数据结构和算法系列共八篇
- 数据结构和算法1-介绍
- 数据结构和算法2-线性-链
- 数据结构和算法3-线性-栈
- 数据结构和算法4-线性-队列
- 数据结构和算法5-非线性-树
- 数据结构和算法6-非线性-图
- 数据结构和算法7-搜索
- 数据结构和算法8-排序
先介绍个工具
1.顺序表
常见的查找方式
- 顺序查找
- 二分查找
顺序查找和折半查找与底层采用什么存储结构没有关系,以数组方式来演示
1-1.顺序查找
顺序查找又叫线性查找,是最基本的查找技术,他的查找过程是:
从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若是相等,则成功,找到所查记录;
如果直到最后(或第一个)记录,其依旧不等,则查找失败
思想:逐个比较,时间复杂度T(n)=O(n);空间复杂度S(n)=O(1);
public class LinearSeqSearch {
public static void main(String[] args) {
// 无序的
int[] data = {1, 4, 3, 6, 5, 2, 7};
// int checkNum = 7;
int checkNum = 100;
int index = find(checkNum, data);
if (index < 0) {
System.out.println("没有找到:"+ checkNum);
}else {
System.out.println("坐标:"+ index);
}
}
private static int find(int check, int[] data) {
for (int index = 0; index < data.length; index++) {
if (check == data[index]) {
return index;
}
}
return -1;
}
}
1-2.二分查找
二分查找,又叫折半查找。使用这是由前提条件的,那就是数据是有序的。
两种方式:
- 非递归:空间复杂度S(n)=O(1);
- 递归:调了logn次方法,所以空间复杂度是O(logn)
时间复杂度T(n)=O(logn)
缺点
不过由于折半查找的前提是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,这样的算法是比较好的。
但是对于需要频繁插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,不建议使用。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;
否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
非递归实现
blic class LinearBinarySearch {
public static void main(String[] args) {
// 折半查找的数据要是有序的
int[] data = {1, 2, 3, 4, 5, 6, 7, 10};
// int checkNum = 6;
int checkNum = 9;
// 非递归
int index = findByBinaryNoRec(checkNum, data);
if (index < 0) {
System.out.println("没有找到:" + checkNum);
} else {
System.out.println("坐标:" + index);
}
}
private static int findByBinaryNoRec(int check, int[] data) {
int minIndex = 0;
int maxIndex = data.length - 1;
while (maxIndex > minIndex) {
int midIndex = (maxIndex + minIndex) / 2;
if (data[midIndex] == check) {
return midIndex;
} else if (data[midIndex] > check) {
// 注意着要-1,因为中间的值的已经判断过了
maxIndex = midIndex - 1;
} else {
// 注意着要+1,因为中间的值的已经判断过了
minIndex = midIndex + 1;
}
}
return -1;
}
}
递归实现
public class LinearBinarySearch {
public static void main(String[] args) {
// 折半查找的数据要是有序的
int[] data = {1, 2, 3, 4, 5, 6, 7, 10};
// int checkNum = 6;
int checkNum = 9;
// 递归
int index = findByBinaryRec(checkNum, data);
if (index < 0) {
System.out.println("没有找到:" + checkNum);
} else {
System.out.println("坐标:" + index);
}
}
private static int findByBinaryRec(int check, int[] data) {
return findByBinaryRec(0, data.length - 1, check, data);
}
private static int findByBinaryRec(int minIndex, int maxIndex, int check, int[] data) {
if (minIndex >= maxIndex) {
return -1;
}
int midIndex = (minIndex + maxIndex) / 2;
if (data[midIndex] == check) {
return midIndex;
} else if (data[midIndex] > check) {
return findByBinaryRec(minIndex, midIndex - 1, check, data);
} else {
return findByBinaryRec(midIndex + 1, maxIndex, check, data);
}
}
}
1-3.插值法
mid=(high+low)/2 = low + (high-low)/2 这是等价的。但是这个1/2是固定的,不好。可以进化下,根据数据的特点,动态进行调幅。
演变为mid = low + (key - a[low]) / (a[high] - a[low])*(high - low) 来计算。
只要将上面的二分法的,mid修改下即可
而插值查找则比较灵活,并不是简单的从中间进行的,它是根据我们需要查询的值的渐进进行搜索的.
插值查找的不同点在于每一次并不是从中间切分,而是根据离所求值的距离进行搜索的.
对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
时间复杂度:平均情况O(loglog(n)),最坏O(log(n))
public class LinearInsertSearch {
public static void main(String[] args) {
// 折半查找的数据要是有序的
int[] data = {1, 2, 3, 4, 5, 6, 7, 10};
int checkNum = 6;
// int checkNum = 9;
// 非递归
int index = findByBinaryNoRec(checkNum, data);
// 递归
// int index = findByBinaryRec(checkNum, data);
if (index < 0) {
System.out.println("没有找到:" + checkNum);
} else {
System.out.println("坐标:" + index);
}
}
private static int findByBinaryRec(int check, int[] data) {
return findByBinaryRec(0, data.length - 1, check, data);
}
private static int findByBinaryRec(int minIndex, int maxIndex, int check, int[] data) {
if (minIndex >= maxIndex) {
return -1;
}
// int midIndex = (minIndex + maxIndex) / 2;
int midIndex = minIndex + (check - data[minIndex]) / (data[maxIndex] - data[minIndex]) * (maxIndex - minIndex);
if (data[midIndex] == check) {
return midIndex;
} else if (data[midIndex] > check) {
return findByBinaryRec(minIndex, midIndex - 1, check, data);
} else {
return findByBinaryRec(midIndex + 1, maxIndex, check, data);
}
}
private static int findByBinaryNoRec(int check, int[] data) {
int minIndex = 0;
int maxIndex = data.length - 1;
while (maxIndex > minIndex) {
// int midIndex = (maxIndex + minIndex) / 2;
int midIndex = minIndex + (check - data[minIndex]) / (data[maxIndex] - data[minIndex]) * (maxIndex - minIndex);
if (data[midIndex] == check) {
return midIndex;
} else if (data[midIndex] > check) {
// 注意着要-1,因为中间的值的已经判断过了
maxIndex = midIndex - 1;
} else {
// 注意着要+1,因为中间的值的已经判断过了
minIndex = midIndex + 1;
}
}
return -1;
}
}
2.查找树
查找树、二叉搜索树、二叉排序树(BST binary search/sort tree)
主要是这个树又可以用来查找,也可以变成有序的。
查找树是树的一种,具有小的在左边,大的在右边的树,才叫查找树,下图几种都叫查找树。
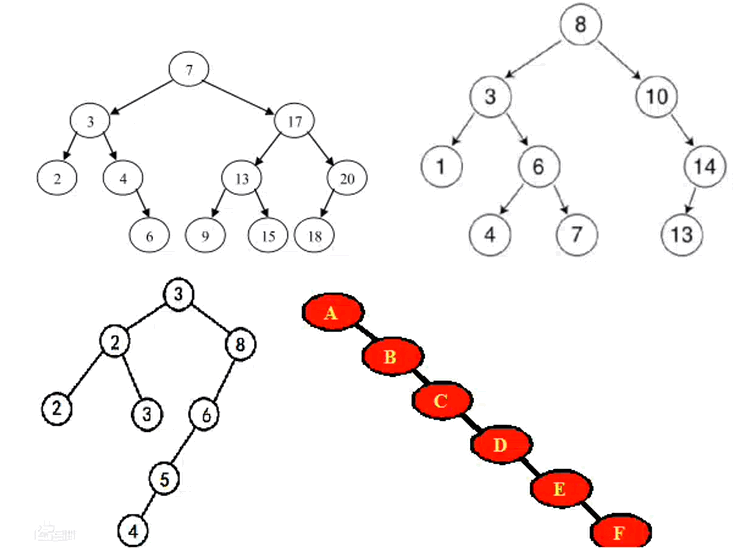
2-1.平衡二叉树
平衡二叉树(self-balancing binary search tree),又称为AVL树。
特点
- 左右两个子树的高度差(平衡因子)的绝对值不超过1, 子树的子树也要保证这个关系。
平衡因子: node的左和右树的高度相差值
平衡二叉的常用实现方法包括:AVL、红黑树、替罪羊树、Treap、伸展树。
目的: 减少查询次数,提高查询速度
如下图:(由非平衡二叉树转化为平衡二叉树)
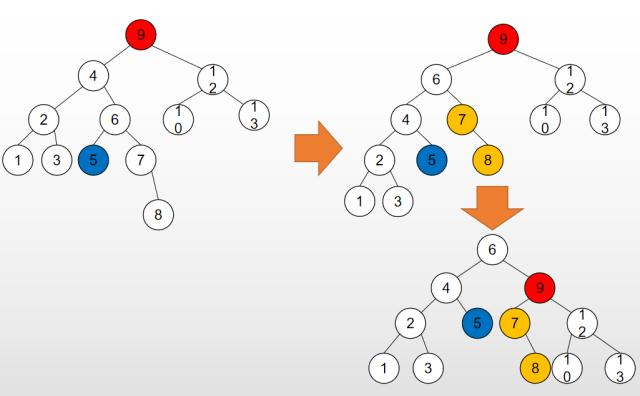
2-2.红黑树
Red-Black Tree 简称 R-B Tree。也是平衡二叉树,每个节点上都存储位颜色,红或黑。
特点:
- 每个节点不是黑就是红
- 根是黑的
- 叶子是NIl是黑的
- 一个节点是红的,那么子节点必是黑的
- 从一个节点到子孙节点所有路径包含相同数目的黑节点
保证了没有一条路径比其他路径长2倍
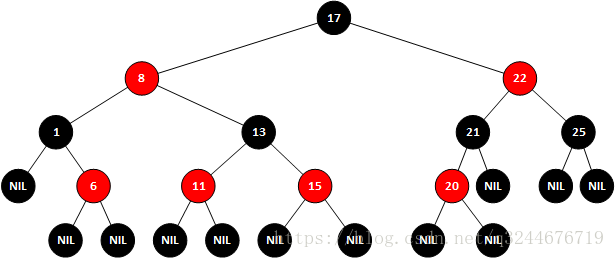
有兴趣的可以参考这篇博客
红黑树使用很广泛,存储的数据是有序的,时间复杂度是O(logN),效率高
java中的TreeSet和TreeMap都是使用红黑树实现的
linux的内存管理也是
2-3.B树
B树,相对于二叉树,叉树多了,可以降低树的升读,提交查询效率
B树是因为文件系统而发展起来的,大量数据放放磁盘中,数据量太大,不能一次加载进去,需要需要索引,来提高访问速度,减少时间。
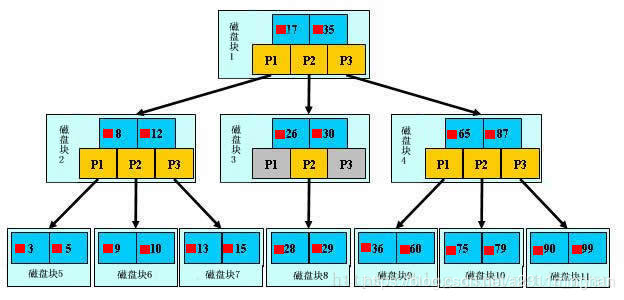
有兴趣的可以参考这篇博客
2-4.B+树
B+树是B树的变种,有着比B树更高的查询效率。
特点
- 每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小,自小而大顺序链接。
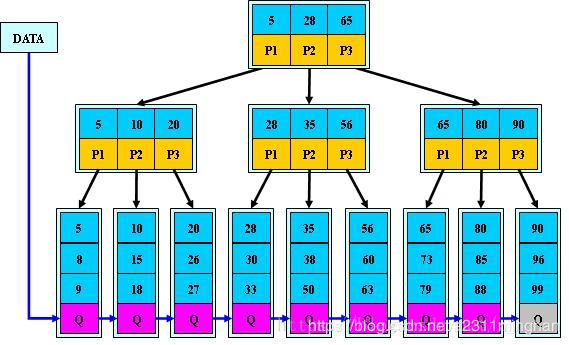
B+树通常有两个指针,一个指向根结点,另一个指向关键字最小的叶子结点。因些,对于B+树进行查找两种运算:一种是从最小关键字起顺序查找,另一种是从根结点开始,进行随机查找。
有兴趣的可以参考这篇博客
数据库索引默认就是使用B+树
2-5.B*树
B*是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
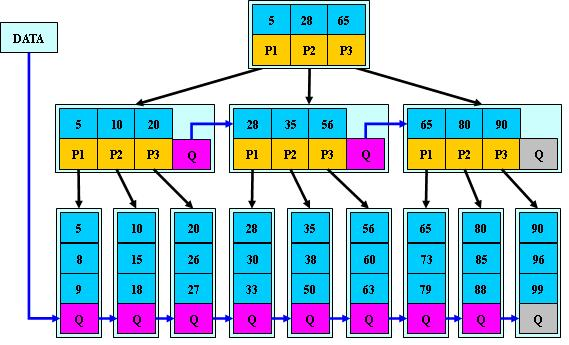
3.hash表
前面的查找都要根给定的值比较,来定位。
有没不需要比较的方法,直接定位到存储位置呢?
3-1.hash表结构
hashtable也叫散列表。查询、插入速度快
流行方案:顺序表+链表
顺序表:可以很快的定位
链表:hash冲突时使用
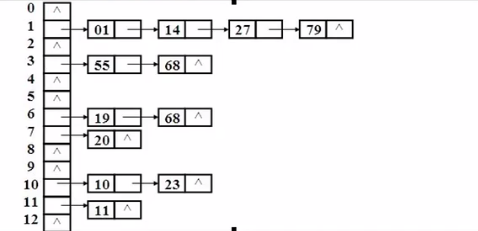
3-2.哈希码
- int取自身
- double 源码,挺复杂的还有位运算和取或
- String
- 具体的类,但是属性是基本类型,终归是可以得到一个整数的。(idea、eclipse工具自动生成)
想了解,自己去类中查看hashCode方法
3-3.hash冲突
填装因子: 哈希表的长度和表中的记录数的比例
装填因子=表中的记录数/哈希表的长度 (HashMap中用的装填因子是0.75)
一般情况下,装填因子在0.5左右,hash的性能能够达到最优
哈希函数的选择
- 直接定址法
- 平方取中发
- 折叠法
- 除留取余法(y=x%11)
hash函数解决冲突的方法有以下几个常用的方法
- 开放定制法
- 链地址法
- 公共溢出区法
建立一个特殊存储空间,专门存放冲突的数据。此种方法适用于数据和冲突较少的情况。
- 再散列法
准备若干个hash函数,如果使用第一个hash函数发生了冲突,就使用第二个hash函数,第二个也冲突,使用第三个……
4.进入一步深造
下一步如何再深造呢?
去看java的
TreeSet与TreeMap,HashSet、HashMap等源码
TreeSet与TreeMap
- java中的TreeSet和TreeMap的底层就是使用了红黑树。
- 添加节点的过程很通过旋转等方法,使得每次添加数据后得到的都是平衡树;
- TreeSet给你创建了一个TreeMap,放到了Map的key里面,而map的value都是一个新的Object对象
HashSet和HashMap
- HashSet的底层使用HashMap,使用了一个是哈希表。
- JDK1.7的HashMap是一个table数组+链表实现的存储结构
- JDK.18的HashMap当链表的存储数据个数大于等于8的时候,不再用链表存储,而是采用的红黑树存储。
5.推荐
能读到文章最后,首先得谢谢您对本文的肯定,你的肯定是对博主最大的鼓励。
你觉本文有帮助,那就点个?
你有疑问,那就留下您的?
怕把我弄丢了,那就把我⭐
电脑不方便看,那就把发到你?