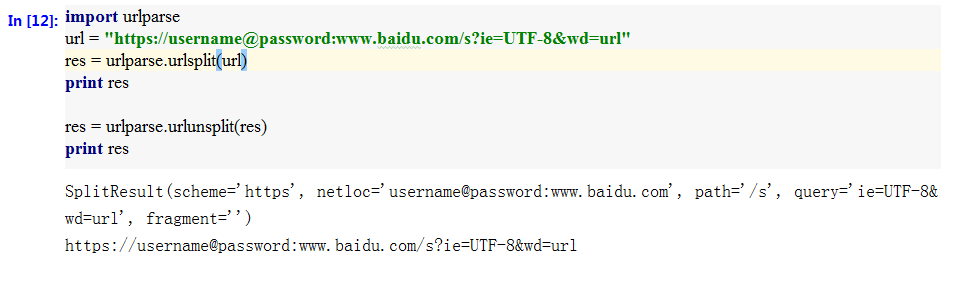
参考官方文档:https://docs.python.org/3/library/urllib.html点击打开链接 1、 完整的url语法格式: 协议://用户名@密码:子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标识 2 、urlparse模块对url的处理方法 urlparse模块对url的主要处理方法有:urljoin/urlsplit/urlunsplit/urlparse等。该模块对url的定义采用六元组的形式:schema://netloc/path;parameters?query#fragment。其中,netloc包含下表的后4个属性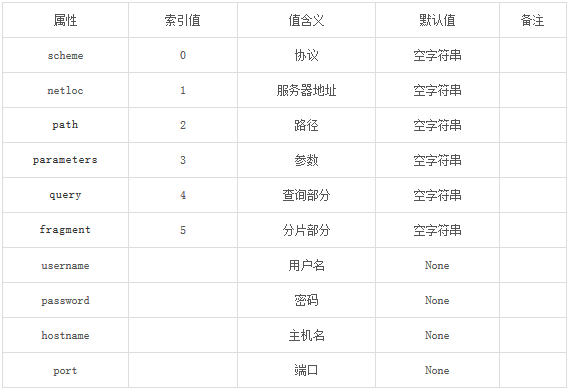
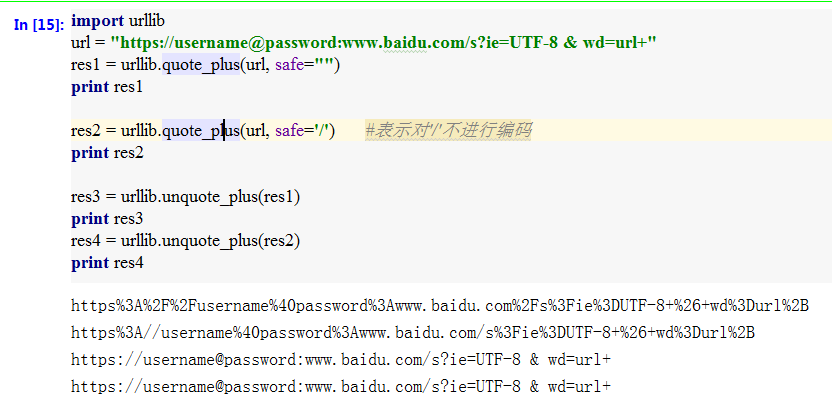
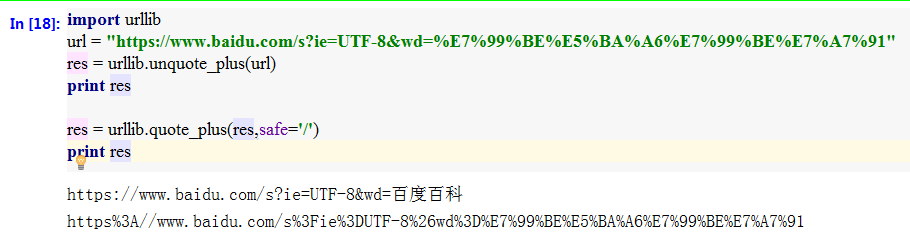
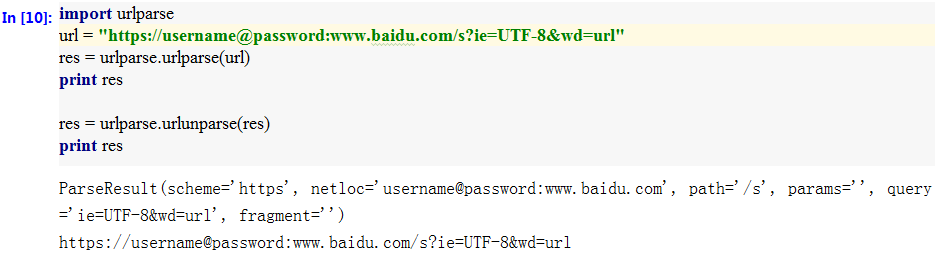
- urlparse() 利用urlparse()方法对url进行解析,返回六元组;urlunparse()对六元组进行组合
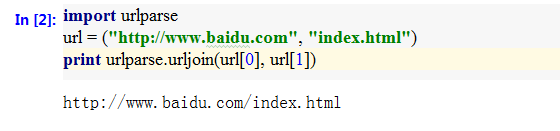
- urljoin() 利用urljoin()方法对绝对url地址与相对url地址进行拼合
>>>from urllib.parse import urljoin
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "anotherpage.html")
'http://www.chachabei.com/folder/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/anotherpage.html")
'http://www.chachabei.com/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "folder2/anotherpage.html")
'http://www.chachabei.com/folder/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "../anotherpage.html")
'http://www.chachabei.com/abc/anotherpage.html'- urlsplit() 利用urlsplit()方法可以对URL进行分解;与urlparse()相比,urlsplit()函数返回一个五元组,没有parameter参数。 相应的,urlunsplit()方法可以对urlsplit()分解的五元组进行合并。两种方法组合在一起,可以对URL进行有效地格式化,特殊字符在此过程中得到转换。