Redis的数据类型及其底层数据结构
Redis有五种基本的数类型,而这五种基本的数据类型又是基于六种底层的数据结构实现的。
五种数据类型来表示键值对,而键值对创建时会创建两种对象,一种适合K对象一种是V对象。而且Redis中的对象都是用redisObject表示的:
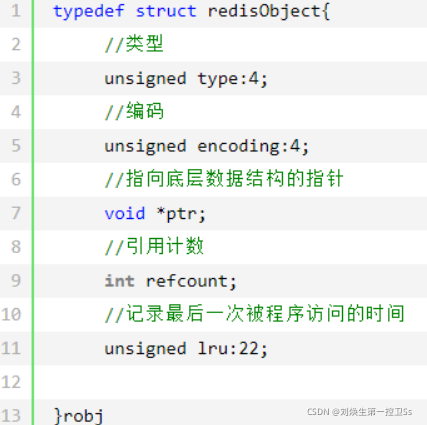
redisObject一共有五个属性,下面我们来解释一下这五个属性的作用。
type
他表示的就是对象所对应的数据类型,当我们使用 type K 时就会显示对应 K 的数据类型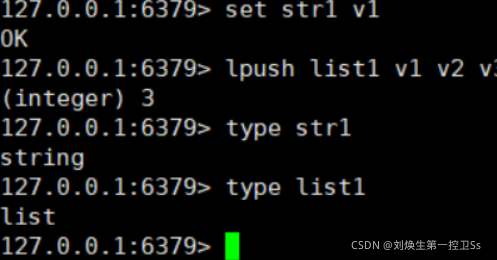
encoding和*prt
*prt他指向的对象的底层的数据结构,而对象底层的数据结构结构是由encoding决定的。
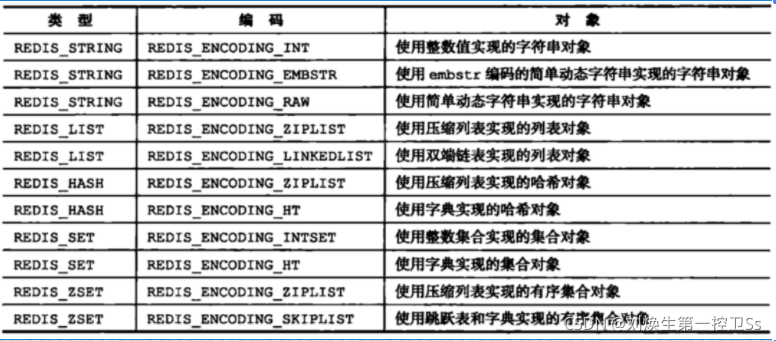
每种数据类型对应着几种编码类型
OBJECT ENCODING key 命令用来查看对象的底层编码类型
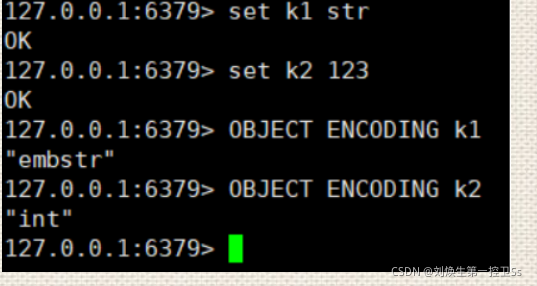
STRING
INT用来存储整数。
EMBSTR用来存储短字符串(小于44字节的,Redis3.2时是39字节)。
RAW用来存储长的字符串。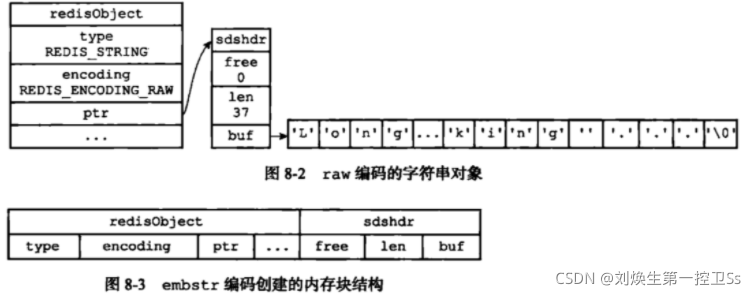
RAW的内存分配是两次分配的,而EMBSTR是一次分配的且是连续的。
EMBSTR
优点:创建时只分配一次内存,删除时也是。
缺点:因为只分配一次内存所以,RedisObject和EMBSTR是连接在一起的,分配的内存不够时他们来那个都需要修改,所以他是只读的。
EMBSTR的修改:EMBSTR时只读的他修改时会转换成RAW。
LIST
ZIPLIST和LINKLIST两个底层实现方式。
ZIPLIST的元素存储是连续的节省内存。
LINKLIST是一个双向链表,
转换条件
元素数量小于512个,元素长度小于64字节时,用的是ZIP。
redis.conf 配置文件中的 list-max-ziplist-value
list-max-ziplist-entries
HASH
ZIPHASH和HT(字典)
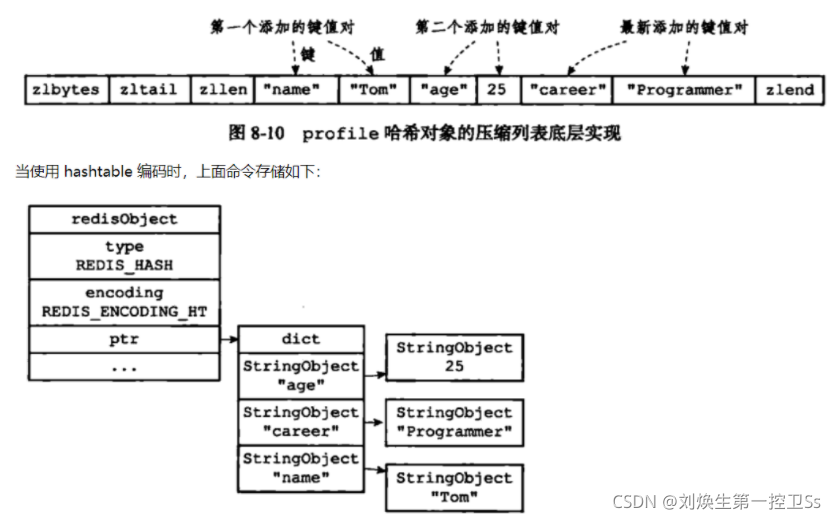
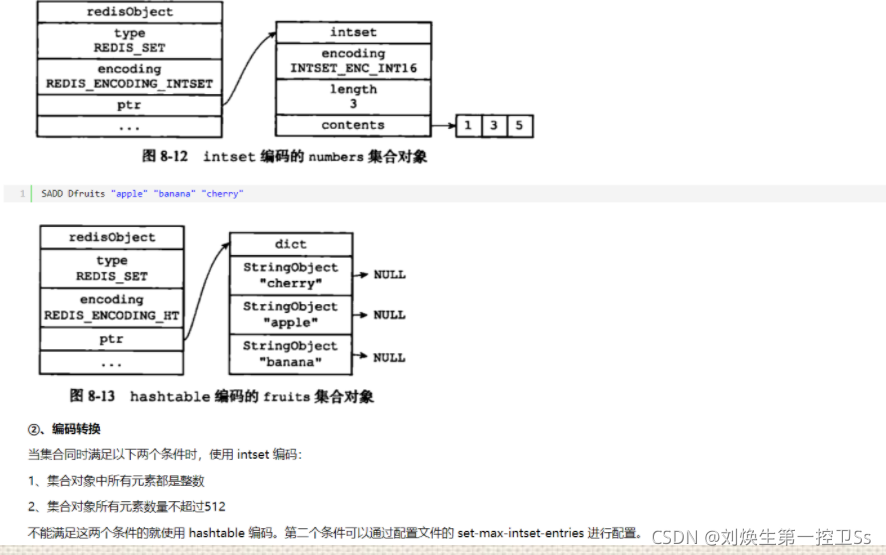
元素数量小于512,且长度小于64字节时使用的ZIP。set-max-intset-entries。
SET
ZSET
ZIPSET和SKIPLIST实现
ZIP底层是连续的,并且是有顺序的从左至右,依次增大。
SKIPLIST是用set和跳跃表的结构实现的,他们两个任意一种都可以实现zset但是用他们两个就是因为,set查找元素是O(1),但是他不能范围查找,跳跃表可以范围查找,但是跳跃表的查找不是O(1)是O(logN)。
他们两个的使用也可以修改,
小于128个,64字节时使用的ziplist,
zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
refcount
垃圾回收的时候用的,对象别使用的时就加一,不用就减一,但是会出现循环引用的问题。
循环应用问题的解决:内存淘汰策略(maxmemory-policy)
random-allkeys
random-volatile
lru-allkeys
lru-volatile
ttl-allkeys
noeviction
共享内存
set k1 100
set k2 100
使用的同一值,但是不得数据类型不可以,因为判断两个值相等相比整数的话效率太慢,
lru(对象空转时长)
内存淘汰策略用到了,他记录的是对象被最后一次访问的时间。
OBJECT IDLETIME 命令可以查看