运行代码的示例
下载预训练的字符嵌入和词嵌入并将它们放在数据文件夹中。
- 字符嵌入 (gigaword_chn.all.a2b.uni.ite50.vec):Google Drive或百度 Pan
- Bi-gram 嵌入 (gigaword_chn.all.a2b.bi.ite50.vec):百度盘
- Word(Lattice)嵌入(ctb.50d.vec):百度潘
获取汉字结构组件(部首)。文中使用的部首来自新华在线词典。由于版权原因,这些数据无法发布。有一种方法可以用汉语拆字字典代替,但是不一致的字符分解方法不能保证可重复性。
修改
Utils/paths.py添加预训练嵌入和数据集运行以下命令
- 微博数据集
python Utils/preprocess.py python main.py --dataset weibo
- 简历数据集
python Utils/preprocess.py python main.py --dataset resume
- Ontonotes 数据集
python Utils/preprocess.py python main.py --dataset ontonotes
- MSRA 数据集
python Utils/preprocess.py --clip_msra python main.py --dataset msra
报错gbk编码问题
报错

https://github.com/LeeSureman/Flat-Lattice-Transformer/issues/17
https://github.com/shenhuaze/weibo-ner-conll
报错

https://github.com/LeeSureman/Flat-Lattice-Transformer/issues/42
报错

删除了[3]
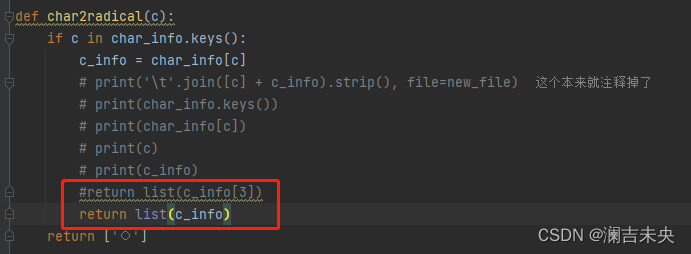
报错

添加了一行
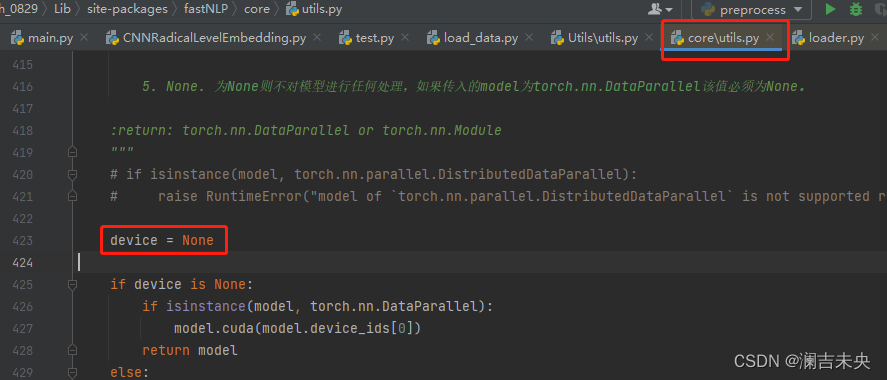
版权声明:本文为Origin2333原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。