目录
1、mysqldump.exe
mysqldump.exe文件是MySQL的一个命令文件,在安装目录MySQL Server 5.6\bin下可以找到。
此次分享的两个例子都是基于mysqldump命令,关于该命令的具体作用和参数可自行百度查阅材料。
笔者亲测,可以在没有安装MySQL的电脑使用该命令,只需将mysqldump.exe文件下载/拷贝到电脑中即可。
下面我通过一个简单的例子来简单演示下mysqldump的使用。
首先,先在测试数据库建一个表,插入数据:
create table test.t_dict(
dict_code varchar(32) not null,
dict_name varchar(64) not null,
PRIMARY KEY (dict_code) USING BTREE
);
insert into test.t_dict(dict_code,dict_name) values('test1','测试1');
insert into test.t_dict(dict_code,dict_name) values('test2','测试2');假设我们的mysqldump.exe文件在D盘根目录下,进入cmd,执行以下命令:
mysqldump -h你的数据库服务器IP -u账号 -p密码 --lock-tables=0 --compact --no-create-info --skip-comments test t_dict > D:/t_dict_20210721.sql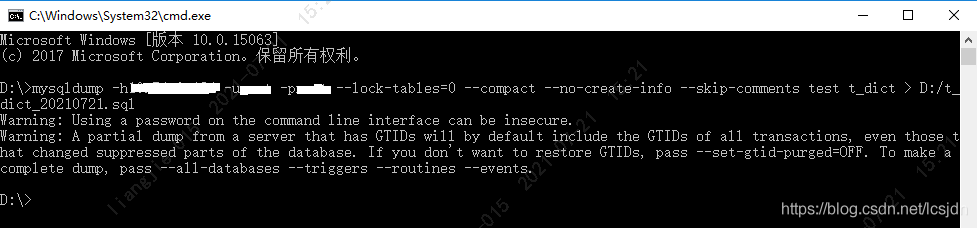
执行完毕后,可以在D盘找到生成的SQL文件:t_dict_20210721.sql
打开文件:
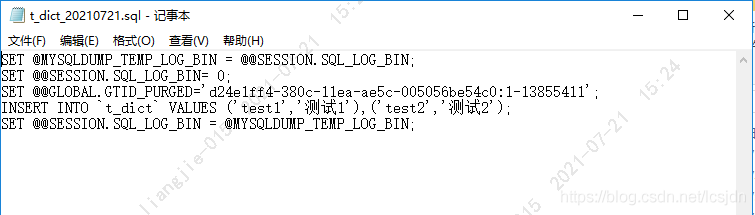
2、Java实现批量生成SQL脚本
场景:系统上线,需要同步数据库的数据到生产数据库,除了第一次是全量同步,后续的迭代都是增量,主要由于开发/测试环境有很多测试数据,如果全量同步,会造成数据异常,因此每次发布需要找出当次发布的数据,精准同步数据。
以test.t_dict为例,假如本次发布只需要更新dict_code='test1'这条记录,我们其实只需生成该条记录即可,最主要是使用mysqldump命令中的-w参数,参数值就是where条件,以这个为例子,我们可以在cmd单独执行下:
mysqldump -h你的MySQL数据库IP -u账号 -p密码 --lock-tables=0 --compact --no-create-info --skip-comments test t_dict -w"dict_code='test1'" > D:/t_dict_20210721.sql
以上就是基本原理。
但实际中我们是要同步不同表的数据,在这种情况下,使用mysqldump命令每次只能生成一张表的数据。
基本思路:首先整理所有查询SQL的语句放到指定文件,Java读取文件,存到字符串,将语句分拆成单独的每一条查询SQL,然后循环使用命令行生成每张表的insert脚本,最后将所有insert脚本汇总。
以下是完整实现代码:
package com.util;
import org.apache.commons.lang3.StringUtils;
public class MySQLUtil {
public static void main(String argsp[])
{
String basepath =MySQLUtil.class.getResource("").toString();
String ssql_file_path=basepath.replace("file:/", "")+"query_sql.txt";
String sql_segs=FileUtil.getStringFromFile(ssql_file_path);
String []sql_seg_arr=sql_segs.split(";");
String migrate_sql_file_dir_path="D:/workspace/demo/src/java/com/util";
String ms_str="";
for(String per_seg : sql_seg_arr)
{
if(!StringUtils.isEmpty(per_seg.replaceAll("\\r\\n", "")))
{
per_seg.indexOf("where");
String seg_from=per_seg.substring(0,per_seg.indexOf("where"));
String seg_where=per_seg.substring(per_seg.indexOf("where")+6);
String cmd = "cmd /c C:/mysqldump -h你的数据库IP -u账号 -p密码 --lock-tables=0 --compact --no-create-info --skip-comments 你的MySQL库名 ";
String tf=migrate_sql_file_dir_path+"/"+seg_from.split("from")[1].trim()+"_"+Math.round(Math.random()*10000)+".sql";
cmd=cmd+seg_from.split("from")[1].trim()+" -w\""+seg_where.replaceAll("\\r\\n", "")+"\" > "+tf;
try {
Process child = Runtime.getRuntime().exec(cmd);
int tag = child.waitFor();// 等待进程终止
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(cmd);
ms_str+=FileUtil.getStringFromFile(tf);
}
}
ms_str = ms_str.replaceAll("SET @(.+);", "");
System.out.println(ms_str);
FileUtil.wirteStringToFile(migrate_sql_file_dir_path+"/insert.sql", ms_str);
}
}package com.common.util;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
/**
文件操作实体类
*/
public class FileUtil {
/* 往文件写入字符串 */
public static void wirteStringToFile(String path, String context) {
OutputStreamWriter osw = null;
try {
File file = new File(path);
if (!file.exists()) {
file = new File(file.getParent());
if (!file.exists()) {
file.mkdirs();
}
}
osw = new OutputStreamWriter(new FileOutputStream(path), System.getProperty("file.encoding"));
osw.write(new String(context.getBytes(), System.getProperty("file.encoding")));
osw.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (osw != null) {
osw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/* 读取文件中的字符串 */
public static String getStringFromFile(String path) {
String data = null;
// 判断文件是否存在
File file = new File(path);
if (!file.exists()) {
return data;
}
// 获取文件编码格式
String code = getFileEncode(path);
InputStreamReader isr = null;
try {
// 根据编码格式解析文件
if ("asci".equals(code)) {
// 这里采用GBK编码,而不用环境编码格式,因为环境默认编码不等于操作系统编码
// code = System.getProperty("file.encoding");
code = "GBK";
}
isr = new InputStreamReader(new FileInputStream(file), code);
// 读取文件内容
int length = -1;
char[] buffer = new char[1024];
StringBuffer sb = new StringBuffer();
while ((length = isr.read(buffer, 0, 1024)) != -1) {
sb.append(buffer, 0, length);
}
data = new String(sb);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (isr != null) {
isr.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return data;
}
}
3、bat批处理文件实现数据库备份
场景:由于新上线的一个项目,开发人员没有控制好delete的删除条件,在某种情况下会导致删除表的全部数据,由于表格数据更新不频繁,因此在bug修复前,先通过每天自动备份,以免数据再次丢失。
以下是实现代码:
@echo off
rem 脚本使用配置开始=======================start
::设置数据库所在ip
set ip=数据库所在ip
::设置数据库端口
set port=数据库端口
::设置数据库连接用户(为了保证导出函数,视图,存储过程,触发器请给用户设置权限)
set user=账号
::设置数据库连接用户密码(密码中的%需要两个%%转义)
set password="密码"
::设置备份文件存储位置
set dataFolder=D:/mysql_backup
::设置压缩软件WinRAR的安装目录
set winrarPath="C:\Program Files\WinRAR"
::设置MySQL的安装目录的安装目录
set mysqlPath="D:\Program Files\MySQL\MySQL Server 5.6\bin"
::设置备份日期
set curdate=%date:~0,4%%date:~5,2%%date:~8,2%
rem 脚本使用配置结束=======================end
echo 开始备份=======
%mysqlPath%\mysqldump.exe -R -u%user% -p%password% -h%ip% -P%port% 需要备份的数据库名 > %dataFolder%/backup_%curdate%.sql
rem 压缩备份文件
::若压缩文件存在,先删除
if exist "%dataFolder%/nonauto_backup_%curdate%.rar" (
del %dataFolder%/nonauto_backup_%curdate%.rar
)
::使用WinRAR压缩文件并删除源文件
echo 开始压缩=======
%winrarPath%\Rar.exe a -k -r -s -m5 -ep1 -df %dataFolder%/nonauto_backup_%curdate%.rar %dataFolder%/backup_%curdate%.sql
echo 备份结束设置定时任务,可以参考我的另一篇博客:定时执行kettle任务