Elastic Search 入门
前言
什么是搜索
概念:输入关键字,获取到想要的关键字相关的信息
场景:
- 站内搜索:个人博客搜索文章,电商网站搜索商品、订单等
- 互联网搜索:百度、谷歌等
为什么常用数据库不适合做搜索
数据量小,简单的搜索功能时可以用到常用的数据库,如:后台管理系统里的常见的查询
- 存储问题:数据量大的时候,比如上亿条数据的查询,就得去考虑分库分表
- 性能问题:模糊查询(如:条件为 %包包%)时用不到索引导致全表查询,查询效率相当慢
- 分词问题:当你输入关键字“LV包包”,常用数据库一般只能返回完全匹配“LV包包”的结果,而不会匹配返回“LV”或“包包”关键字的结果
什么是Lucene
Lucene是apache下的一个开源的,一套用java写的全文检索的工具包。
什么是全文检索?
从非结构化数据(不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件)中提取出的然后重新组织(分词)的信息,我们称之索引。先建立索引,再对索引进行搜索的过程就叫全文检索。什么是分词?
将采集到的文档内容切分成一个一个的词。如“I like apples , i mean fruit”,根据一定的规则后分词为“i”、“like”、“apple”、“mean”、“fruit”。
倒排索引
Lucene中对文档检索基于倒排索引实现,并将它发挥到了极致。
什么是倒排索引
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。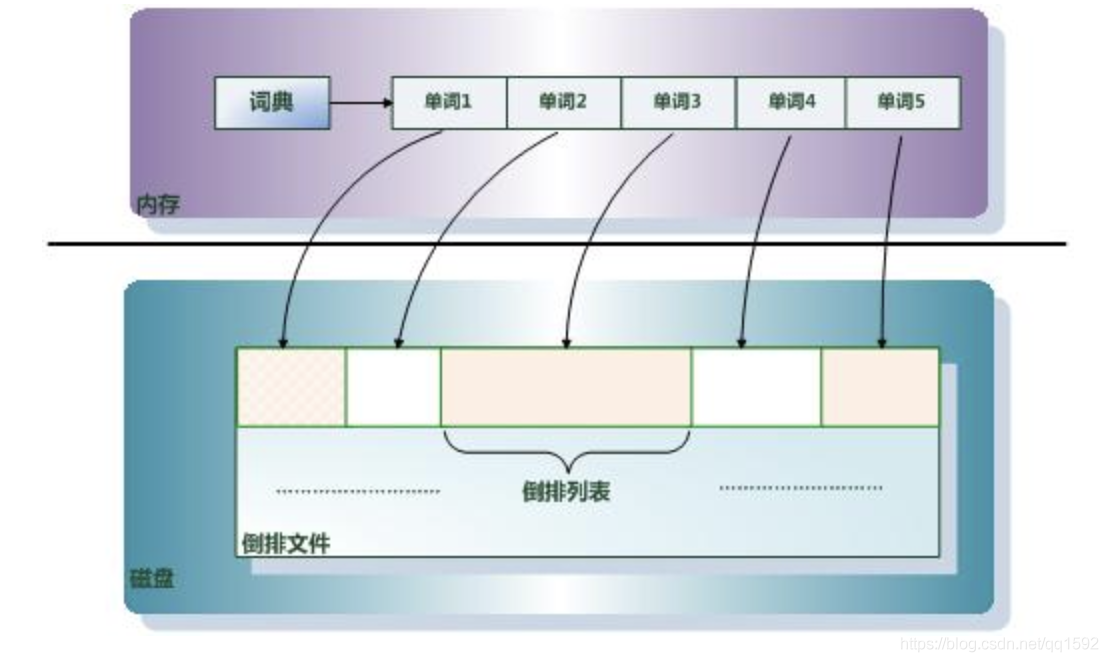
例如:
| id | 句子 |
|---|---|
| 1 | I like apples |
| 2 | I dislike apples |
| 3 | I dislike apples too |
如果要用单词作为索引,而句子的位置作为被索引的元素,那么索引就发生了倒置:
| id | 单词索引 |
|---|---|
| I | {1,2,3} |
| like | {1} |
| apples | {1,2,3} |
| dislike | {2,3} |
| too | {3} |
如果要检索I dislike apples这句话,那么就可以这么计算 : {1,2,3} ^ {2,3} ^ {1,2,3} (^是交集)
为什么使用倒排索引
当用户在淘宝上搜索关键词“小米洗衣机”时,假如只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,然后找出所有包含关键词“小米洗衣机”的文档,再根据一定的机制排序后展示给用户。
因为淘宝上的商品(或者互联网上收录在搜索引擎中的文档的数目等)是个天文数字,这样的索引结构不可能做的到实时返回给用户。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文档ID对应到关键词的映射转换为关键词到文档ID的映射,每个关键词都对应着一系列的文档,这些文档中都出现这个关键词。最后再通过文档ID找到对应的详细文档。
什么是Elastic Search
官方定义
Elasticsearch 是一个分布式的、开源的搜索分析引擎,支持各种数据类型,包括文本、数字、地理、结构化、非结构化。
与Lucene的关系
- Elastic Search基于lucene,封装了许多lucene底层功能,提供了分布式的服务、简单易用的restful API接口和许多语言的客户端。

ES核心概念
- 近实时(NRT Near RealTime)
写数据时:过1秒才会被搜索到,因为内部在分词、录入索引。
es搜索时:搜索和分析数据需要秒级出结果。 - 集群(Cluster)
包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。
默认集群名是“elasticsearch”,同一网络,同一集群名下的es实例会自动组成集群。 - 节点(Node)
一个es实例即为一个节点。 - 索引(Index)
即拥有相似文档的集合 - 类型(Type)
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。7.x版本正式被去除。 - 文档(Document)
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。
多个document存储于一个索引(Index)中。 - 映射(Mapping)
定义索引中的字段的名称;
定义字段的数据类型,比如字符串、数字、布尔;
字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等。
与关系型数据库核心概念对比
| Elasticsearch | 关系型数据库(如Mysql) |
|---|---|
| 索引Index | 数据库Database |
| 类型Type | 表Table |
| 文档Document | 数据行Row |
| 字段Field | 数据列Column |
| 映射Mapping | 约束 Schema |
ES使用
正常启动
以下是基于linux环境下安装好的elastic search 5.5.1版本(默认端口9200):
curl localhost:9200
成功的返回结果
{
"name" : "g8MxBRF",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Y9ByiiOkRzGNYG91pw7ARA",
"version" : {
"number" : "5.5.1",
"build_hash" : "19c13d0",
"build_date" : "2017-07-18T20:44:24.823Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
索引
新增
curl -X PUT 'localhost:9200/city'
返回成功结果:里面的acknowledged字段表示操作成功
{"acknowledged":true,"shards_acknowledged":true}
删除
curl -X DELETE 'localhost:9200/city'
返回成功结果
{"acknowledged":true}
增删改查
RESTful接口URL的格式:
http://localhost:9200/<index>/<type>/[<id>]
ES增加
往city索引中添加shenzhen城市:
uri地址的 ? 后添加的的 pretty 参数,会让返回结果以工整方式美化
curl -H "Content-Type: application/json" -XPUT 'http://localhost:9200/city/shenzhen/1?pretty' -d '{"name":"ShenZhen","area":["NanShan","FuTian"]}'
返回成功结果
{
"_index" : "city",
"_type" : "shenzhen",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
常见问题:
1、uri里没添加id,提示错误:
No handler found for uri [/city/shenzhen/?pretty] and method [PUT]
原因:
使用put方法时id是必填的,使用post方法可以让es自动生成id
解决:
使用post方法
curl -H "Content-Type: application/json" -XPOST 'http://localhost:9200/city/shenzhen/?pretty' -d '{"name":"ShenZhen","area":["NanShan","FuTian"]}'
或者 put方法uri加上id值
curl -H "Content-Type: application/json" -XPUT 'http://localhost:9200/city/shenzhen/1?pretty' -d '{"name":"ShenZhen","area":["NanShan","FuTian"]}'
ES删除
删除id为1的document
curl -XDELETE 'http://localhost:9200/city/shenzhen/1?pretty'
返回结果
{
"found" : true,
"_index" : "city",
"_type" : "shenzhen",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}
ES查询
官方文档search基本用法:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search.html
简单查询语法
GET /<target>/_search
GET /_search
POST /<target>/_search
POST /_search
query基本匹配查询关键字说明
| 关键字 | 说明 |
|---|---|
| match_all | 查询简单的 匹配所有文档。在没有指定查询方式时,它是默认的查询 |
| match | 用于全文搜索或者精确查询,如果在一个精确值的字段上使用它, 例如数字、日期、布尔或者一个 not_analyzed 字符串字段,那么它将会精确匹配给定的值 |
| range | 查询找出那些落在指定区间内的数字或者时间 gt 大于;gte 大于等于;lt 小于;lte 小于等于 |
| term | 被用于精确值 匹配 |
| terms | terms 查询和 term 查询一样,但它允许你指定多值进行匹配 |
| exists | 查找那些指定字段中有值的文档 |
| missing | 查找那些指定字段中无值的文档 |
| must | 多组合查询 必须匹配这些条件才能被包含进来 |
| must_not | 多组合查询 必须不匹配这些条件才能被包含进来 |
| should | 多组合查询 如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分 |
| filter | 多组合查询 这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档 |
例子
查询索引为city前20行,匹配字段为“area”,值包含“NanShan”的文档
curl -X GET "localhost:9200/city/_search?from=0&size=20&pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"area": "NanShan"
}
}
}
'
查询结果:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.25811607,
"hits" : [
{
"_index" : "city",
"_type" : "guangzhou",
"_id" : "AXrce1sUTV0OiJf0oUac",
"_score" : 0.25811607,
"_source" : {
"name" : "ShenZhen",
"area" : [
"NanShan",
"FuTian"
]
}
}
]
}
}
返回结果字段解释
| 字段 | 说明 |
|---|---|
| took | 耗费了几毫秒 |
| timed_out | 是否超时 |
| _shards | 数据拆成5个分片,对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以),所以total和successful会是5; |
| hits | 查询的所有结果 |
| hits里面的 total | 查询结果的数量(多少个 document) |
| max_score | score的含义就是document对于一个search的相关度的匹配分数,越相关、就越匹配,分数也越高; |
| hits.hits(hits里面包含了hits) | 包含了匹配搜索的document的详细数据-----里面的hits包含的是和每个文档相关的数据,外面的hits有的数据是统计数据,如total等--------一般都有两个hits嵌套 |
| _index | 该文档所属的index |
| _type | 该文档所属的type |
| _id | 该文档的id |
| _source | 具体的内容,即存储的json串 |
ES索引使用tips
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 对于String类型的字段,不需要analysis(分词)的也需要明确定义出来,因为默认
也是会analysis的 - 选择有规律的ID很重要,随机性太大的ID(比如UUID)不利于查询
参考文献:
https://blog.csdn.net/alex_xfboy/article/details/83052206
https://www.cnblogs.com/wupeixuan/p/12514843.html
https://www.cnblogs.com/momoyan/p/11616487.html#auto_id_11