代码代写(实验报告、论文、小程序制作)服务请加微信:ppz2759
之前给大家分享了正则表达式和XPath表达式的内容,有了以上基础今天来给大家带来了网络爬虫实战课程,教大家爬取第一个网站
什么是Urllib模块
Urllib是Python提供的一个用于操作URL的模块,这个库在我们爬取网页的时候会经常用到。
Urllib实例1(将内容爬到内存中)
import urllib.request,re
#urllib.request.urlopen(链接)代表你要爬取的网站
#.read()读取网站内容
#.decode("utf-8","ignore")按照utf-8方式解码,加上ignore成功率会更高
data = urllib.request.urlopen("http://www.jd.com").read().decode("utf-8","ignore")
#这就是之前学过的正则表达式,如果不懂可以看本博客最顶部的正则表达式链接,那里有讲解
string = "<title>(.*?)</title>"
biaoti = re.compile(string,re.S).findall(data)
print(biaoti)
运行结果如下:输出了www.jd.com的标题
Urllib实例2(将内容爬到电脑硬盘中)
import urllib.request
#urllib.request.urlretrieve(网址,文件位置)将爬取到的文件保存到电脑指定的位置
urllib.request.urlretrieve("http://www.jd.com",filename="D:\\微信公众号:骄傲的程序员\\京东.html")
运行结果如下:将www.jd.com的源代码存储到了:D:\微信公众号:骄傲的程序员\京东.html中
Urllib实例3(浏览器伪装)
以上两种方法只适用于部分网站,对于一部分反爬的网站是不可以的,比如糗事百科就必须是浏览器才能爬取,直接用编辑器爬取是行不通的,所以要将自己的编辑器伪装成浏览器,才可以继续爬取内容,将编辑器伪装成浏览器其实很简单,只要将某一个浏览器的User-Agent写在自己的代码中即可。
#大家可以使用这些我搜集的User-Agent,大家也可以在浏览器中自己查找
#查找方法:F12,Network下的最后一个Request heard有一个User-Agent:后面就是
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",#360
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36",#谷歌
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0",#火狐
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0",#火狐
浏览器伪装办法:
import urllib.request,re
url = "http://www.qiushibaike.com/"
#声明一个urllib.request.build_opener()对象
opener = urllib.request.build_opener()
#以JSON格式(键值对)保存一个User-Agent
UA = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
#将User-Agent赋值给opener.addheaders
opener.addheaders=[UA]
#将urllib.request的install_opener改成咱们的
urllib.request.install_opener(opener)
#这回在爬就没毛病啦
data = urllib.request.urlopen(url).read().decode("utf-8","ignore")
string = "<title>(.*?)</title>"
biaoti = re.compile(string,re.S).findall(data)
print(biaoti)
运行结果如下:输出了www.qiushibaike.com的标题
如果按照之前的方法的话,就会出现以下错误:远程端关闭连接,无响应,说明请求被对方服务器拒绝了。
http.client.RemoteDisconnected: Remote end closed connection without response
Urllib实例4(用户代理池)
然而有的时候,浏览器会检查怎么总是这一个浏览器访问我呀,也能也会拒绝咱们的访问,所以,我们用了用户代理池的方法,就是在一个数组中保存多个User-Agent,我们叫他代理池,每次随机调用其中一个User-Agent,这样就会解决这个问题,实例如下:
import urllib.request,re,random
#创建一个用户代理池数组
uapools=[
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",#360
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36",#谷歌
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0",
]
#定义一个方法UA()
def UA():
#创建一个urllib.request.build_opener()对象
opener = urllib.request.build_opener()
#每次从uapools中随机选取一个User-Agent
thisua = random.choice(uapools)
#以JSON格式(键值对)保存一个User-Agent
ua = ("User-Agent",thisua)
#将User-Agent赋值给opener.addheaders
opener.addheaders=[ua]
#将urllib.request的install_opener改成咱们的
urllib.request.install_opener(opener)
print("当前使用User-Agent:"+str(thisua))
url = "http://www.qiushibaike.com/"
for i in range(0,10):
UA()
#这回就可以快乐的爬取网站内容啦
data = urllib.request.urlopen(url).read().decode("utf-8","ignore")
string = "<title>(.*?)</title>"
biaoti = re.compile(string,re.S).findall(data)
print(biaoti)
运行结果如下:输出了www.qiushibaike.com的标题10次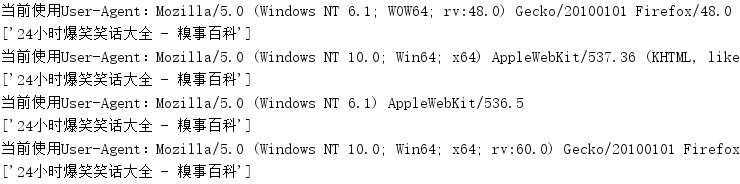
以上就是一些爬虫基础,接下来还会持续更新这篇博客,希望大家支持谢谢大家。
我还写了一篇爬虫实战(含代码),大家快来点我查看吧
版权声明:本文为xiaozhezhe0470原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。