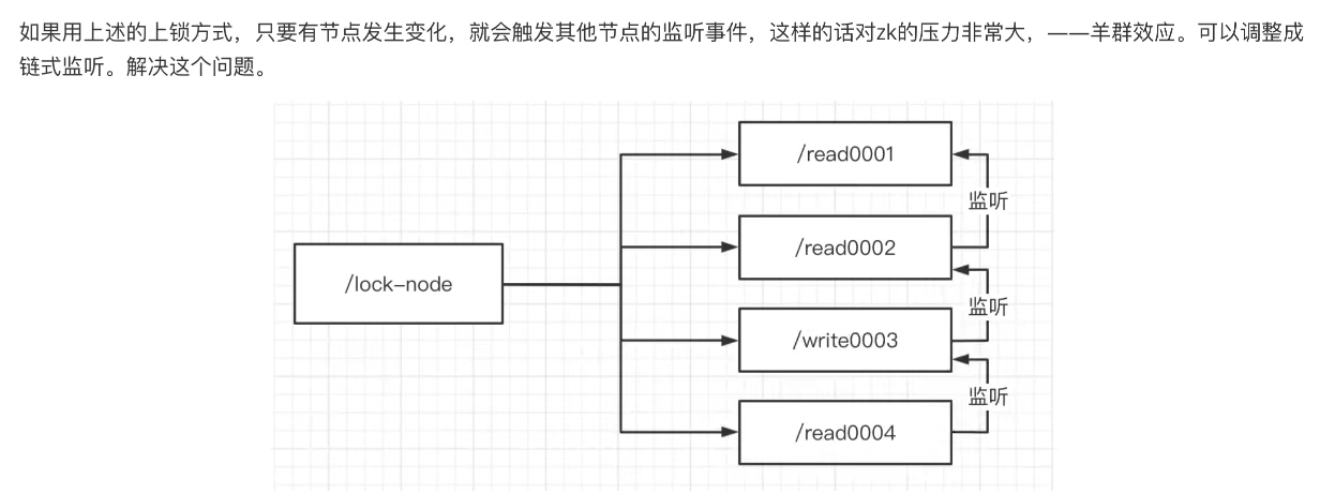
羊群效应解决方法:
这样分层监视避免了羊群效应。
当一个节点断开时,只会让第二个监听它的节点受到惊吓。
假设当第二个节点断开时,第三个节点会跳转到进行监视第一个节点,当第一个节点再断开时,锁才会释放。然后其他请求才会去获取锁,因为锁只有一把。
5.curator实现读写锁
七:zk的watch机制
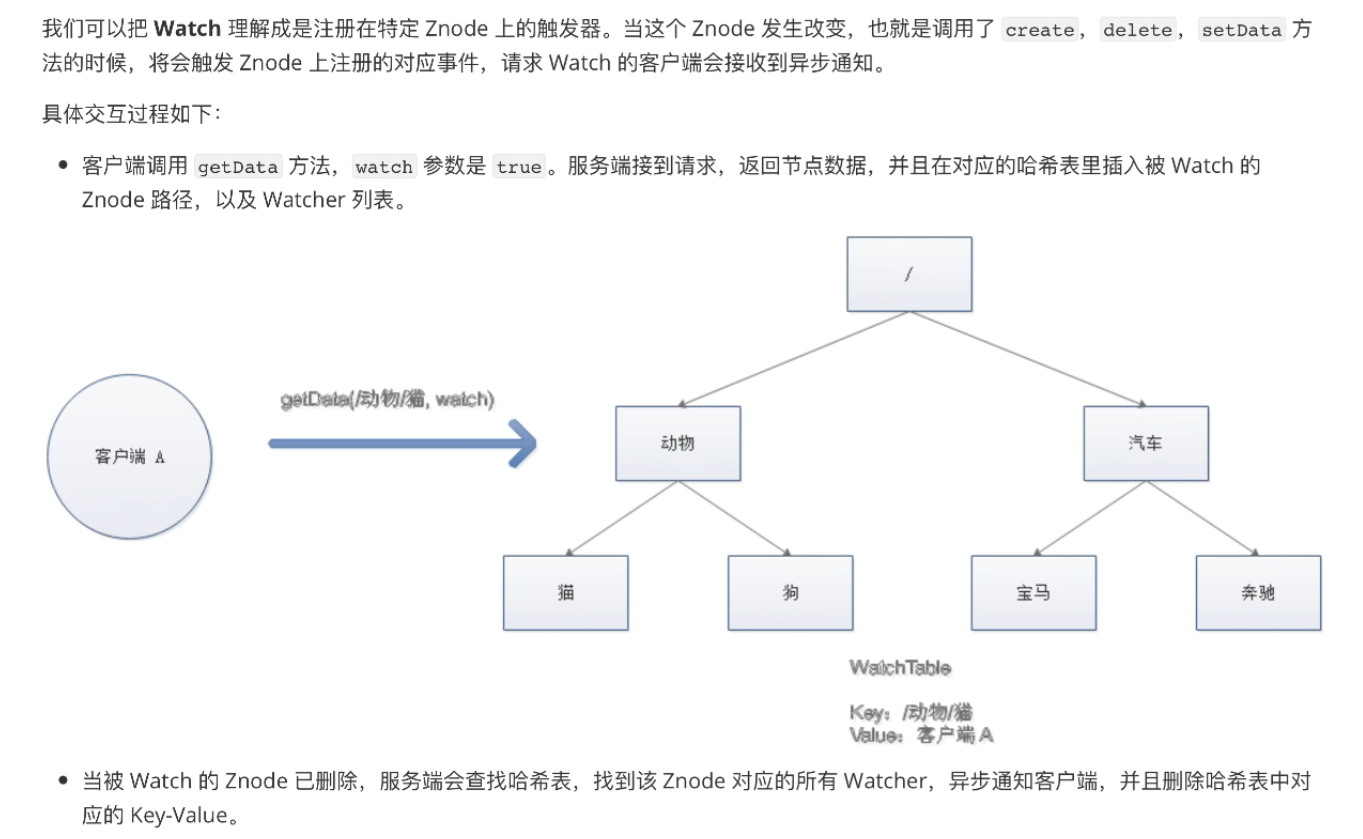
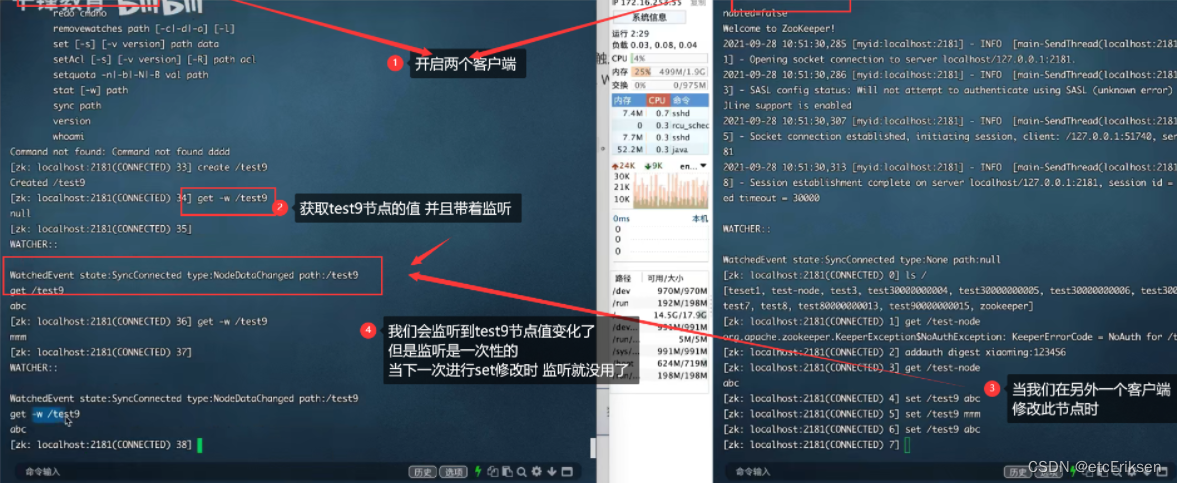


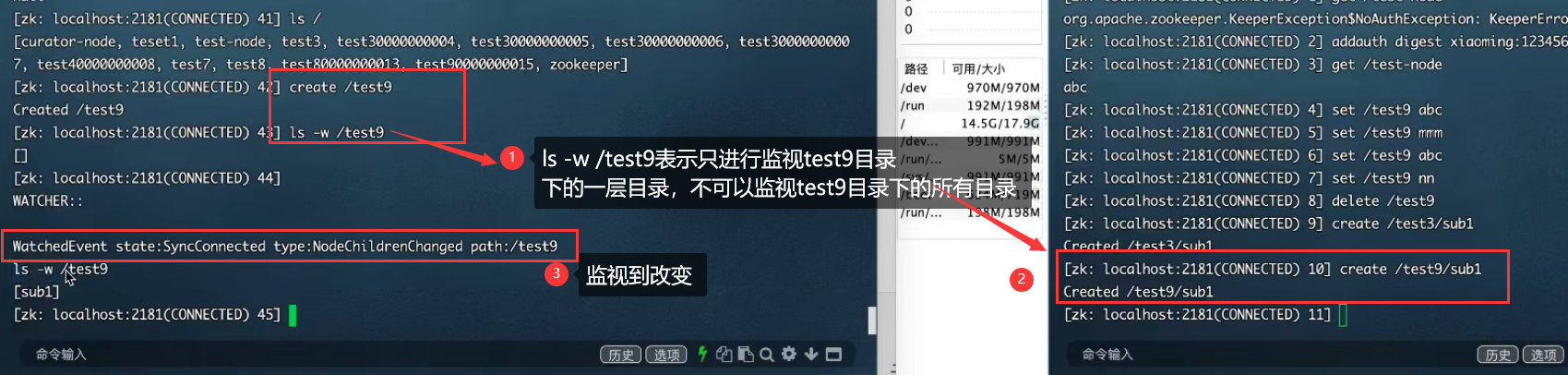
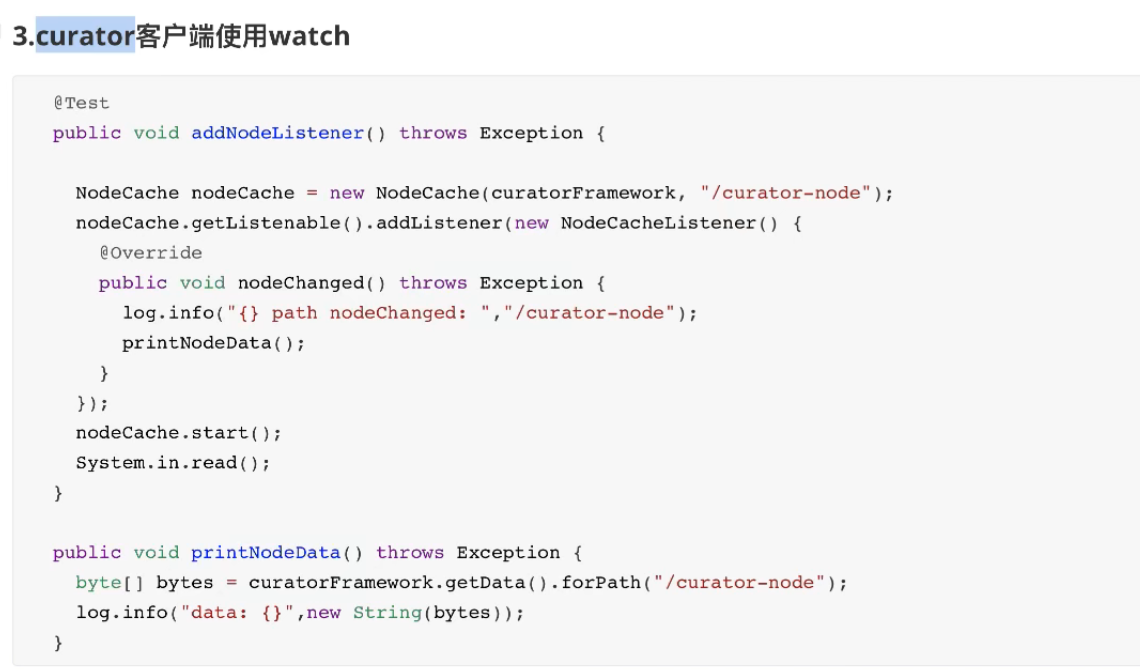
八:Zookeeper集群实战

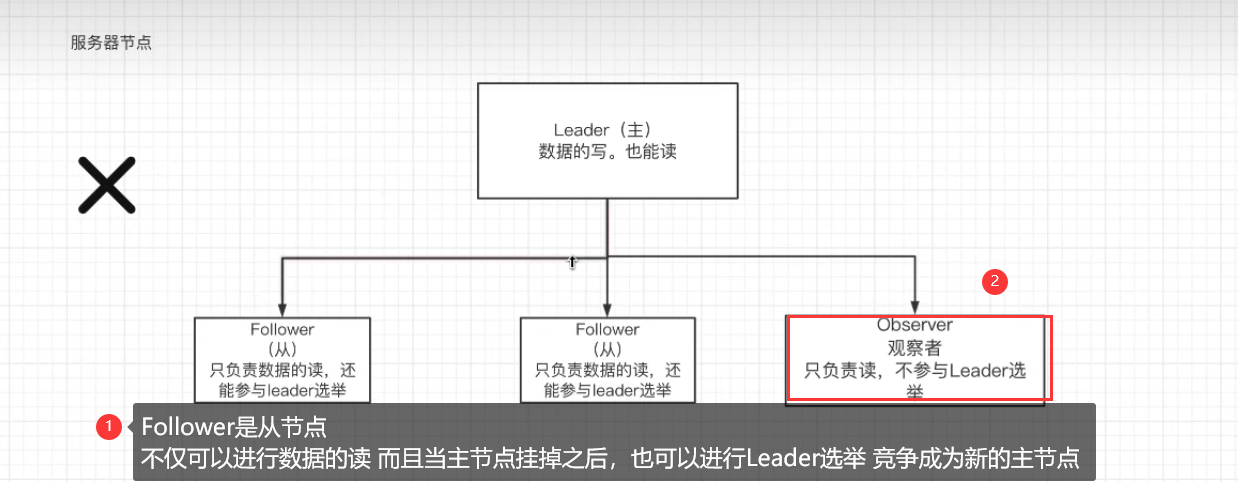
步骤演示:
1.
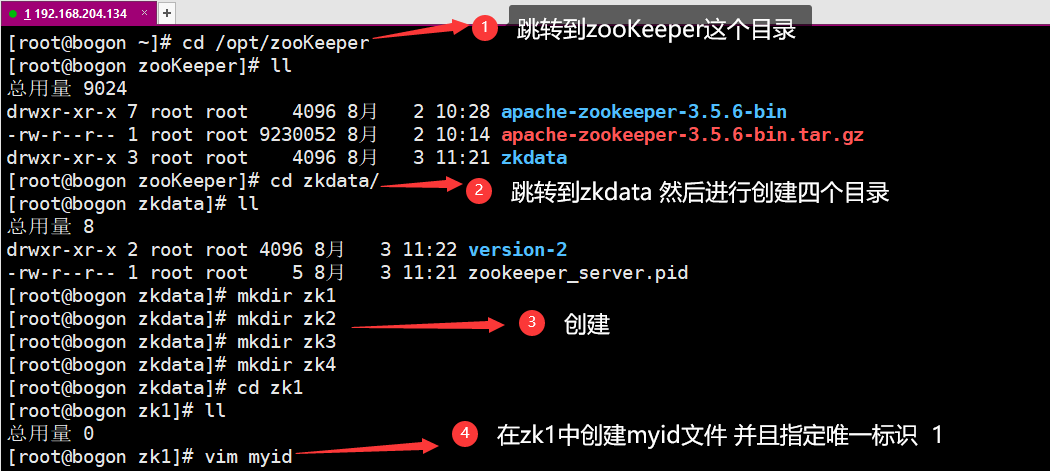

2.同理
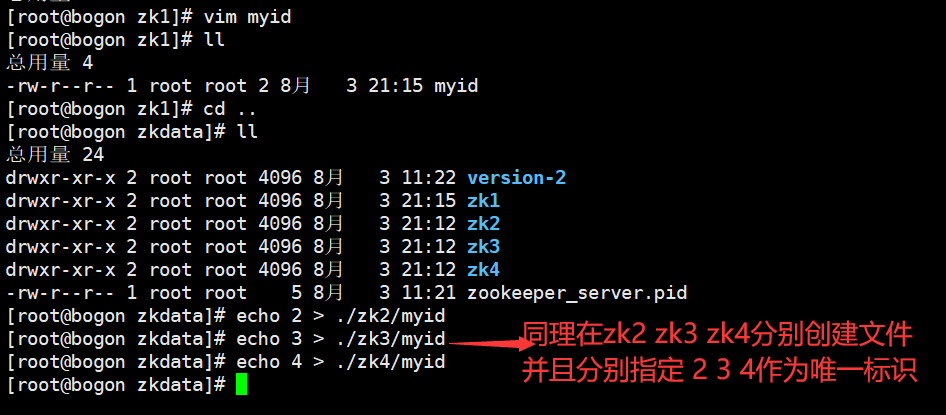
3.
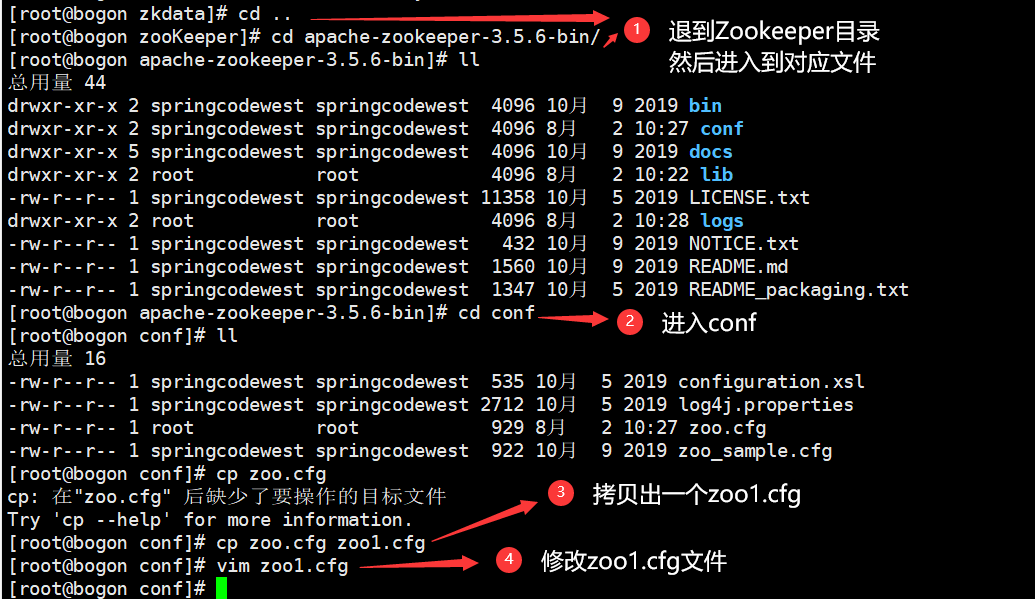
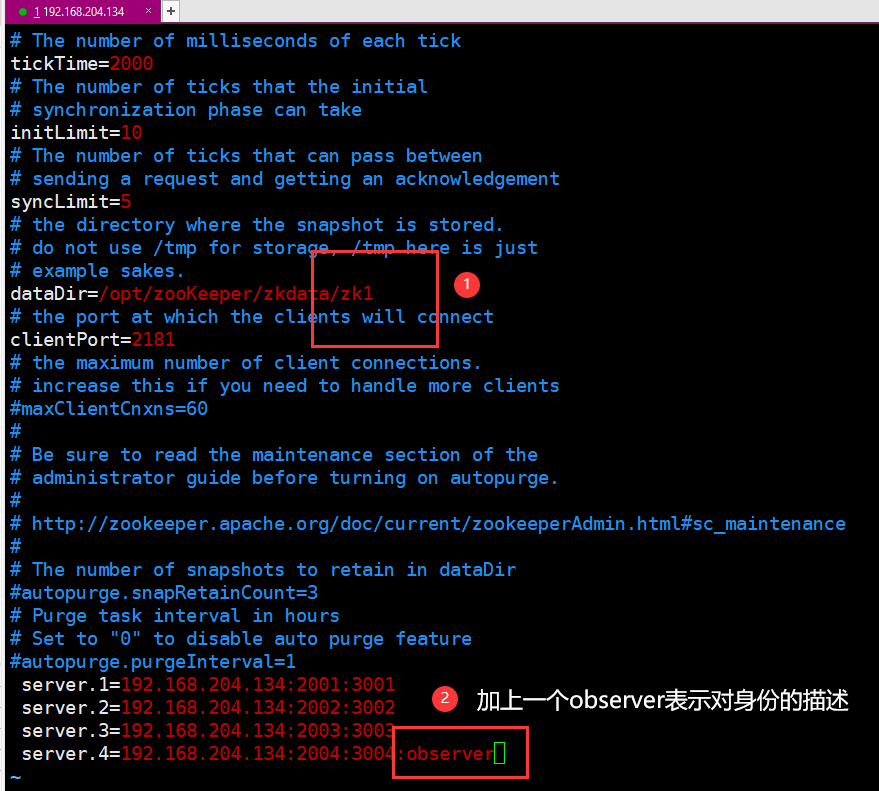
分析细节(不是步骤):
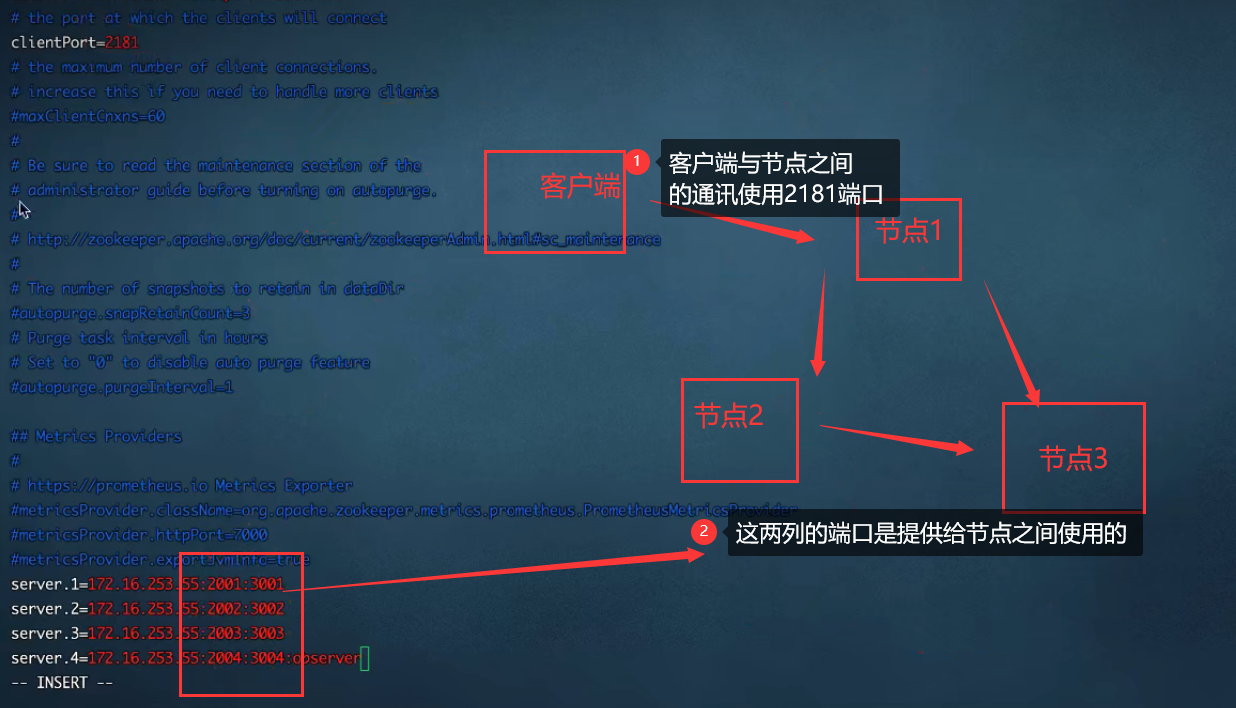
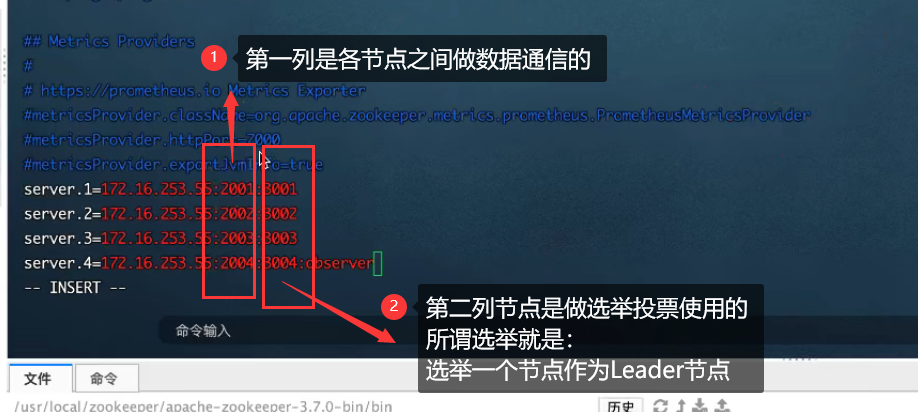
4.
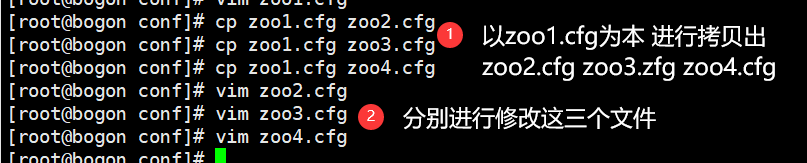
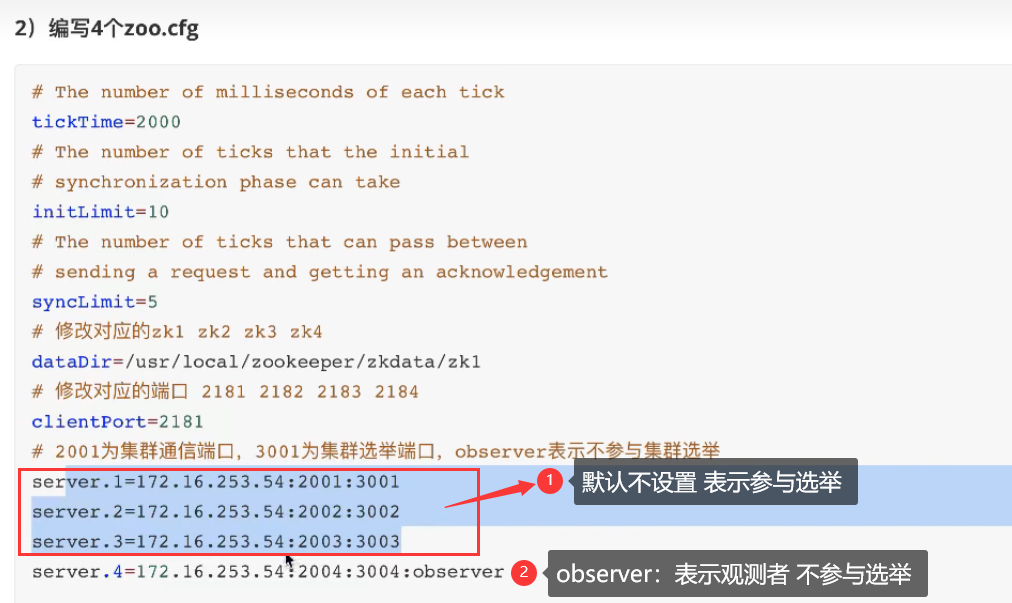
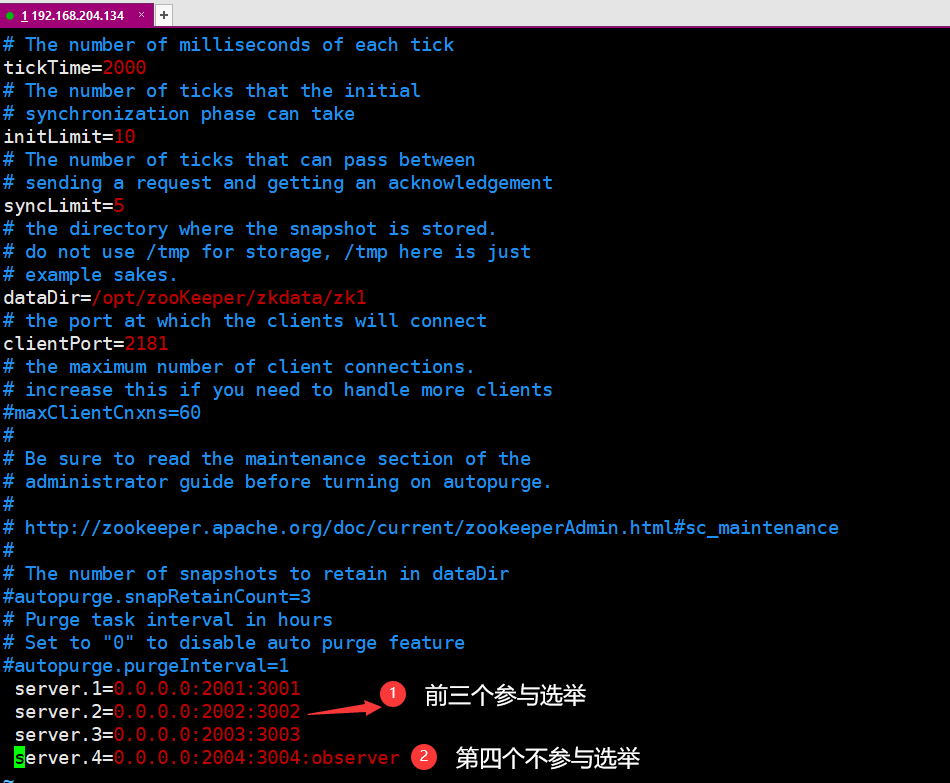
三个文件修改如下:
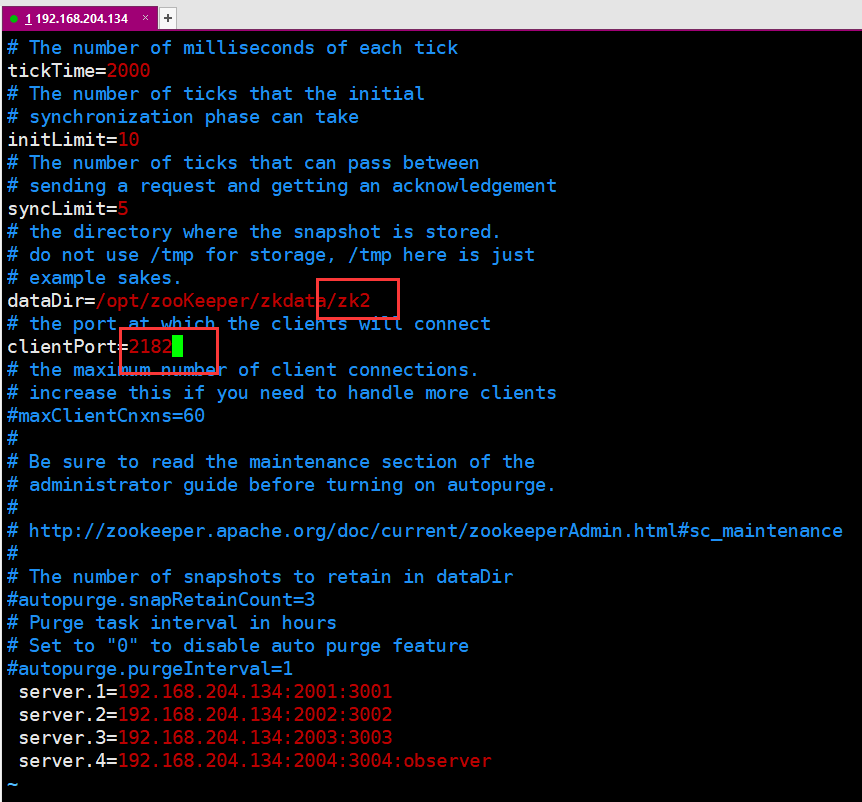
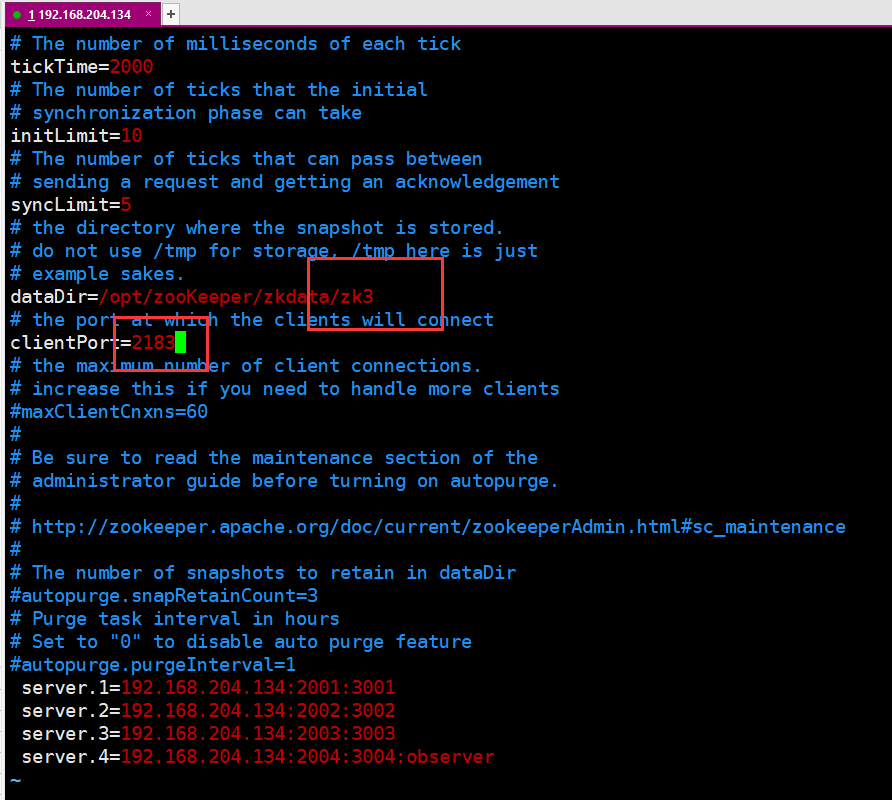
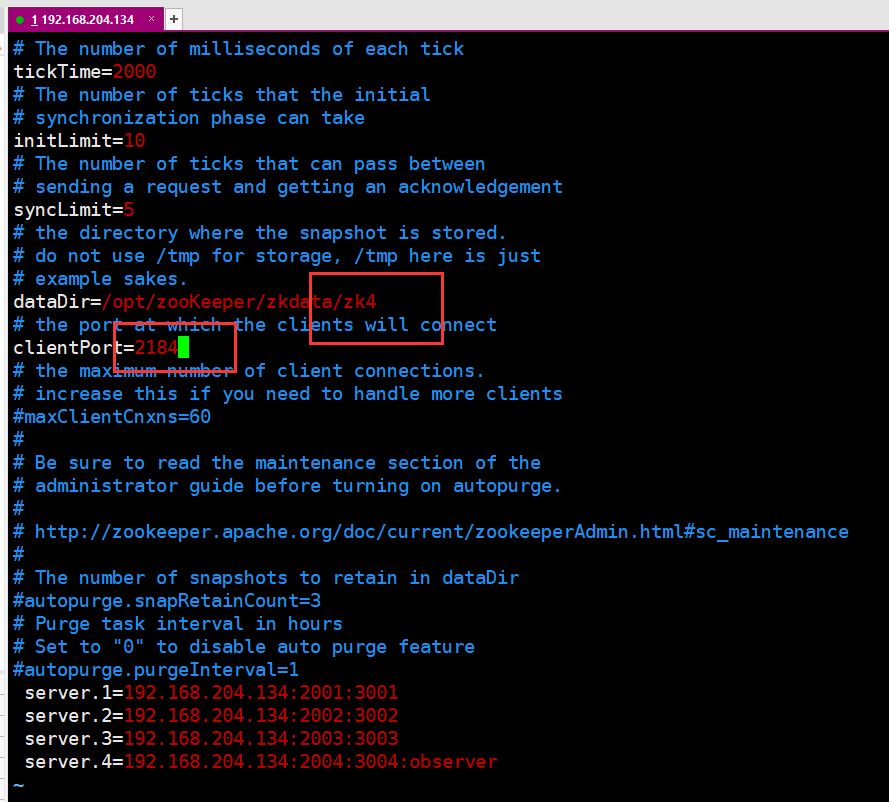
5.最后一步

集群搭建完成之后 就可以进行连接集群了
九:ZAB协议[面试重点]
1.什么是ZAB协议
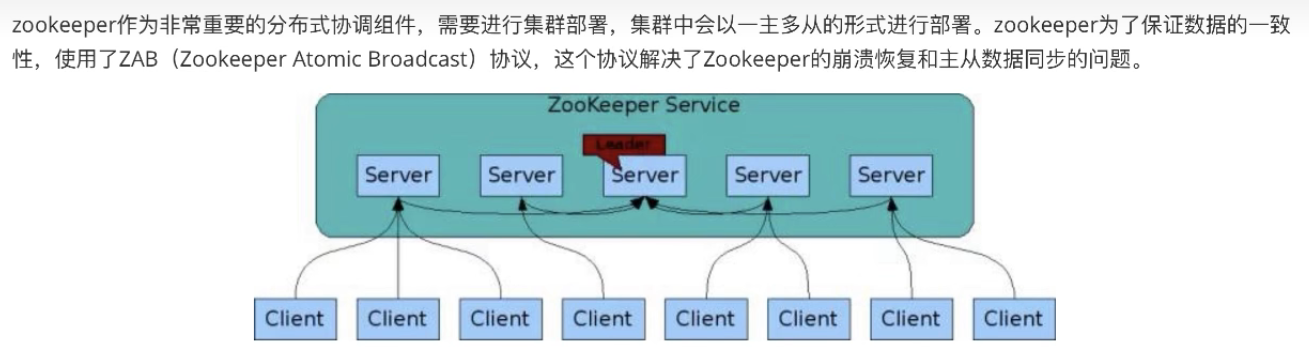
2.ZAB协议定义的四种节点状态

3.集群上线时的Leader选举过程
出现问题疑惑:
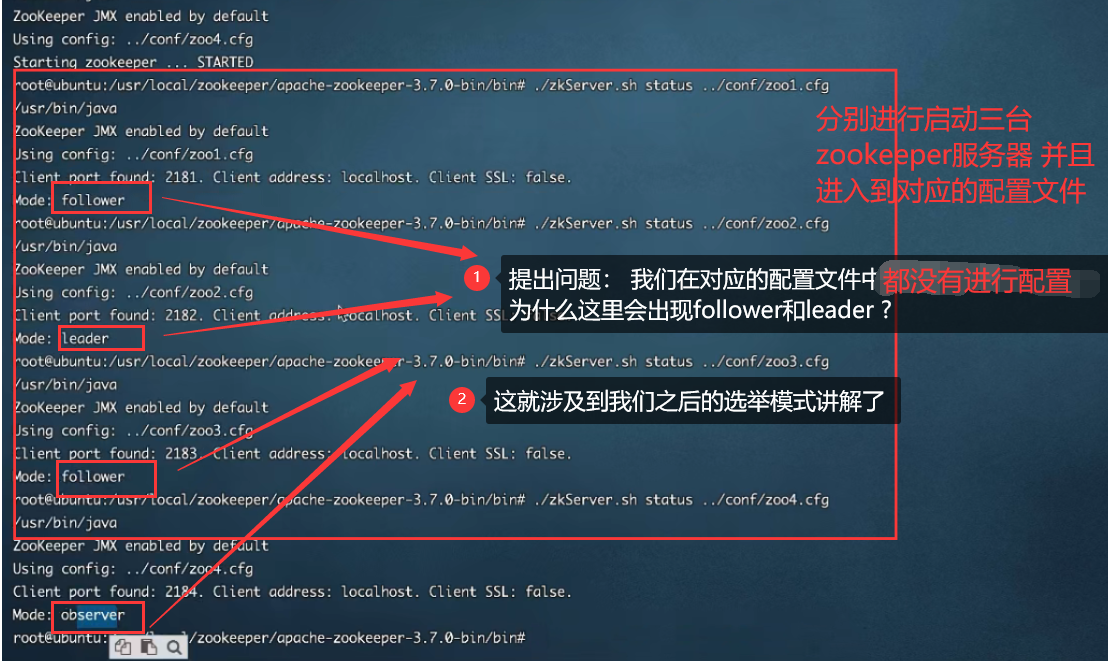
根据底层源码进行描述出Leader选举的过程【解决上述问题】:

当我们进行启动前两个服务器节点之后,选举就会开始 :
前提:
通过配置文件我们可以知道,参与选举的节点数一共有3个
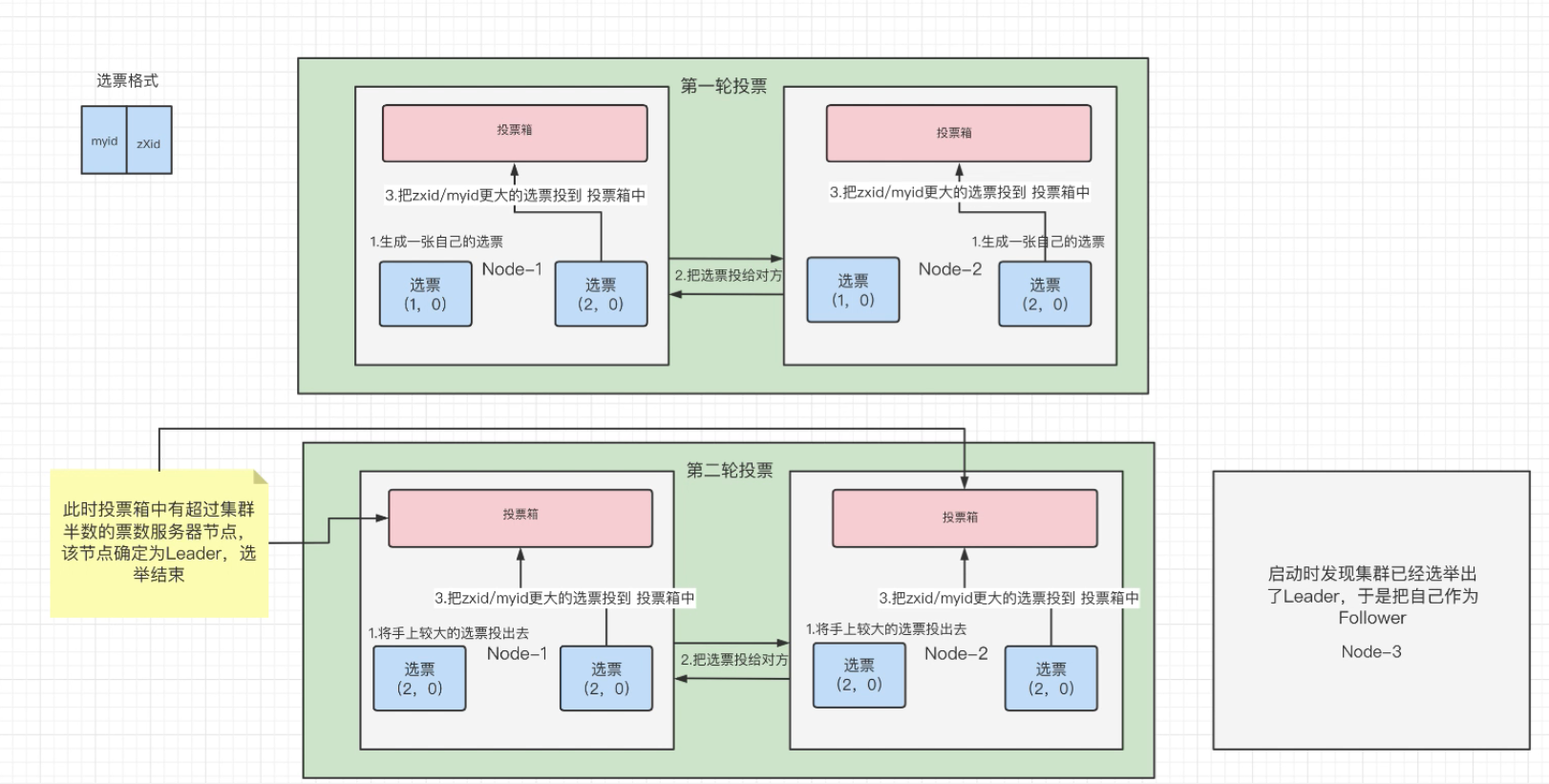
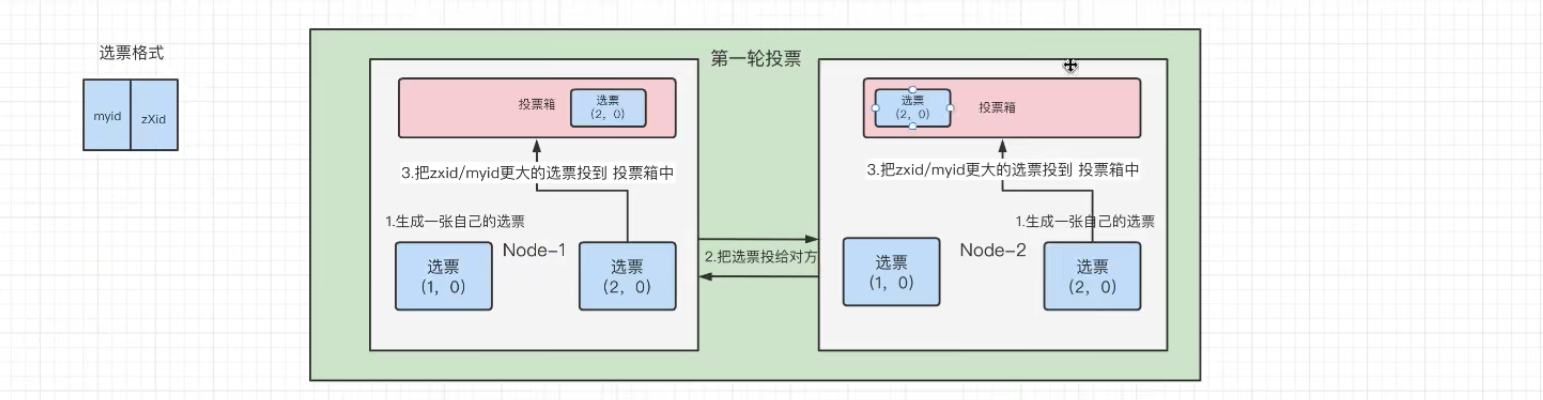
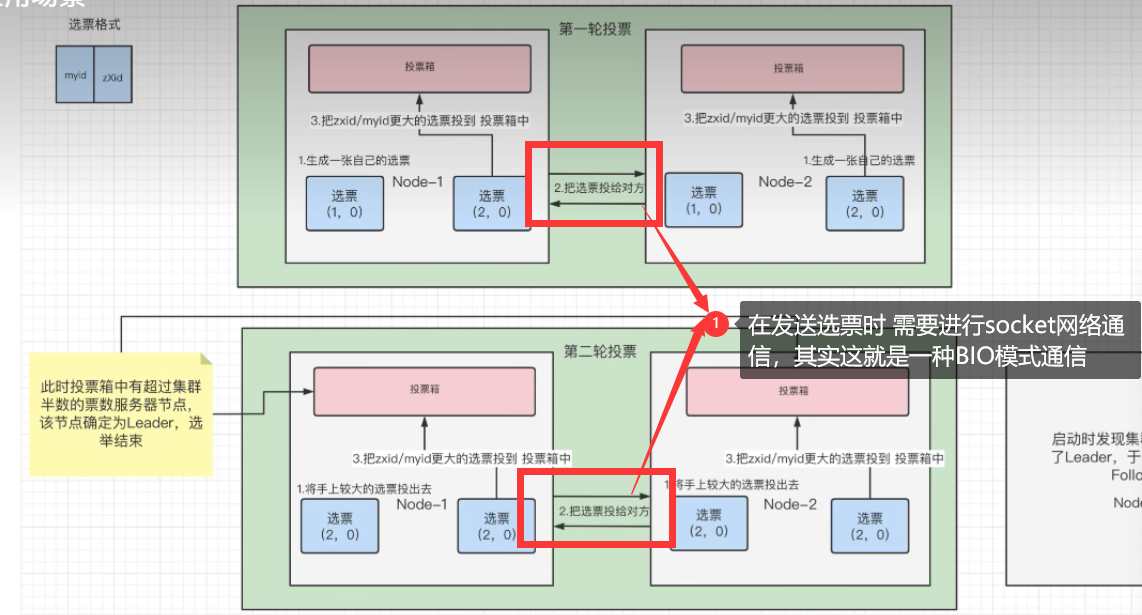
第一轮选举投票:
(1)一开始最初,每一个节点都会生成自己的一张选票。
选票格式为:(myid . zXid):
1.myid是我们在myid这个文件中进行配置的唯一标识。
在我们搭建zookeeper集群时进行的配置:节点1当时创建这个myid文件时配置的是1 节点2配置的是2。 以此类推。。。。
2.zXid为事务id。这个事务id的改变是随着对znode节点中的数据进行一系列增删改查的操作而变化的。当每增加或删除或修改或查询该
节点对应数据的时候;该事务id,zXid都会+1 ;
(2) 那么此时节点1生成的选票为(1,0),节点2生成的选票为(2,0)
(3)然后开始投票,第一轮投票,两个节点都会把自己生成的选票投递给对方。那么此时节点1和节点2都具有了(1,0)和(2,0)两张选票
(4)互相进行投票之后,开始往投票箱中进行投递选票。
投递规则如下:
1.先进行比较事务id:zXid。zXid大的优先被投递到投票箱中。
为什么选举事务id大的 ?
解释:事务id是随着我们对节点数据增删改查而逐渐+1 递增的,我们知道两个节点的数据是同步的,那么事务id大的说明数据被记录增删
改查的次数多,说明数据更加真实 更加新 !
2.当事务id一样大时,再进行比较myid。这个myid是我们配置文件时的唯一标识,在我们搭建zookeeper集群时进行的配置。
(5)当两个节点都把选票投递到投票箱之后。开始检测,发现两个节点投票箱中的票数都是1,相对于参与选举的节点数(3个)没有过半,所
以要进行第二轮选举
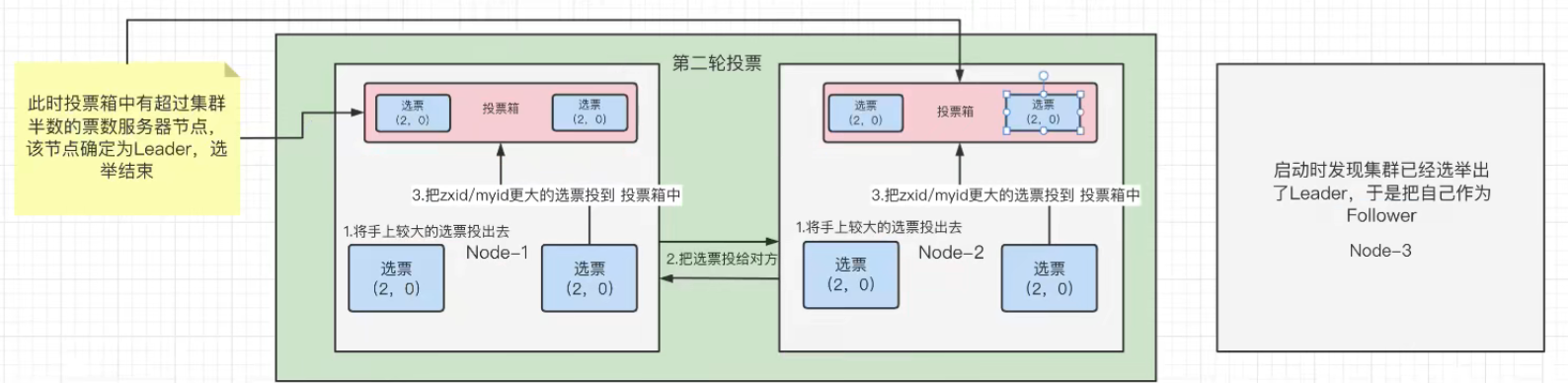
第二轮选举投票:
(1)经过第一轮投票之后。节点1拥有的票为:(1,0)和(2,0) 节点2拥有的票为:(1,0)和(2,0)
(2)第二轮投票的规则:双方节点将手上较大的选票投递出去。但是注意是节点1先投递,节点2后投递 !!
至于如何比较两张选票谁大谁小?第一轮选举投票的时候说过。
{3}然后节点2优先收到节点1的选票之后会把较大的选票投递到投票箱中,发现自己投票箱中的选票已经两张了,大于参与选举的节点
数:3个 此时停止选举,节点2为Leader。这就解释了为什么节点2一定是Leader这个问题疑惑。
(4) 经过第二轮投票之后。节点1拥有的票为:(2,0)和(2,0) 节点2拥有的票为:(2,0)和(2,0)
(5)由于已经产生Leader,即使节点3没有参与选举,节点3也会被设置为Follower。
留出细节记录:
参与Leader选举的节点服务器数最好是奇数,如果是偶数,就会容易造成半数以上的具体的值有些尴尬的难以比较 !
4.崩溃恢复时的Leader选举
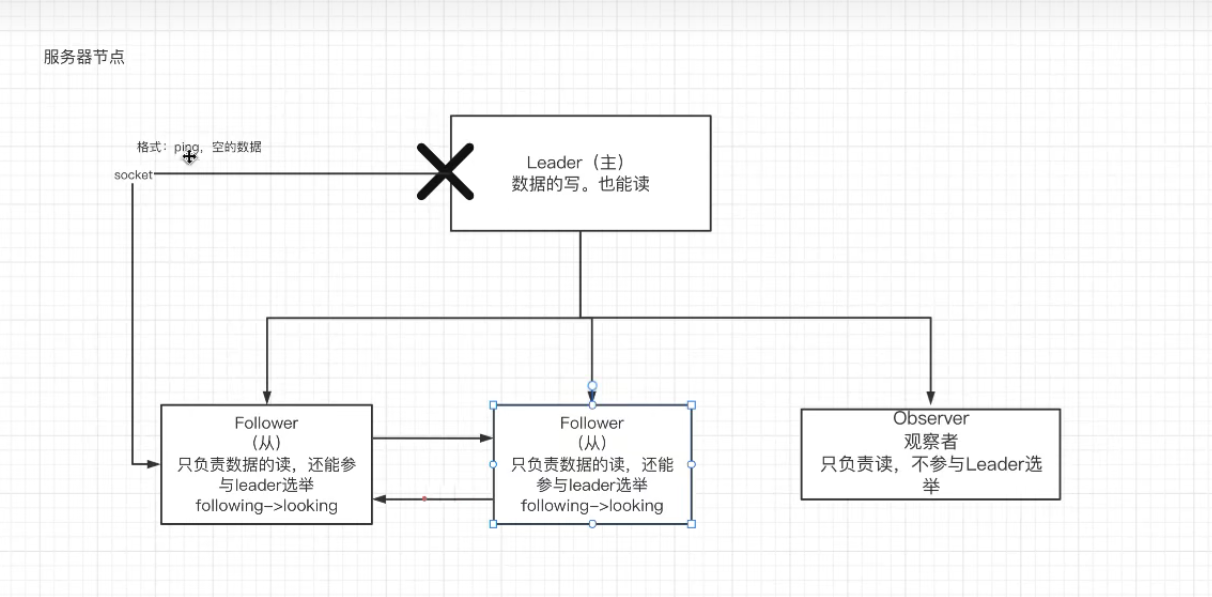
(1)当节点服务器启动,Leader选举完成之后,Leader这个主节点会周期性的不断的向各个Follower从节点发送心跳(即是ping命令,没有内容的socket(socket就是
一个数据包,用来存放传输的数据的))
(2)当这个Leader主节点有一时刻崩溃了,此时所有的Follower再去进行读取socket时就会出现异常,所有的Follower会发现socket通道已经关闭,那么此时所有
的子节点都意识到Leader这个主节点已经崩溃死亡了 !
(3)于是所有Follower子节点都会把自己的状态从following转化为looking,looking状态表示进行选举(选举的方法等效于上述所描述的启动时选举)
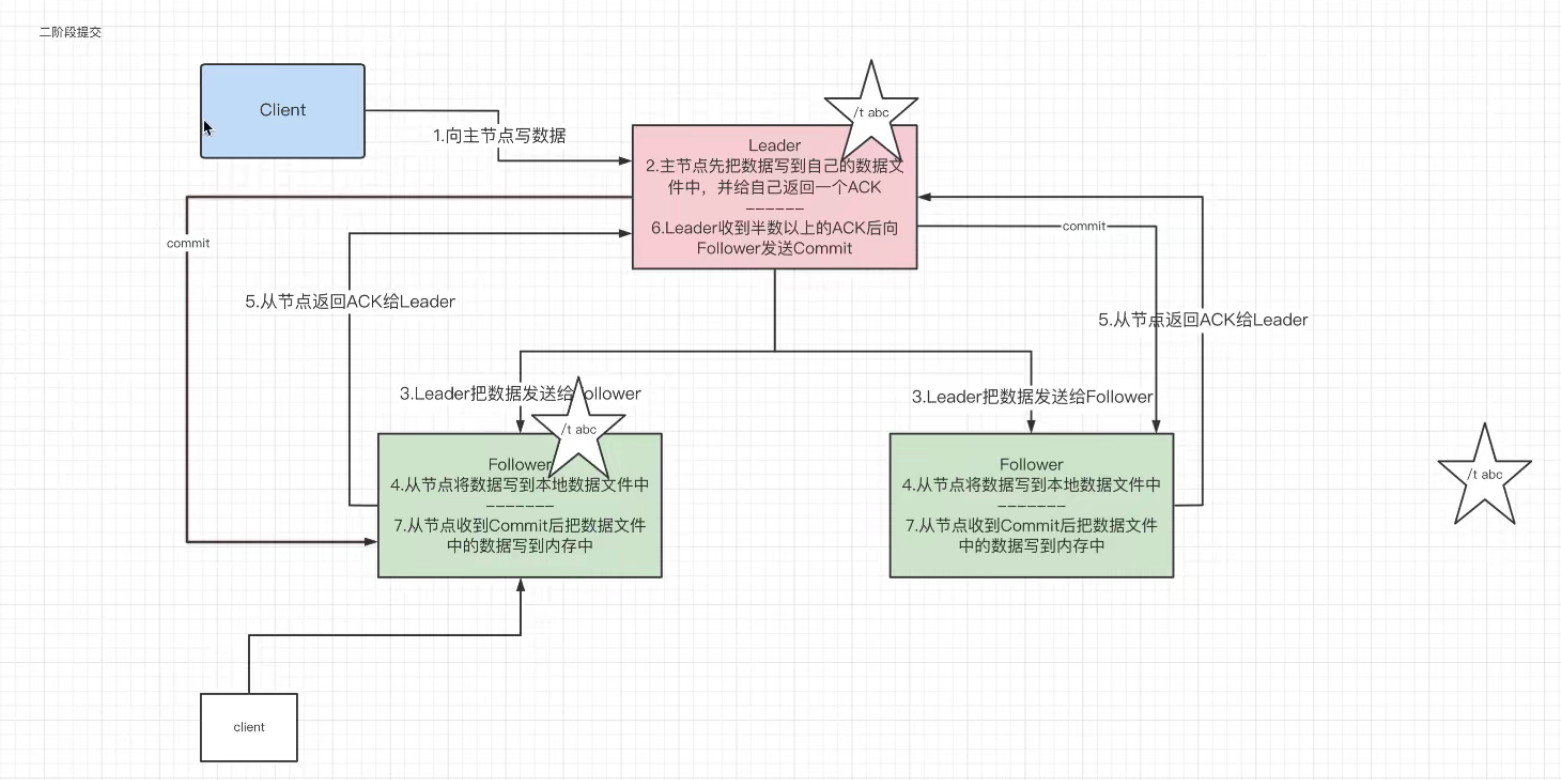
5.主从服务器之间的数据同步
前言:
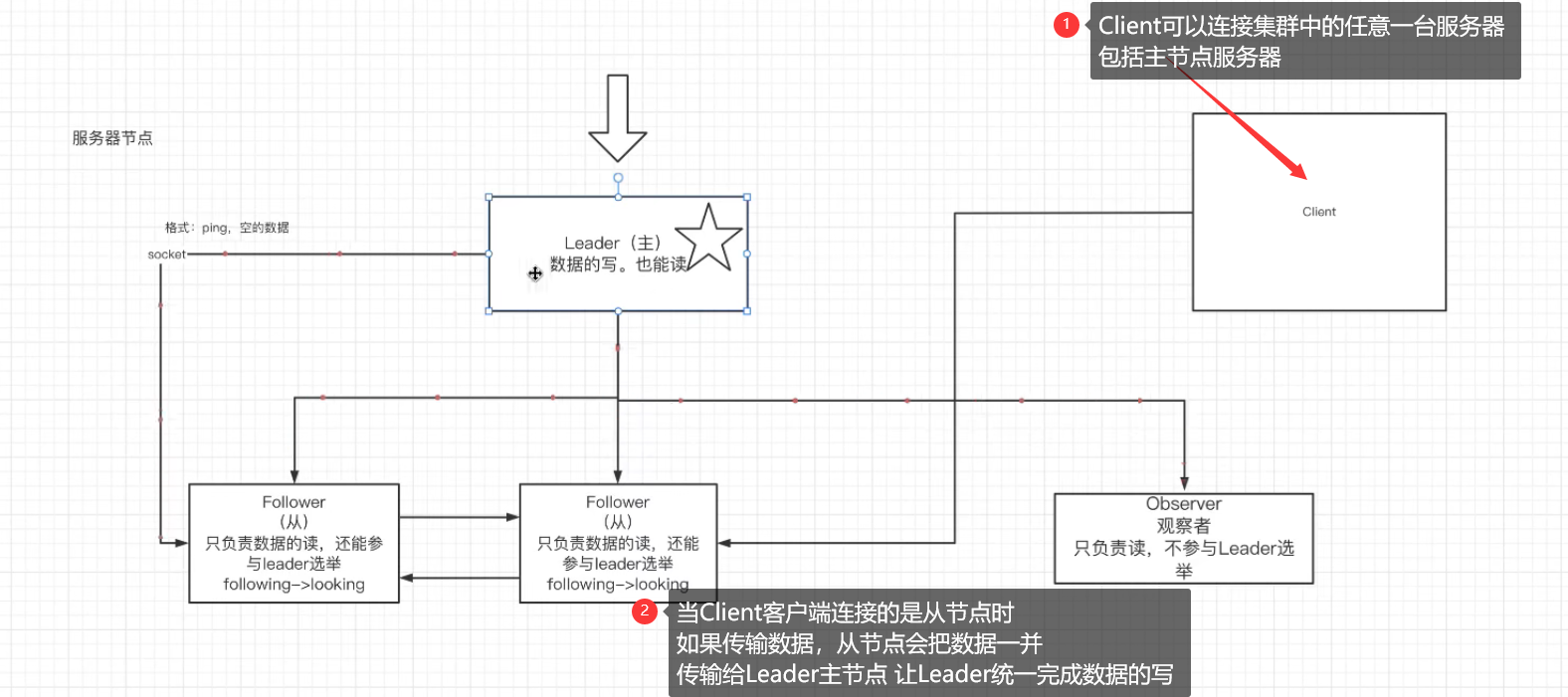
由上图可知:因此我们引出Leader写数据给各个从节点 保证主从服务器数据同步的过程:
整个主从数据同步的过程,我们称之为二阶段提交。
(1) 由于主从机制[就算Client连接从机,向从机写数据 从机也会把数据交给主机,让主机一并把数据发送给所有从机。从而保证主从一致],所以无论Client客户端
向主机还是从机传输数据都相当于向主机进行传输数据
(2)主节点会先把数据写到自己的数据文件当中,并给自己返回一个ACK
(3)Leader会把数据发送给所有Follower
(4)所有Follower从节点会把接收到Leader传输的数据写到本地的数据文件中(第一阶段提交)
此时如果一个Client客户端连接到Follower这个从节点,但是无法读取到对应传输的数据,因为数据并没有保存到内存中 !
(5) 所有Follower从节点在完成(4)之后,都进行返回一个ACK给Leader主节点
(6)Leader如果收到半数以上的ACK后,那么就向所有的Follower进行发送Commit。
对于这个半数以上我们进行解释:
首先这个半数以上,是针对于从节点数的半数以上。
其次为什么要执行(2)这个步骤,主节点也返回一个ACK给自己的呢?
假设说从节点有偶数个,如果一个从节点在将数据写到本地数据文件中时发生故障,那么就失败了,该节点就不会返回ACK了。只有一个节点返回一个ACk:你怎
么确定在半数以上?所以为了保证即使在一个从节点出现故障时,其他节点仍然保证与主机数据同步,我们就必须执行(2)来上一层保险
(7)当Follower从节点接收到Leader发送的Commit后,把数据文件中的数据写到内存中。
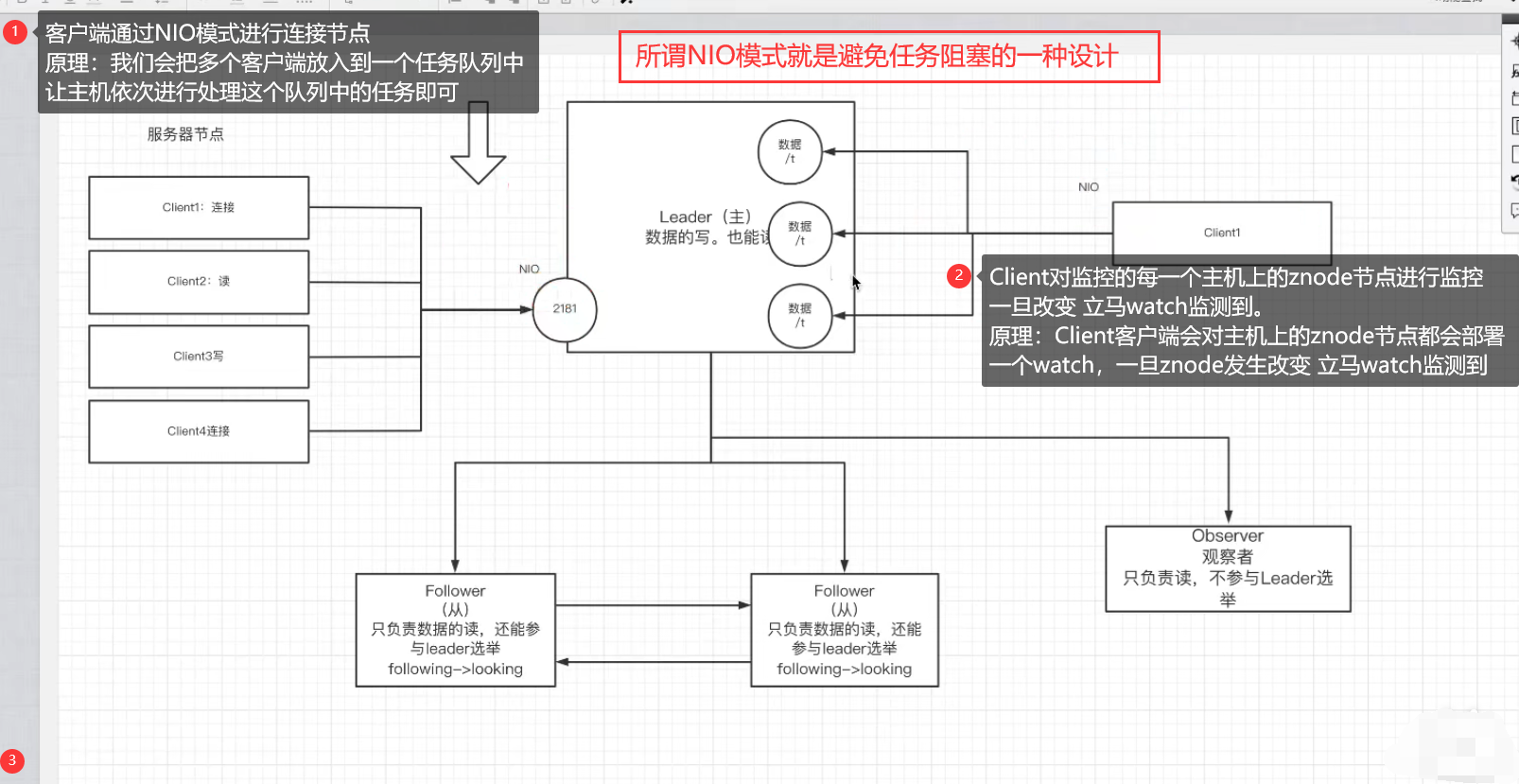
6.Zookeeper中的NIO与BIO的应用

NIO:
BIO:
十:CAP理论
1.CAP定理

CAP定理实例分析:
先说结论:CAP定理表示我们只能满足一致性,可用性和分区容错性中的两种。其中分区容错性是必须满足的,所以我们要在一致性和可用性中做出抉择。
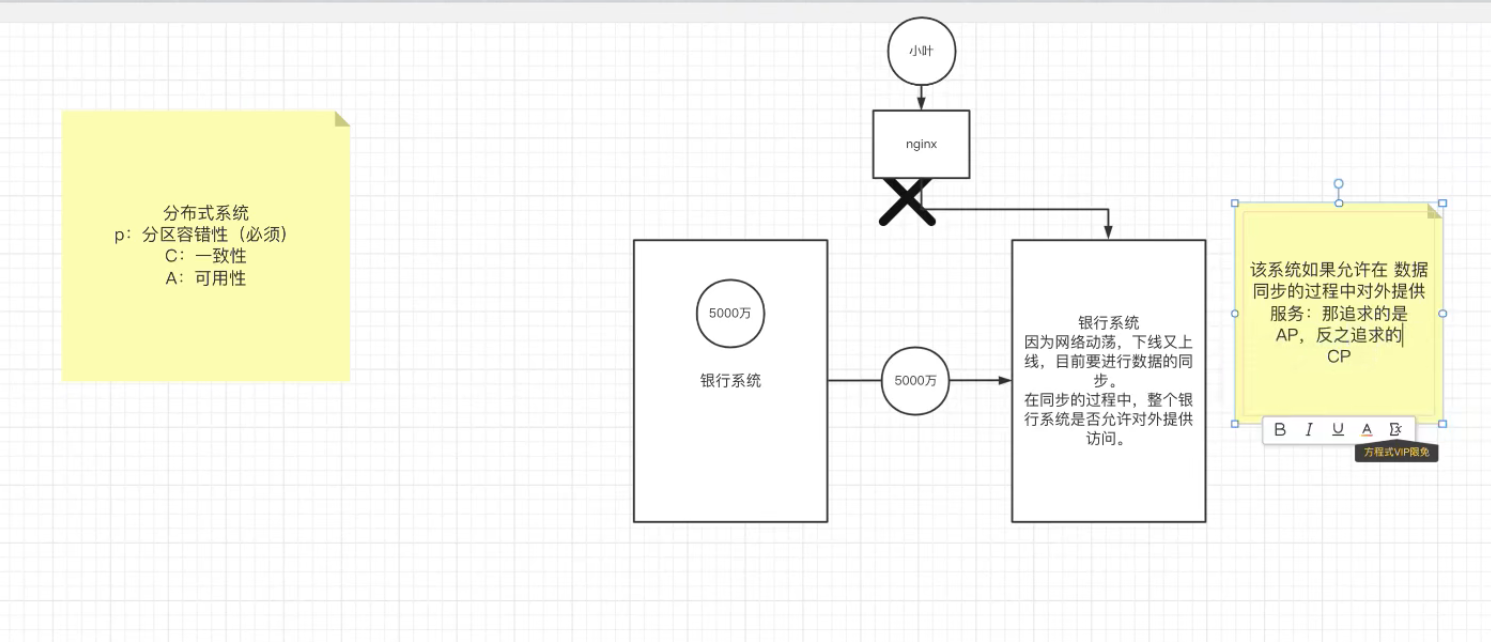
(1)银行系统是一个服务器集群,具有多台服务器 为的就是提高性能
(2)起初小叶向银行系统进行存储了5000万,就在此时这一刻,有一台服务器由于网络动荡导致下线又上线。此时又要进行数据的同步。
(3)出现一个问题:在同步数据的过程中,是否整个银行系统都允许对外提供访问?
如果允许,那么我们就默认了可用性,但是有可能数据没有同步完成导致一致性是不完全成立的。所以只能满足分区容错性和可用性这两种
如果不允许,那么我们就默认了一致性,就是为了保证数据同步完成之后再进行对外开放,那么可用性就不可以兼顾了。所以只能满足分区容错性和一致性这两种
2.BASE理论

3.ZooKeeper追求的一致性
ZooKeeper在数据同步时,追求的并不是强一致性,而是顺序一致性(事务id的单调递增)
完结 !!